 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTreePS-RAG: Tree-based Process Supervision for Reinforcement Learning in Agentic RAG
Jan 11, 2026Agentic retrieval-augmented generation (RAG) formulates question answering as a multi-step interaction between reasoning and information retrieval, and has recently been advanced by reinforcement learning (RL) with outcome-based supervision. While effective, relying solely on sparse final rewards limits step-wise credit assignment and provides weak guidance for intermediate reasoning and actions. Recent efforts explore process-level supervision, but typically depend on offline constructed training data, which risks distribution shift, or require costly intermediate annotations. We present TreePS-RAG, an online, tree-based RL framework for agentic RAG that enables step-wise credit assignment while retaining standard outcome-only rewards. Our key insight is to model agentic RAG reasoning as a rollout tree, where each reasoning step naturally maps to a node. This tree structure allows step utility to be estimated via Monte Carlo estimation over its descendant outcomes, yielding fine-grained process advantages without requiring intermediate labels. To make this paradigm practical, we introduce an efficient online tree construction strategy that preserves exploration diversity under a constrained computational budget. With a rollout cost comparable to strong baselines like Search-R1, experiments on seven multi-hop and general QA benchmarks across multiple model scales show that TreePS-RAG consistently and significantly outperforms both outcome-supervised and leading process-supervised RL methods.
Beyond Context Limits: Subconscious Threads for Long-Horizon Reasoning
Jul 22, 2025To break the context limits of large language models (LLMs) that bottleneck reasoning accuracy and efficiency, we propose the Thread Inference Model (TIM), a family of LLMs trained for recursive and decompositional problem solving, and TIMRUN, an inference runtime enabling long-horizon structured reasoning beyond context limits. Together, TIM hosted on TIMRUN supports virtually unlimited working memory and multi-hop tool calls within a single language model inference, overcoming output limits, positional-embedding constraints, and GPU-memory bottlenecks. Performance is achieved by modeling natural language as reasoning trees measured by both length and depth instead of linear sequences. The reasoning trees consist of tasks with thoughts, recursive subtasks, and conclusions based on the concept we proposed in Schroeder et al, 2025. During generation, we maintain a working memory that retains only the key-value states of the most relevant context tokens, selected by a rule-based subtask-pruning mechanism, enabling reuse of positional embeddings and GPU memory pages throughout reasoning. Experimental results show that our system sustains high inference throughput, even when manipulating up to 90% of the KV cache in GPU memory. It also delivers accurate reasoning on mathematical tasks and handles information retrieval challenges that require long-horizon reasoning and multi-hop tool use.
RAG-Zeval: Towards Robust and Interpretable Evaluation on RAG Responses through End-to-End Rule-Guided Reasoning
May 28, 2025



Robust evaluation is critical for deploying trustworthy retrieval-augmented generation (RAG) systems. However, current LLM-based evaluation frameworks predominantly rely on directly prompting resource-intensive models with complex multi-stage prompts, underutilizing models' reasoning capabilities and introducing significant computational cost. In this paper, we present RAG-Zeval (RAG-Zero Evaluator), a novel end-to-end framework that formulates faithfulness and correctness evaluation as a rule-guided reasoning task. Our approach trains evaluators with reinforcement learning, facilitating compact models to generate comprehensive and sound assessments with detailed explanation in one-pass. We introduce a ranking-based outcome reward mechanism, using preference judgments rather than absolute scores, to address the challenge of obtaining precise pointwise reward signals. To this end, we synthesize the ranking references by generating quality-controlled responses with zero human annotation. Experiments demonstrate RAG-Zeval's superior performance, achieving the strongest correlation with human judgments and outperforming baselines that rely on LLMs with 10-100 times more parameters. Our approach also exhibits superior interpretability in response evaluation.
Instructify: Demystifying Metadata to Visual Instruction Tuning Data Conversion
May 23, 2025Visual Instruction Tuning (VisIT) data, commonly available as human-assistant conversations with images interleaved in the human turns, are currently the most widespread vehicle for aligning strong LLMs to understand visual inputs, converting them to strong LMMs. While many VisIT datasets are available, most are constructed using ad-hoc techniques developed independently by different groups. They are often poorly documented, lack reproducible code, and rely on paid, closed-source model APIs such as GPT-4, Gemini, or Claude to convert image metadata (labels) into VisIT instructions. This leads to high costs and makes it challenging to scale, enhance quality, or generate VisIT data for new datasets. In this work, we address these challenges and propose an open and unified recipe and approach,~\textbf{\method}, for converting available metadata to VisIT instructions using open LLMs. Our multi-stage \method features an efficient framework for metadata grouping, quality control, data and prompt organization, and conversation sampling. We show that our approach can reproduce or enhance the data quality of available VisIT datasets when applied to the same image data and metadata sources, improving GPT-4 generated VisIT instructions by ~3\% on average and up to 12\% on individual benchmarks using open models, such as Gemma 2 27B and LLaMa 3.1 70B. Additionally, our approach enables effective performance scaling - both in quantity and quality - by enhancing the resulting LMM performance across a wide range of benchmarks. We also analyze the impact of various factors, including conversation format, base model selection, and resampling strategies. Our code, which supports the reproduction of equal or higher-quality VisIT datasets and facilities future metadata-to-VisIT data conversion for niche domains, is released at https://github.com/jacob-hansen/Instructify.
Generate, Discriminate, Evolve: Enhancing Context Faithfulness via Fine-Grained Sentence-Level Self-Evolution
Mar 03, 2025



