 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePneg: Prompt-based Negative Response Generation for Dialogue Response Selection Task
Oct 31, 2022In retrieval-based dialogue systems, a response selection model acts as a ranker to select the most appropriate response among several candidates. However, such selection models tend to rely on context-response content similarity, which makes models vulnerable to adversarial responses that are semantically similar but not relevant to the dialogue context. Recent studies have shown that leveraging these adversarial responses as negative training samples is useful for improving the discriminating power of the selection model. Nevertheless, collecting human-written adversarial responses is expensive, and existing synthesizing methods often have limited scalability. To overcome these limitations, this paper proposes a simple but efficient method for generating adversarial negative responses leveraging a large-scale language model. Experimental results on dialogue selection tasks show that our method outperforms other methods of synthesizing adversarial negative responses. These results suggest that our method can be an effective alternative to human annotators in generating adversarial responses. Our dataset and generation code is available at https://github.com/leenw23/generating-negatives-by-gpt3.
DASH: Visual Analytics for Debiasing Image Classification via User-Driven Synthetic Data Augmentation
Sep 14, 2022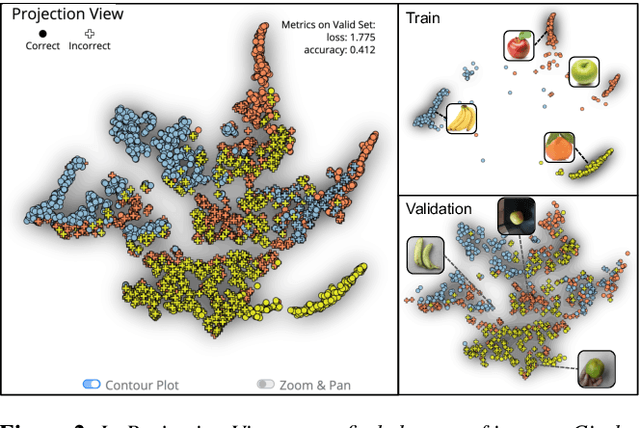
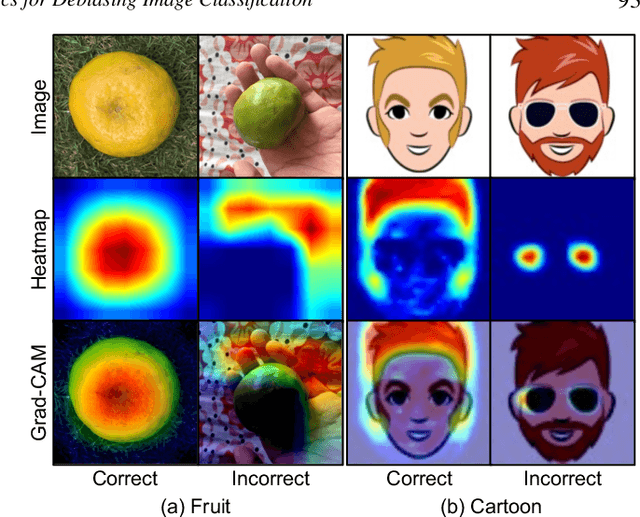
Image classification models often learn to predict a class based on irrelevant co-occurrences between input features and an output class in training data. We call the unwanted correlations "data biases," and the visual features causing data biases "bias factors." It is challenging to identify and mitigate biases automatically without human intervention. Therefore, we conducted a design study to find a human-in-the-loop solution. First, we identified user tasks that capture the bias mitigation process for image classification models with three experts. Then, to support the tasks, we developed a visual analytics system called DASH that allows users to visually identify bias factors, to iteratively generate synthetic images using a state-of-the-art image-to-image translation model, and to supervise the model training process for improving the classification accuracy. Our quantitative evaluation and qualitative study with ten participants demonstrate the usefulness of DASH and provide lessons for future work.
