 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCP-Persona: Benchmarking LLM Agents on Real-World Personal Applications via Environment Simulation
Jun 01, 2026The Model Context Protocol (MCP) has emerged as a transformative standard for connecting large language models (LLMs) with external data sources and tools, and has been rapidly adopted across personal applications and development platforms. However, existing benchmarks predominantly focus on generic information-seeking tools and fail to capture the practical challenges posed by personal social applications, where tools interact with individual accounts or local databases. To bridge this critical gap, we introduce MCP-Persona, the first benchmark specifically designed for evaluating agent performance on real-world, personalized MCP tools. MCP-Persona encompasses a diverse set of widely-used applications, ranging from social media platforms like Reddit and Xiaohongshu (Rednote) to enterprise collaboration suites such as Lark (Feishu) and Slack. Our extensive experiments on various state-of-the-art (SOTA) agents demonstrate their significant struggles with personalized tool use, thereby highlighting the benchmark's crucial role in identifying and addressing these limitations. MCP-Persona is publicly available at https://github.com/wwh0411/MCP-Persona}{https://github.com/wwh0411/MCP-Persona.
Code as Agent Harness
May 18, 2026Recent large language models (LLMs) have demonstrated strong capabilities in understanding and generating code, from competitive programming to repository-level software engineering. In emerging agentic systems, code is no longer only a target output. It increasingly serves as an operational substrate for agent reasoning, acting, environment modeling, and execution-based verification. We frame this shift through the lens of agent harnesses and introduce code as agent harness: a unified view that centers code as the basis for agent infrastructure. To systematically study this perspective, we organize the survey around three connected layers. First, we study the harness interface, where code connects agents to reasoning, action, and environment modeling. Second, we examine harness mechanisms: planning, memory, and tool use for long-horizon execution, together with feedback-driven control and optimization that make harness reliable and adaptive. Third, we discuss scaling the harness from single-agent systems to multi-agent settings, where shared code artifacts support multi-agent coordination, review, and verification. Across these layers, we summarize representative methods and practical applications of code as agent harness, spanning coding assistants, GUI/OS automation, embodied agents, scientific discovery, personalization and recommendation, DevOps, and enterprise workflows. We further outline open challenges for harness engineering, including evaluation beyond final task success, verification under incomplete feedback, regression-free harness improvement, consistent shared state across multiple agents, human oversight for safety-critical actions, and extensions to multimodal environments. By centering code as the harness of agentic AI, this survey provides a unified roadmap toward executable, verifiable, and stateful AI agent systems.
DataMaster: Towards Autonomous Data Engineering for Machine Learning
May 11, 2026As model families, training recipes, and compute budgets become increasingly standardized, further gains in machine learning systems depend increasingly on data. Yet data engineering remains largely manual and ad hoc: practitioners repeatedly search for external datasets, adapt them to existing pipelines, validate candidate data through downstream training, and carry forward lessons from prior attempts. We study task-conditioned autonomous data engineering, where an autonomous agent improves a fixed learning algorithm by optimizing only the data side, including external data discovery, data selection and composition, cleaning and transformation. The goal is to obtain a stronger downstream solution while leaving the learning algorithm unchanged. To address the open-ended search space, branch-dependent refinement, and delayed validation inherent in autonomous data engineering, we propose DataMaster, a data-agent framework that integrates tree-structured search, shared candidate data, and cumulative memory. DataMaster consists of three key components: a DataTree that organizes alternative data-engineering branches, a shared Data Pool that stores discovered external data sources for reuse, and a Global Memory that records node outcomes, artifacts, and reusable findings. Together, these components allow the agent to discover candidate data, construct executable training inputs, evaluate them through downstream feedback, and carry useful evidence across branches. We evaluate DataMaster on two types of benchmarks, MLE-Bench Lite and PostTrainBench. On MLE-Bench Lite, it improves medal rate by 32.27% over the initial score; on PostTrainBench, it surpasses the instruct model on GPQA (31.02% vs 30.35%).
