 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstructify: Demystifying Metadata to Visual Instruction Tuning Data Conversion
May 23, 2025Visual Instruction Tuning (VisIT) data, commonly available as human-assistant conversations with images interleaved in the human turns, are currently the most widespread vehicle for aligning strong LLMs to understand visual inputs, converting them to strong LMMs. While many VisIT datasets are available, most are constructed using ad-hoc techniques developed independently by different groups. They are often poorly documented, lack reproducible code, and rely on paid, closed-source model APIs such as GPT-4, Gemini, or Claude to convert image metadata (labels) into VisIT instructions. This leads to high costs and makes it challenging to scale, enhance quality, or generate VisIT data for new datasets. In this work, we address these challenges and propose an open and unified recipe and approach,~\textbf{\method}, for converting available metadata to VisIT instructions using open LLMs. Our multi-stage \method features an efficient framework for metadata grouping, quality control, data and prompt organization, and conversation sampling. We show that our approach can reproduce or enhance the data quality of available VisIT datasets when applied to the same image data and metadata sources, improving GPT-4 generated VisIT instructions by ~3\% on average and up to 12\% on individual benchmarks using open models, such as Gemma 2 27B and LLaMa 3.1 70B. Additionally, our approach enables effective performance scaling - both in quantity and quality - by enhancing the resulting LMM performance across a wide range of benchmarks. We also analyze the impact of various factors, including conversation format, base model selection, and resampling strategies. Our code, which supports the reproduction of equal or higher-quality VisIT datasets and facilities future metadata-to-VisIT data conversion for niche domains, is released at https://github.com/jacob-hansen/Instructify.
Seeing the Forest for the Trees: A Large Scale, Continuously Updating Meta-Analysis of Frontier LLMs
Feb 26, 2025The surge of LLM studies makes synthesizing their findings challenging. Meta-analysis can uncover important trends across studies, but its use is limited by the time-consuming nature of manual data extraction. Our study presents a semi-automated approach for meta-analysis that accelerates data extraction using LLMs. It automatically identifies relevant arXiv papers, extracts experimental results and related attributes, and organizes them into a structured dataset. We conduct a comprehensive meta-analysis of frontier LLMs using an automatically extracted dataset, reducing the effort of paper surveying and data extraction by more than 93\% compared to manual approaches. We validate our dataset by showing that it reproduces key findings from a recent manual meta-analysis about Chain-of-Thought (CoT), and also uncovers new insights that go beyond it, showing for example that in-context examples benefit multimodal tasks but offer limited gains in mathematical tasks compared to CoT. Our automatically updatable dataset enables continuous tracking of target models by extracting evaluation studies as new data becomes available. Through our scientific artifacts and empirical analysis, we provide novel insights into LLMs while facilitating ongoing meta-analyses of their behavior.
Self-MoE: Towards Compositional Large Language Models with Self-Specialized Experts
Jun 17, 2024We present Self-MoE, an approach that transforms a monolithic LLM into a compositional, modular system of self-specialized experts, named MiXSE (MiXture of Self-specialized Experts). Our approach leverages self-specialization, which constructs expert modules using self-generated synthetic data, each equipped with a shared base LLM and incorporating self-optimized routing. This allows for dynamic and capability-specific handling of various target tasks, enhancing overall capabilities, without extensive human-labeled data and added parameters. Our empirical results reveal that specializing LLMs may exhibit potential trade-offs in performances on non-specialized tasks. On the other hand, our Self-MoE demonstrates substantial improvements over the base LLM across diverse benchmarks such as knowledge, reasoning, math, and coding. It also consistently outperforms other methods, including instance merging and weight merging, while offering better flexibility and interpretability by design with semantic experts and routing. Our findings highlight the critical role of modularity and the potential of self-improvement in achieving efficient, scalable, and adaptable systems.