Improving context faithfulness in large language models is essential for developing trustworthy retrieval augmented generation systems and mitigating hallucinations, especially in long-form question answering (LFQA) tasks or scenarios involving knowledge conflicts. Existing methods either intervene LLMs only at inference without addressing their inherent limitations or overlook the potential for self-improvement. In this paper, we introduce GenDiE (Generate, Discriminate, Evolve), a novel self-evolving framework that enhances context faithfulness through fine-grained sentence-level optimization. GenDiE combines both generative and discriminative training, equipping LLMs with self-generation and self-scoring capabilities to facilitate iterative self-evolution. This supports both data construction for model alignment and score-guided search during inference. Furthermore, by treating each sentence in a response as an independent optimization unit, GenDiE effectively addresses the limitations of previous approaches that optimize at the holistic answer level, which may miss unfaithful details. Experiments on ASQA (in-domain LFQA) and ConFiQA (out-of-domain counterfactual QA) datasets demonstrate that GenDiE surpasses various baselines in both faithfulness and correctness, and exhibits robust performance for domain adaptation.
Decoding on Graphs: Faithful and Sound Reasoning on Knowledge Graphs through Generation of Well-Formed Chains
Oct 24, 2024



Knowledge Graphs (KGs) can serve as reliable knowledge sources for question answering (QA) due to their structured representation of knowledge. Existing research on the utilization of KG for large language models (LLMs) prevalently relies on subgraph retriever or iterative prompting, overlooking the potential synergy of LLMs' step-wise reasoning capabilities and KGs' structural nature. In this paper, we present DoG (Decoding on Graphs), a novel framework that facilitates a deep synergy between LLMs and KGs. We first define a concept, well-formed chain, which consists of a sequence of interrelated fact triplets on the KGs, starting from question entities and leading to answers. We argue that this concept can serve as a principle for making faithful and sound reasoning for KGQA. To enable LLMs to generate well-formed chains, we propose graph-aware constrained decoding, in which a constraint derived from the topology of the KG regulates the decoding process of the LLMs. This constrained decoding method ensures the generation of well-formed chains while making full use of the step-wise reasoning capabilities of LLMs. Based on the above, DoG, a training-free approach, is able to provide faithful and sound reasoning trajectories grounded on the KGs. Experiments across various KGQA tasks with different background KGs demonstrate that DoG achieves superior and robust performance. DoG also shows general applicability with various open-source LLMs.
Quantifying Generalization Complexity for Large Language Models
Oct 02, 2024While large language models (LLMs) have shown exceptional capabilities in understanding complex queries and performing sophisticated tasks, their generalization abilities are often deeply entangled with memorization, necessitating more precise evaluation. To address this challenge, we introduce Scylla, a dynamic evaluation framework that quantitatively measures the generalization abilities of LLMs. Scylla disentangles generalization from memorization via assessing model performance on both in-distribution (ID) and out-of-distribution (OOD) data through 20 tasks across 5 levels of complexity. Through extensive experiments, we uncover a non-monotonic relationship between task complexity and the performance gap between ID and OOD data, which we term the generalization valley. Specifically, this phenomenon reveals a critical threshold - referred to as critical complexity - where reliance on non-generalizable behavior peaks, indicating the upper bound of LLMs' generalization capabilities. As model size increases, the critical complexity shifts toward higher levels of task complexity, suggesting that larger models can handle more complex reasoning tasks before over-relying on memorization. Leveraging Scylla and the concept of critical complexity, we benchmark 28LLMs including both open-sourced models such as LLaMA and Qwen families, and close-sourced models like Claude and GPT, providing a more robust evaluation and establishing a clearer understanding of LLMs' generalization capabilities.
Addition is All You Need for Energy-efficient Language Models
Oct 02, 2024
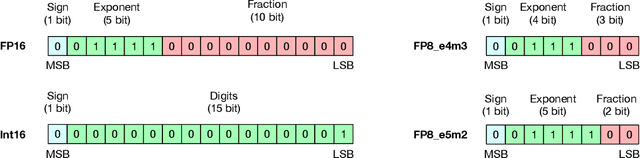


