 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscern and Answer: Mitigating the Impact of Misinformation in Retrieval-Augmented Models with Discriminators
May 02, 2023Most existing retrieval-augmented language models (LMs) for question answering assume all retrieved information is factually correct. In this work, we study a more realistic scenario in which retrieved documents may contain misinformation, causing conflicts among them. We observe that the existing models are highly brittle to such information in both fine-tuning and in-context few-shot learning settings. We propose approaches to make retrieval-augmented LMs robust to misinformation by explicitly fine-tuning a discriminator or prompting to elicit discrimination capability in GPT-3. Our empirical results on open-domain question answering show that these approaches significantly improve LMs' robustness to knowledge conflicts. We also provide our findings on interleaving the fine-tuned model's decision with the in-context learning process, paving a new path to leverage the best of both worlds.
Maximizing Efficiency of Language Model Pre-training for Learning Representation
Oct 13, 2021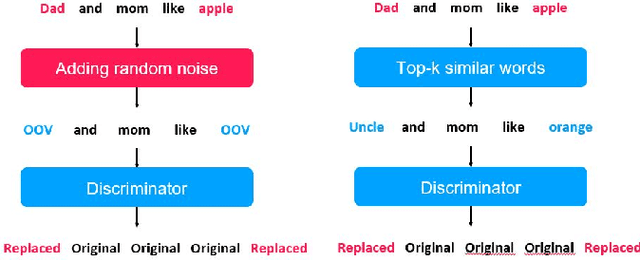
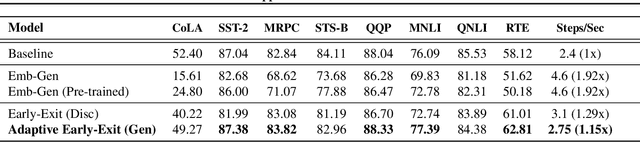
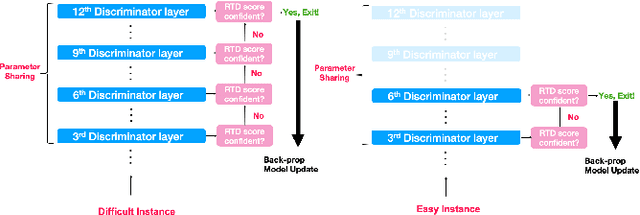
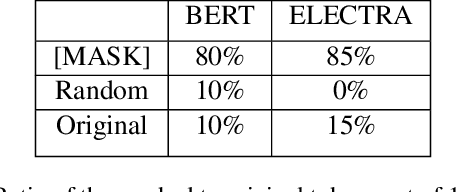
Pre-trained language models in the past years have shown exponential growth in model parameters and compute time. ELECTRA is a novel approach for improving the compute efficiency of pre-trained language models (e.g. BERT) based on masked language modeling (MLM) by addressing the sample inefficiency problem with the replaced token detection (RTD) task. Our work proposes adaptive early exit strategy to maximize the efficiency of the pre-training process by relieving the model's subsequent layers of the need to process latent features by leveraging earlier layer representations. Moreover, we evaluate an initial approach to the problem that has not succeeded in maintaining the accuracy of the model while showing a promising compute efficiency by thoroughly investigating the necessity of the generator module of ELECTRA.