Self-Specialization: Uncovering Latent Expertise within Large Language Models
Sep 29, 2023



Recent works have demonstrated the effectiveness of self-alignment in which a large language model is, by itself, aligned to follow general instructions through the automatic generation of instructional data using a handful of human-written seeds. Instead of general alignment, in this work, we focus on self-alignment for expert domain specialization (e.g., biomedicine), discovering it to be very effective for improving zero-shot and few-shot performance in target domains of interest. As a preliminary, we first present the benchmark results of existing aligned models within a specialized domain, which reveals the marginal effect that "generic" instruction-following training has on downstream expert domains' performance. To remedy this, we explore self-specialization that leverages domain-specific unlabelled data and a few labeled seeds for the self-alignment process. When augmented with retrieval to reduce hallucination and enhance concurrency of the alignment, self-specialization offers an effective (and efficient) way of "carving out" an expert model out of a "generalist", pre-trained LLM where different domains of expertise are originally combined in a form of "superposition". Our experimental results on a biomedical domain show that our self-specialized model (30B) outperforms its base model, MPT-30B by a large margin and even surpasses larger popular models based on LLaMA-65B, highlighting its potential and practicality for specialization, especially considering its efficiency in terms of data and parameters.
Schema-Driven Information Extraction from Heterogeneous Tables
May 23, 2023In this paper, we explore the question of whether language models (LLMs) can support cost-efficient information extraction from complex tables. We introduce schema-driven information extraction, a new task that uses LLMs to transform tabular data into structured records following a human-authored schema. To assess various LLM's capabilities on this task, we develop a benchmark composed of tables from three diverse domains: machine learning papers, chemistry tables, and webpages. Accompanying the benchmark, we present InstrucTE, a table extraction method based on instruction-tuned LLMs. This method necessitates only a human-constructed extraction schema, and incorporates an error-recovery strategy. Notably, InstrucTE demonstrates competitive performance without task-specific labels, achieving an F1 score ranging from 72.3 to 95.7. Moreover, we validate the feasibility of distilling more compact table extraction models to minimize extraction costs and reduce API reliance. This study paves the way for the future development of instruction-following models for cost-efficient table extraction.
Distill or Annotate? Cost-Efficient Fine-Tuning of Compact Models
May 03, 2023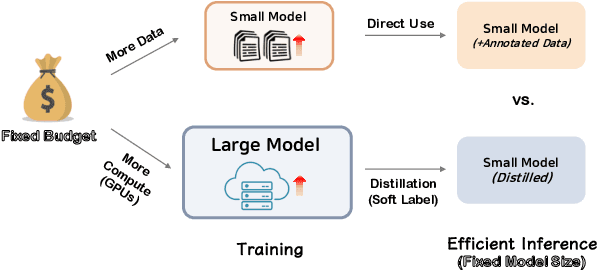



Fine-tuning large models is highly effective, however, inference using these models can be expensive and produces carbon emissions. Knowledge distillation has been shown to be a practical solution to reduce inference costs, but the distillation process itself requires significant computational resources. Rather than buying or renting GPUs to fine-tune, then distill a large model, an NLP practitioner who needs a compact model might also choose to simply allocate an available budget to hire annotators and manually label additional fine-tuning data. In this paper, we investigate how to most efficiently use a fixed budget to build a compact model. Through our extensive experiments on six diverse NLP tasks, we find that distilling from T5-XXL (11B) to T5-Small (60M) leads to almost always a cost-efficient option compared to annotating more data to directly train a compact model (T5-Small (60M)). We further demonstrate that the optimal amount of distillation that maximizes utility varies across different budgetary scenarios.
Discern and Answer: Mitigating the Impact of Misinformation in Retrieval-Augmented Models with Discriminators
May 02, 2023Most existing retrieval-augmented language models (LMs) for question answering assume all retrieved information is factually correct. In this work, we study a more realistic scenario in which retrieved documents may contain misinformation, causing conflicts among them. We observe that the existing models are highly brittle to such information in both fine-tuning and in-context few-shot learning settings. We propose approaches to make retrieval-augmented LMs robust to misinformation by explicitly fine-tuning a discriminator or prompting to elicit discrimination capability in GPT-3. Our empirical results on open-domain question answering show that these approaches significantly improve LMs' robustness to knowledge conflicts. We also provide our findings on interleaving the fine-tuned model's decision with the in-context learning process, paving a new path to leverage the best of both worlds.