Evaluating Predictive Uncertainty under Distributional Shift on Dialogue Dataset
Sep 01, 2021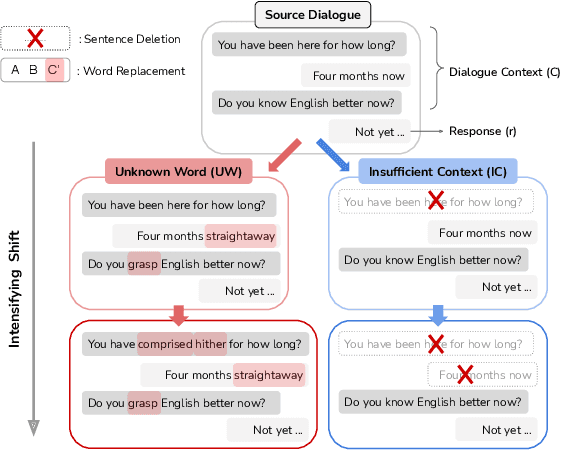

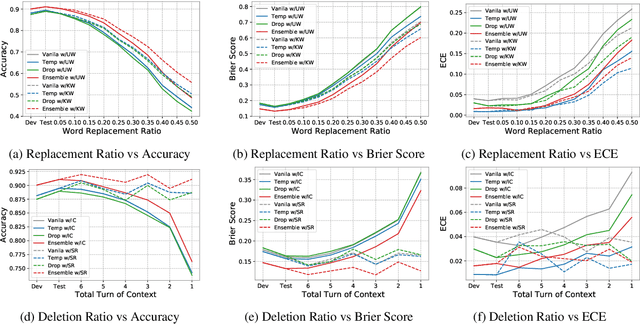

In open-domain dialogues, predictive uncertainties are mainly evaluated in a domain shift setting to cope with out-of-distribution inputs. However, in real-world conversations, there could be more extensive distributional shifted inputs than the out-of-distribution. To evaluate this, we first propose two methods, Unknown Word (UW) and Insufficient Context (IC), enabling gradual distributional shifts by corruption on the dialogue dataset. We then investigate the effect of distributional shifts on accuracy and calibration. Our experiments show that the performance of existing uncertainty estimation methods consistently degrades with intensifying the shift. The results suggest that the proposed methods could be useful for evaluating the calibration of dialogue systems under distributional shifts.
Constructing Multi-Modal Dialogue Dataset by Replacing Text with Semantically Relevant Images
Jul 19, 2021
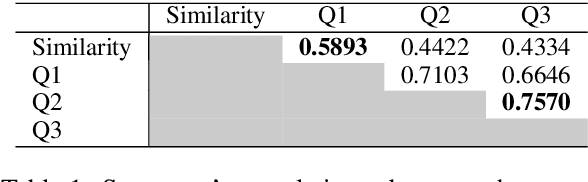
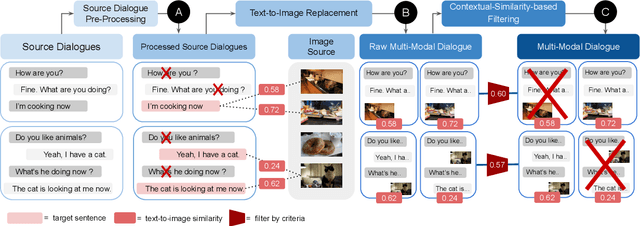
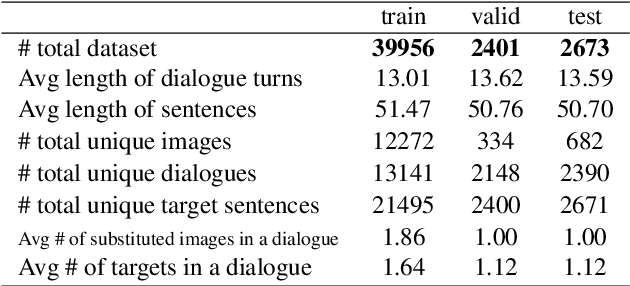
In multi-modal dialogue systems, it is important to allow the use of images as part of a multi-turn conversation. Training such dialogue systems generally requires a large-scale dataset consisting of multi-turn dialogues that involve images, but such datasets rarely exist. In response, this paper proposes a 45k multi-modal dialogue dataset created with minimal human intervention. Our method to create such a dataset consists of (1) preparing and pre-processing text dialogue datasets, (2) creating image-mixed dialogues by using a text-to-image replacement technique, and (3) employing a contextual-similarity-based filtering step to ensure the contextual coherence of the dataset. To evaluate the validity of our dataset, we devise a simple retrieval model for dialogue sentence prediction tasks. Automatic metrics and human evaluation results on such tasks show that our dataset can be effectively used as training data for multi-modal dialogue systems which require an understanding of images and text in a context-aware manner. Our dataset and generation code is available at https://github.com/shh1574/multi-modal-dialogue-dataset.