Large neural networks spend most computation on floating point tensor multiplications. In this work, we find that a floating point multiplier can be approximated by one integer adder with high precision. We propose the linear-complexity multiplication L-Mul algorithm that approximates floating point number multiplication with integer addition operations. The new algorithm costs significantly less computation resource than 8-bit floating point multiplication but achieves higher precision. Compared to 8-bit floating point multiplications, the proposed method achieves higher precision but consumes significantly less bit-level computation. Since multiplying floating point numbers requires substantially higher energy compared to integer addition operations, applying the L-Mul operation in tensor processing hardware can potentially reduce 95% energy cost by element-wise floating point tensor multiplications and 80% energy cost of dot products. We calculated the theoretical error expectation of L-Mul, and evaluated the algorithm on a wide range of textual, visual, and symbolic tasks, including natural language understanding, structural reasoning, mathematics, and commonsense question answering. Our numerical analysis experiments agree with the theoretical error estimation, which indicates that L-Mul with 4-bit mantissa achieves comparable precision as float8_e4m3 multiplications, and L-Mul with 3-bit mantissa outperforms float8_e5m2. Evaluation results on popular benchmarks show that directly applying L-Mul to the attention mechanism is almost lossless. We further show that replacing all floating point multiplications with 3-bit mantissa L-Mul in a transformer model achieves equivalent precision as using float8_e4m3 as accumulation precision in both fine-tuning and inference.
Training Task Experts through Retrieval Based Distillation
Jul 07, 2024



One of the most reliable ways to create deployable models for specialized tasks is to obtain an adequate amount of high-quality task-specific data. However, for specialized tasks, often such datasets do not exist. Existing methods address this by creating such data from large language models (LLMs) and then distilling such knowledge into smaller models. However, these methods are limited by the quality of the LLMs output, and tend to generate repetitive or incorrect data. In this work, we present Retrieval Based Distillation (ReBase), a method that first retrieves data from rich online sources and then transforms them into domain-specific data. This method greatly enhances data diversity. Moreover, ReBase generates Chain-of-Thought reasoning and distills the reasoning capacity of LLMs. We test our method on 4 benchmarks and results show that our method significantly improves performance by up to 7.8% on SQuAD, 1.37% on MNLI, and 1.94% on BigBench-Hard.
Self-MoE: Towards Compositional Large Language Models with Self-Specialized Experts
Jun 17, 2024We present Self-MoE, an approach that transforms a monolithic LLM into a compositional, modular system of self-specialized experts, named MiXSE (MiXture of Self-specialized Experts). Our approach leverages self-specialization, which constructs expert modules using self-generated synthetic data, each equipped with a shared base LLM and incorporating self-optimized routing. This allows for dynamic and capability-specific handling of various target tasks, enhancing overall capabilities, without extensive human-labeled data and added parameters. Our empirical results reveal that specializing LLMs may exhibit potential trade-offs in performances on non-specialized tasks. On the other hand, our Self-MoE demonstrates substantial improvements over the base LLM across diverse benchmarks such as knowledge, reasoning, math, and coding. It also consistently outperforms other methods, including instance merging and weight merging, while offering better flexibility and interpretability by design with semantic experts and routing. Our findings highlight the critical role of modularity and the potential of self-improvement in achieving efficient, scalable, and adaptable systems.