Maximizing Efficiency of Language Model Pre-training for Learning Representation
Oct 13, 2021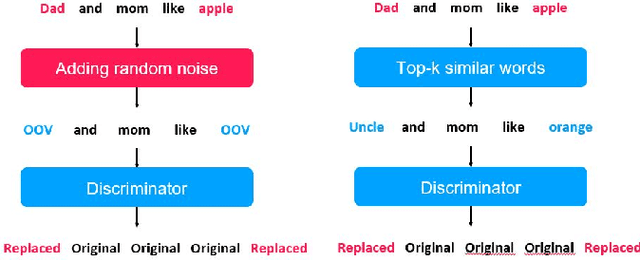
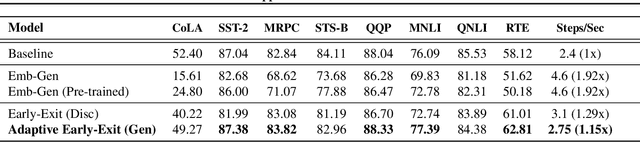
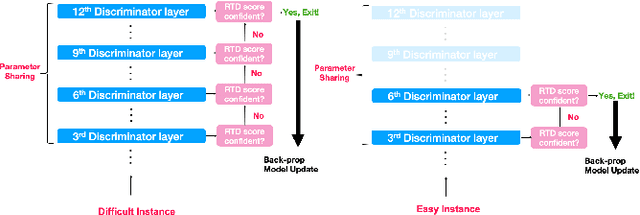
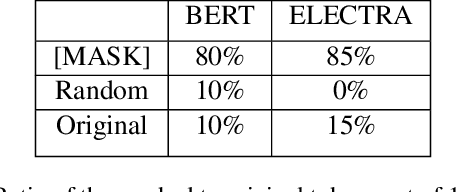
Pre-trained language models in the past years have shown exponential growth in model parameters and compute time. ELECTRA is a novel approach for improving the compute efficiency of pre-trained language models (e.g. BERT) based on masked language modeling (MLM) by addressing the sample inefficiency problem with the replaced token detection (RTD) task. Our work proposes adaptive early exit strategy to maximize the efficiency of the pre-training process by relieving the model's subsequent layers of the need to process latent features by leveraging earlier layer representations. Moreover, we evaluate an initial approach to the problem that has not succeeded in maintaining the accuracy of the model while showing a promising compute efficiency by thoroughly investigating the necessity of the generator module of ELECTRA.
UHD-BERT: Bucketed Ultra-High Dimensional Sparse Representations for Full Ranking
Apr 15, 2021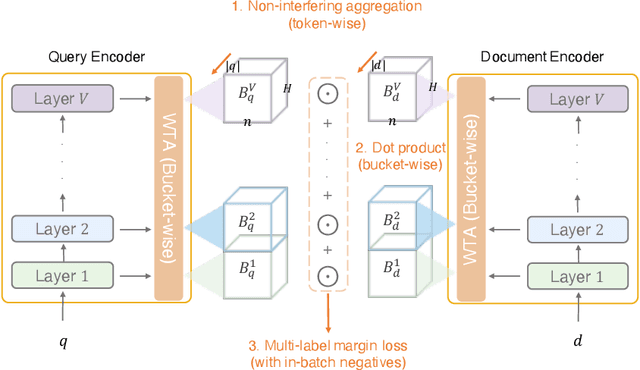
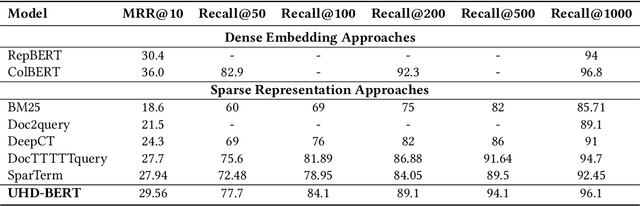
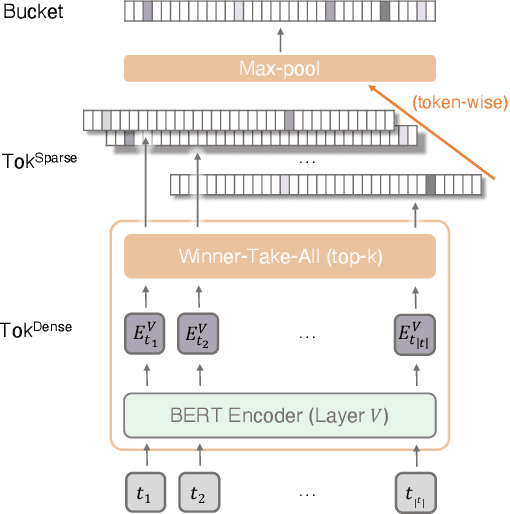

Neural information retrieval (IR) models are promising mainly because their semantic matching capabilities can ameliorate the well-known synonymy and polysemy problems of word-based symbolic approaches. However, the power of neural models' dense representations comes at the cost of inefficiency, limiting it to be used as a re-ranker. Sparse representations, on the other hand, can help enhance symbolic or latent-term representations and yet take advantage of an inverted index for efficiency, being amenable to symbolic IR techniques that have been around for decades. In order to transcend the trade-off between sparse representations (symbolic or latent-term based) and dense representations, we propose an ultra-high dimensional (UHD) representation scheme equipped with directly controllable sparsity. With the high dimensionality, we attempt to make the meaning of each dimension less entangled and polysemous than dense embeddings. The sparsity allows for not