 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Metrics Are Guilty: Improving NLG Evaluation with LLM Paraphrasing
Paper and Code

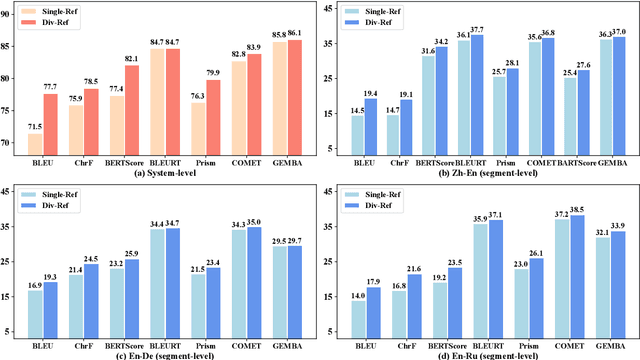

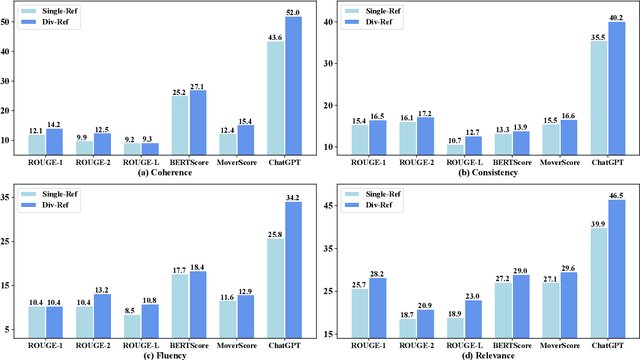
Most research about natural language generation (NLG) relies on evaluation benchmarks with limited references for a sample, which may result in poor correlations with human judgements. The underlying reason is that one semantic meaning can actually be expressed in different forms, and the evaluation with a single or few references may not accurately reflect the quality of the model's hypotheses. To address this issue, this paper presents a novel method, named Para-Ref, to enhance existing evaluation benchmarks by enriching the number of references. We leverage large language models (LLMs) to paraphrase a single reference into multiple high-quality ones in diverse expressions. Experimental results on representative NLG tasks of machine translation, text summarization, and image caption demonstrate that our method can effectively improve the correlation with human evaluation for sixteen automatic evaluation metrics by +7.82% in ratio. We release the code and data at https://github.com/RUCAIBox/Para-Ref.