 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain-of-Dictionary Prompting Elicits Translation in Large Language Models
Paper and Code



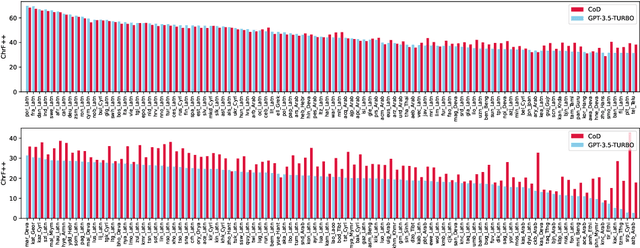
Large language models (LLMs) have shown surprisingly good performance in multilingual neural machine translation (MNMT) even when trained without parallel data. Yet, despite the fact that the amount of training data is gigantic, they still struggle with translating rare words, particularly for low-resource languages. Even worse, it is usually unrealistic to retrieve relevant demonstrations for in-context learning with low-resource languages on LLMs, which restricts the practical use of LLMs for translation -- how should we mitigate this problem? To this end, we present a novel method, CoD, which augments LLMs with prior knowledge with the chains of multilingual dictionaries for a subset of input words to elicit translation abilities for LLMs. Extensive experiments indicate that augmenting ChatGPT with CoD elicits large gains by up to 13x chrF++ points for MNMT (3.08 to 42.63 for English to Serbian written in Cyrillic script) on FLORES-200 full devtest set. We further demonstrate the importance of chaining the multilingual dictionaries, as well as the superiority of CoD to few-shot demonstration for low-resource languages.