only efficiency for vector calculations but also the possibility of making individual dimensions attributable to interpretable concepts. Our model, UHD-BERT, maximizes the benefits of ultra-high dimensional (UHD) sparse representations based on BERT language modeling, by adopting a bucketing method. With this method, different segments of an embedding (horizontal buckets) or the embeddings from multiple layers of BERT (vertical buckets) can be selected and merged so that diverse linguistic aspects can be represented. An additional and important benefit of our highly disentangled (high-dimensional) and efficient (sparse) representations is that this neural approach can be harmonized with well-studied symbolic IR techniques (e.g., inverted index, pseudo-relevance feedback, BM25), enabling us to build a powerful and efficient neuro-symbolic information retrieval system.
A Sequence-Oblivious Generation Method for Context-Aware Hashtag Recommendation
Dec 05, 2020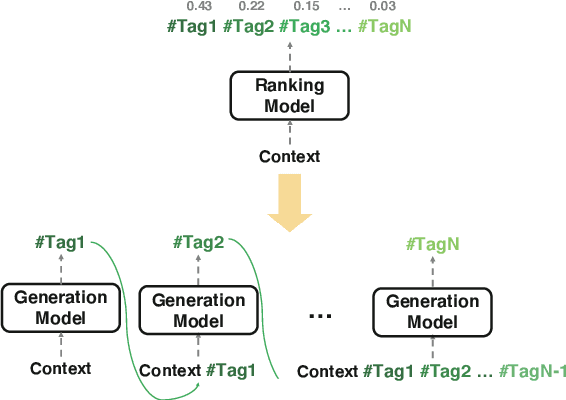
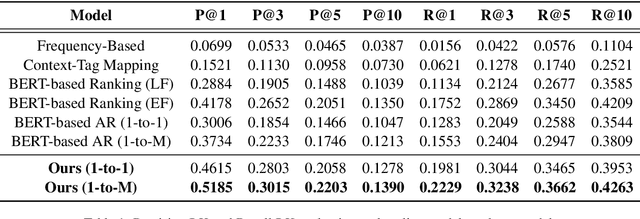
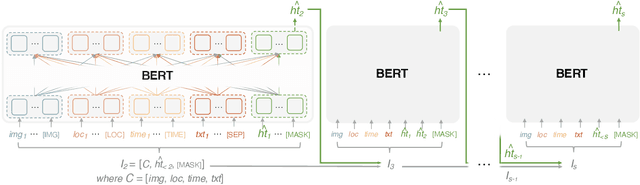
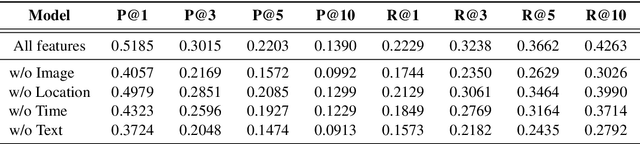
Like search, a recommendation task accepts an input query or cue and provides desirable items, often based on a ranking function. Such a ranking approach rarely considers explicit dependency among the recommended items. In this work, we propose a generative approach to tag recommendation, where semantic tags are selected one at a time conditioned on the previously generated tags to model inter-dependency among the generated tags. We apply this tag recommendation approach to an Instagram data set where an array of context feature types (image, location, time, and text) are available for posts. To exploit the inter-dependency among the distinct types of features, we adopt a simple yet effective architecture using self-attention, making deep interactions possible. Empirical results show that our method is significantly superior to not only the usual ranking schemes but also autoregressive models for tag recommendation. They indicate that it is critical to fuse mutually supporting features at an early stage to induce extensive and comprehensive view on inter-context interaction in generating tags in a recurrent feedback loop.