 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximizing Efficiency of Language Model Pre-training for Learning Representation
Oct 13, 2021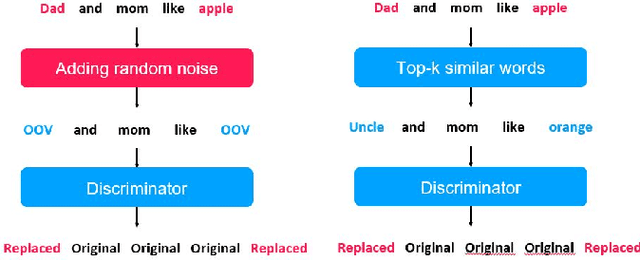
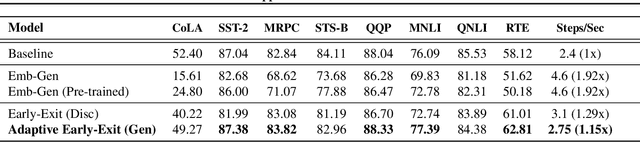
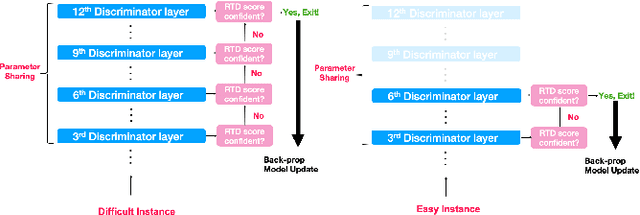
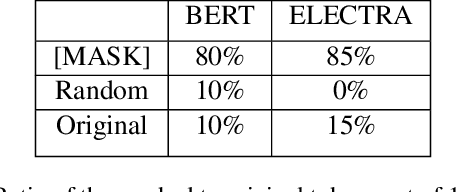
Pre-trained language models in the past years have shown exponential growth in model parameters and compute time. ELECTRA is a novel approach for improving the compute efficiency of pre-trained language models (e.g. BERT) based on masked language modeling (MLM) by addressing the sample inefficiency problem with the replaced token detection (RTD) task. Our work proposes adaptive early exit strategy to maximize the efficiency of the pre-training process by relieving the model's subsequent layers of the need to process latent features by leveraging earlier layer representations. Moreover, we evaluate an initial approach to the problem that has not succeeded in maintaining the accuracy of the model while showing a promising compute efficiency by thoroughly investigating the necessity of the generator module of ELECTRA.
Constructing Multi-Modal Dialogue Dataset by Replacing Text with Semantically Relevant Images
Jul 19, 2021
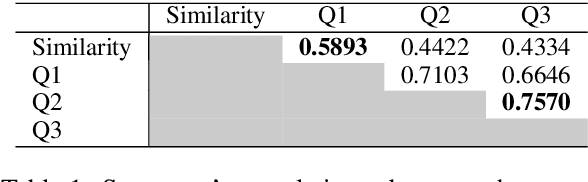
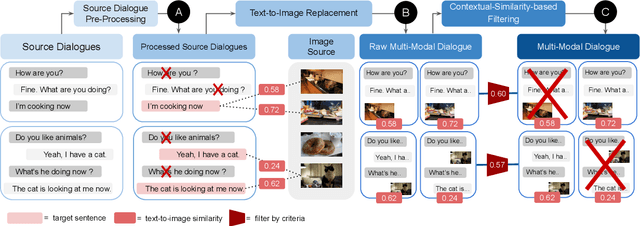
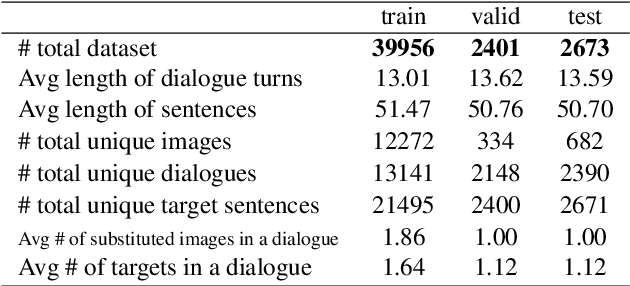
In multi-modal dialogue systems, it is important to allow the use of images as part of a multi-turn conversation. Training such dialogue systems generally requires a large-scale dataset consisting of multi-turn dialogues that involve images, but such datasets rarely exist. In response, this paper proposes a 45k multi-modal dialogue dataset created with minimal human intervention. Our method to create such a dataset consists of (1) preparing and pre-processing text dialogue datasets, (2) creating image-mixed dialogues by using a text-to-image replacement technique, and (3) employing a contextual-similarity-based filtering step to ensure the contextual coherence of the dataset. To evaluate the validity of our dataset, we devise a simple retrieval model for dialogue sentence prediction tasks. Automatic metrics and human evaluation results on such tasks show that our dataset can be effectively used as training data for multi-modal dialogue systems which require an understanding of images and text in a context-aware manner. Our dataset and generation code is available at https://github.com/shh1574/multi-modal-dialogue-dataset.
