 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study on Token Pruning for ColBERT
Dec 13, 2021
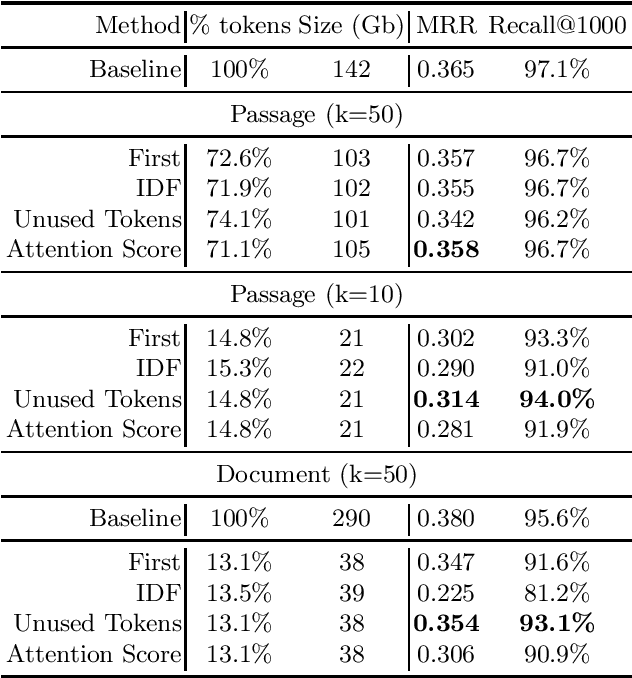
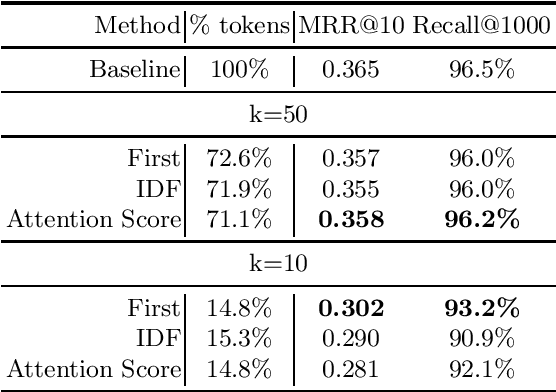
The ColBERT model has recently been proposed as an effective BERT based ranker. By adopting a late interaction mechanism, a major advantage of ColBERT is that document representations can be precomputed in advance. However, the big downside of the model is the index size, which scales linearly with the number of tokens in the collection. In this paper, we study various designs for ColBERT models in order to attack this problem. While compression techniques have been explored to reduce the index size, in this paper we study token pruning techniques for ColBERT. We compare simple heuristics, as well as a single layer of attention mechanism to select the tokens to keep at indexing time. Our experiments show that ColBERT indexes can be pruned up to 30\% on the MS MARCO passage collection without a significant drop in performance. Finally, we experiment on MS MARCO documents, which reveal several challenges for such mechanism.
UHD-BERT: Bucketed Ultra-High Dimensional Sparse Representations for Full Ranking
Apr 15, 2021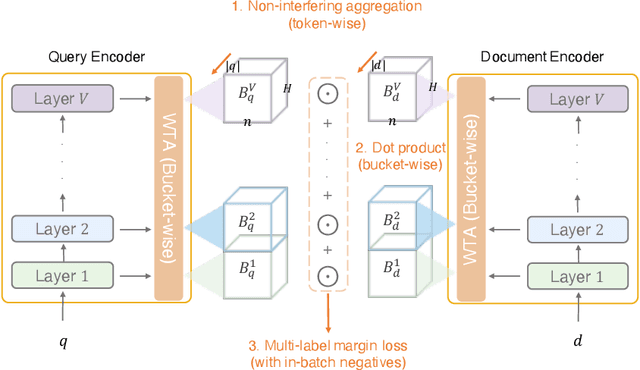
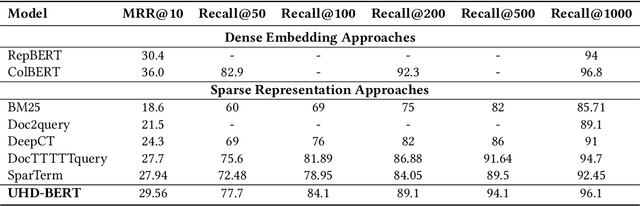
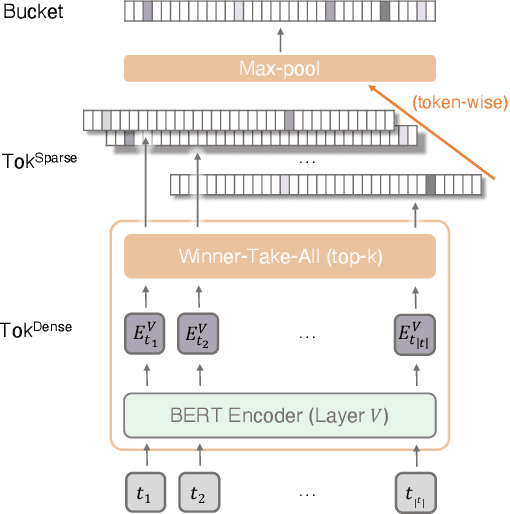

Neural information retrieval (IR) models are promising mainly because their semantic matching capabilities can ameliorate the well-known synonymy and polysemy problems of word-based symbolic approaches. However, the power of neural models' dense representations comes at the cost of inefficiency, limiting it to be used as a re-ranker. Sparse representations, on the other hand, can help enhance symbolic or latent-term representations and yet take advantage of an inverted index for efficiency, being amenable to symbolic IR techniques that have been around for decades. In order to transcend the trade-off between sparse representations (symbolic or latent-term based) and dense representations, we propose an ultra-high dimensional (UHD) representation scheme equipped with directly controllable sparsity. With the high dimensionality, we attempt to make the meaning of each dimension less entangled and polysemous than dense embeddings. The sparsity allows for not only efficiency for vector calculations but also the possibility of making individual dimensions attributable to interpretable concepts. Our model, UHD-BERT, maximizes the benefits of ultra-high dimensional (UHD) sparse representations based on BERT language modeling, by adopting a bucketing method. With this method, different segments of an embedding (horizontal buckets) or the embeddings from multiple layers of BERT (vertical buckets) can be selected and merged so that diverse linguistic aspects can be represented. An additional and important benefit of our highly disentangled (high-dimensional) and efficient (sparse) representations is that this neural approach can be harmonized with well-studied symbolic IR techniques (e.g., inverted index, pseudo-relevance feedback, BM25), enabling us to build a powerful and efficient neuro-symbolic information retrieval system.