UHD-BERT: Bucketed Ultra-High Dimensional Sparse Representations for Full Ranking
Apr 15, 2021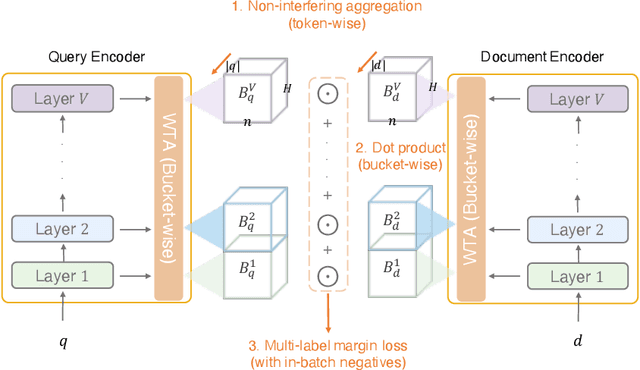
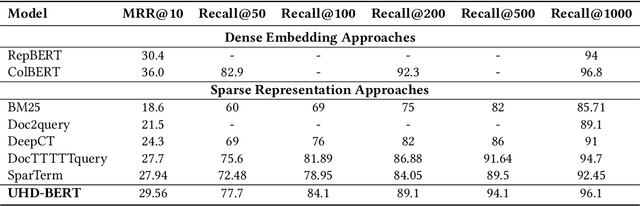
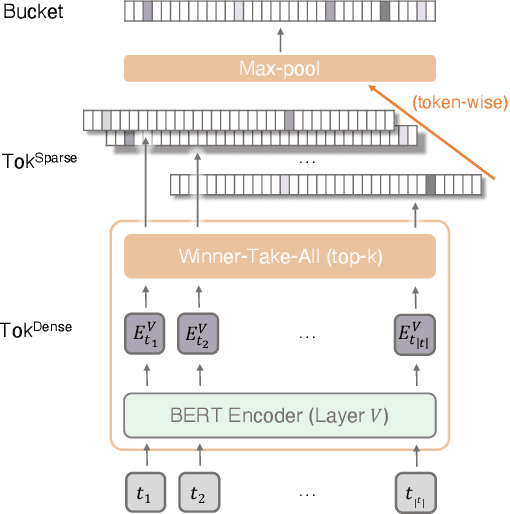

Neural information retrieval (IR) models are promising mainly because their semantic matching capabilities can ameliorate the well-known synonymy and polysemy problems of word-based symbolic approaches. However, the power of neural models' dense representations comes at the cost of inefficiency, limiting it to be used as a re-ranker. Sparse representations, on the other hand, can help enhance symbolic or latent-term representations and yet take advantage of an inverted index for efficiency, being amenable to symbolic IR techniques that have been around for decades. In order to transcend the trade-off between sparse representations (symbolic or latent-term based) and dense representations, we propose an ultra-high dimensional (UHD) representation scheme equipped with directly controllable sparsity. With the high dimensionality, we attempt to make the meaning of each dimension less entangled and polysemous than dense embeddings. The sparsity allows for not only efficiency for vector calculations but also the possibility of making individual dimensions attributable to interpretable concepts. Our model, UHD-BERT, maximizes the benefits of ultra-high dimensional (UHD) sparse representations based on BERT language modeling, by adopting a bucketing method. With this method, different segments of an embedding (horizontal buckets) or the embeddings from multiple layers of BERT (vertical buckets) can be selected and merged so that diverse linguistic aspects can be represented. An additional and important benefit of our highly disentangled (high-dimensional) and efficient (sparse) representations is that this neural approach can be harmonized with well-studied symbolic IR techniques (e.g., inverted index, pseudo-relevance feedback, BM25), enabling us to build a powerful and efficient neuro-symbolic information retrieval system.
A Sequence-Oblivious Generation Method for Context-Aware Hashtag Recommendation
Dec 05, 2020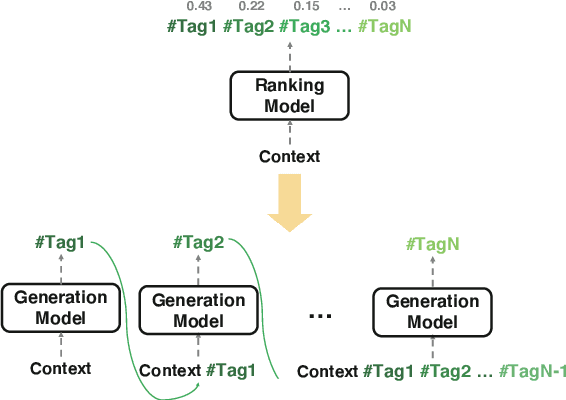
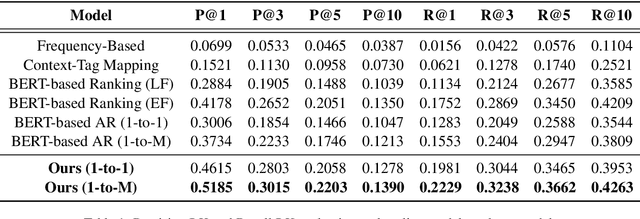
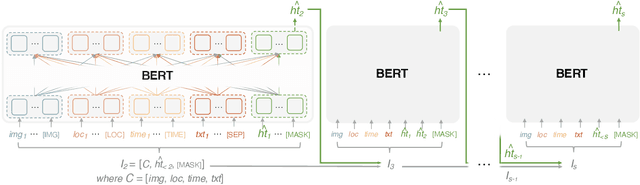
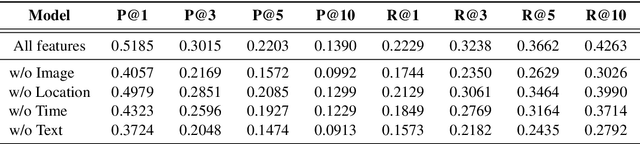
Like search, a recommendation task accepts an input query or cue and provides desirable items, often based on a ranking function. Such a ranking approach rarely considers explicit dependency among the recommended items. In this work, we propose a generative approach to tag recommendation, where semantic tags are selected one at a time conditioned on the previously generated tags to model inter-dependency among the generated tags. We apply this tag recommendation approach to an Instagram data set where an array of context feature types (image, location, time, and text) are available for posts. To exploit the inter-dependency among the distinct types of features, we adopt a simple yet effective architecture using self-attention, making deep interactions possible. Empirical results show that our method is significantly superior to not only the usual ranking schemes but also autoregressive models for tag recommendation. They indicate that it is critical to fuse mutually supporting features at an early stage to induce extensive and comprehensive view on inter-context interaction in generating tags in a recurrent feedback loop.
