 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistill or Annotate? Cost-Efficient Fine-Tuning of Compact Models
Paper and Code
May 03, 2023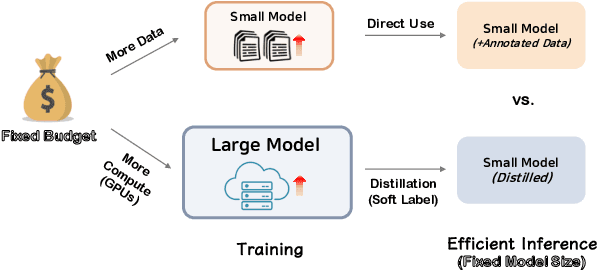



Fine-tuning large models is highly effective, however, inference using these models can be expensive and produces carbon emissions. Knowledge distillation has been shown to be a practical solution to reduce inference costs, but the distillation process itself requires significant computational resources. Rather than buying or renting GPUs to fine-tune, then distill a large model, an NLP practitioner who needs a compact model might also choose to simply allocate an available budget to hire annotators and manually label additional fine-tuning data. In this paper, we investigate how to most efficiently use a fixed budget to build a compact model. Through our extensive experiments on six diverse NLP tasks, we find that distilling from T5-XXL (11B) to T5-Small (60M) leads to almost always a cost-efficient option compared to annotating more data to directly train a compact model (T5-Small (60M)). We further demonstrate that the optimal amount of distillation that maximizes utility varies across different budgetary scenarios.