A Sequence-Oblivious Generation Method for Context-Aware Hashtag Recommendation
Dec 05, 2020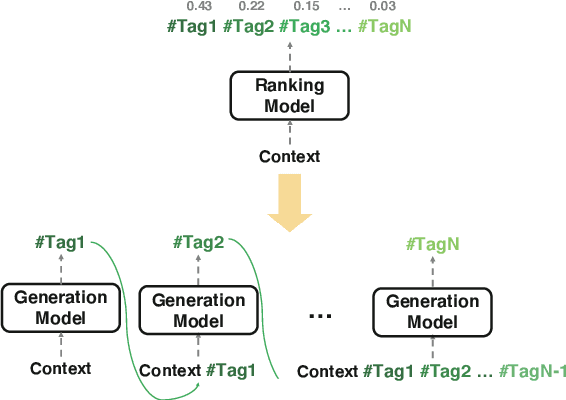
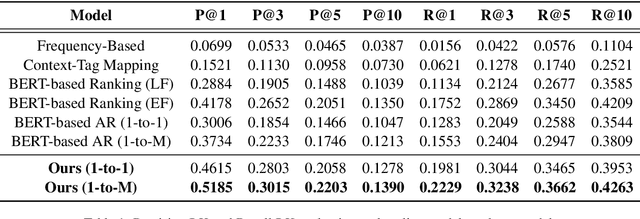
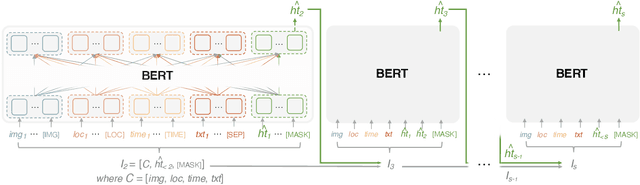
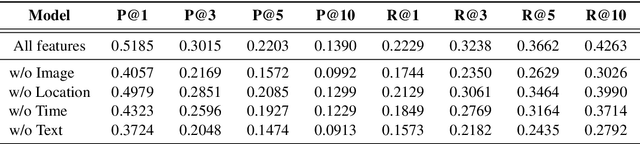
Like search, a recommendation task accepts an input query or cue and provides desirable items, often based on a ranking function. Such a ranking approach rarely considers explicit dependency among the recommended items. In this work, we propose a generative approach to tag recommendation, where semantic tags are selected one at a time conditioned on the previously generated tags to model inter-dependency among the generated tags. We apply this tag recommendation approach to an Instagram data set where an array of context feature types (image, location, time, and text) are available for posts. To exploit the inter-dependency among the distinct types of features, we adopt a simple yet effective architecture using self-attention, making deep interactions possible. Empirical results show that our method is significantly superior to not only the usual ranking schemes but also autoregressive models for tag recommendation. They indicate that it is critical to fuse mutually supporting features at an early stage to induce extensive and comprehensive view on inter-context interaction in generating tags in a recurrent feedback loop.