Let Me Know What to Ask: Interrogative-Word-Aware Question Generation
Oct 30, 2019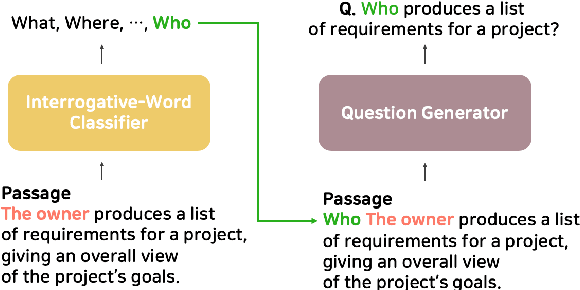
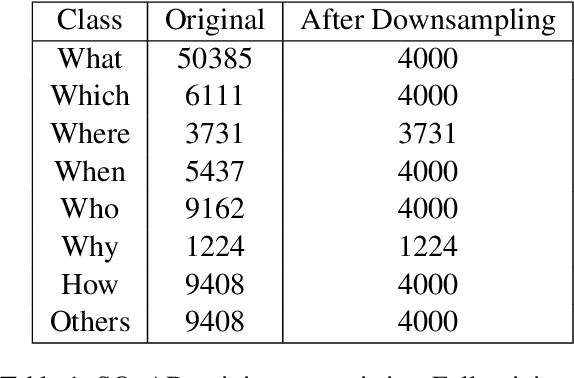
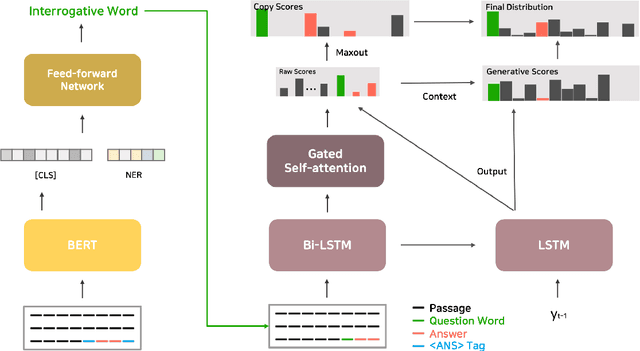
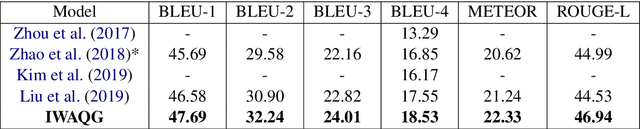
Question Generation (QG) is a Natural Language Processing (NLP) task that aids advances in Question Answering (QA) and conversational assistants. Existing models focus on generating a question based on a text and possibly the answer to the generated question. They need to determine the type of interrogative word to be generated while having to pay attention to the grammar and vocabulary of the question. In this work, we propose Interrogative-Word-Aware Question Generation (IWAQG), a pipelined system composed of two modules: an interrogative word classifier and a QG model. The first module predicts the interrogative word that is provided to the second module to create the question. Owing to an increased recall of deciding the interrogative words to be used for the generated questions, the proposed model achieves new state-of-the-art results on the task of QG in SQuAD, improving from 46.58 to 47.69 in BLEU-1, 17.55 to 18.53 in BLEU-4, 21.24 to 22.33 in METEOR, and from 44.53 to 46.94 in ROUGE-L.