Recursive Multi-Agent Systems
Apr 28, 2026Recursive or looped language models have recently emerged as a new scaling axis by iteratively refining the same model computation over latent states to deepen reasoning. We extend such scaling principle from a single model to multi-agent systems, and ask: Can agent collaboration itself be scaled through recursion? To this end, we introduce RecursiveMAS, a recursive multi-agent framework that casts the entire system as a unified latent-space recursive computation. RecursiveMAS connects heterogeneous agents as a collaboration loop through the lightweight RecursiveLink module, enabling in-distribution latent thoughts generation and cross-agent latent state transfer. To optimize our framework, we develop an inner-outer loop learning algorithm for iterative whole-system co-optimization through shared gradient-based credit assignment across recursion rounds. Theoretical analyses of runtime complexity and learning dynamics establish that RecursiveMAS is more efficient than standard text-based MAS and maintains stable gradients during recursive training. Empirically, we instantiate RecursiveMAS under 4 representative agent collaboration patterns and evaluate across 9 benchmarks spanning mathematics, science, medicine, search, and code generation. In comparison with advanced single/multi-agent and recursive computation baselines, RecursiveMAS consistently delivers an average accuracy improvement of 8.3%, together with 1.2$\times$-2.4$\times$ end-to-end inference speedup, and 34.6%-75.6% token usage reduction. Code and Data are provided in https://recursivemas.github.io.
Ramen: Robust Test-Time Adaptation of Vision-Language Models with Active Sample Selection
Apr 23, 2026Pretrained vision-language models such as CLIP exhibit strong zero-shot generalization but remain sensitive to distribution shifts. Test-time adaptation adapts models during inference without access to source data or target labels, offering a practical way to handle such shifts. However, existing methods typically assume that test samples come from a single, consistent domain, while in practice, test data often include samples from mixed domains with distinct characteristics. Consequently, their performance degrades under mixed-domain settings. To address this, we present Ramen, a framework for robust test-time adaptation through active sample selection. For each incoming test sample, Ramen retrieves a customized batch of relevant samples from previously seen data based on two criteria: domain consistency, which ensures that adaptation focuses on data from similar domains, and prediction balance, which mitigates adaptation bias caused by skewed predictions. To improve efficiency, Ramen employs an embedding-gradient cache that stores the embeddings and sample-level gradients of past test images. The stored embeddings are used to retrieve relevant samples, and the corresponding gradients are aggregated for model updates, eliminating the need for any additional forward or backward passes. Our theoretical analysis provides insight into why the proposed adaptation mechanism is effective under mixed-domain shifts. Experiments on multiple image corruption and domain-shift benchmarks demonstrate that Ramen achieves strong and consistent performance, offering robust and efficient adaptation in complex mixed-domain scenarios. Our code is available at https://github.com/baowenxuan/Ramen .
InfoMosaic-Bench: Evaluating Multi-Source Information Seeking in Tool-Augmented Agents
Oct 02, 2025Information seeking is a fundamental requirement for humans. However, existing LLM agents rely heavily on open-web search, which exposes two fundamental weaknesses: online content is noisy and unreliable, and many real-world tasks require precise, domain-specific knowledge unavailable from the web. The emergence of the Model Context Protocol (MCP) now allows agents to interface with thousands of specialized tools, seemingly resolving this limitation. Yet it remains unclear whether agents can effectively leverage such tools -- and more importantly, whether they can integrate them with general-purpose search to solve complex tasks. Therefore, we introduce InfoMosaic-Bench, the first benchmark dedicated to multi-source information seeking in tool-augmented agents. Covering six representative domains (medicine, finance, maps, video, web, and multi-domain integration), InfoMosaic-Bench requires agents to combine general-purpose search with domain-specific tools. Tasks are synthesized with InfoMosaic-Flow, a scalable pipeline that grounds task conditions in verified tool outputs, enforces cross-source dependencies, and filters out shortcut cases solvable by trivial lookup. This design guarantees both reliability and non-triviality. Experiments with 14 state-of-the-art LLM agents reveal three findings: (i) web information alone is insufficient, with GPT-5 achieving only 38.2% accuracy and 67.5% pass rate; (ii) domain tools provide selective but inconsistent benefits, improving some domains while degrading others; and (iii) 22.4% of failures arise from incorrect tool usage or selection, highlighting that current LLMs still struggle with even basic tool handling.
Differentially Private Federated Clustering with Random Rebalancing
Aug 08, 2025Federated clustering aims to group similar clients into clusters and produce one model for each cluster. Such a personalization approach typically improves model performance compared with training a single model to serve all clients, but can be more vulnerable to privacy leakage. Directly applying client-level differentially private (DP) mechanisms to federated clustering could degrade the utilities significantly. We identify that such deficiencies are mainly due to the difficulties of averaging privacy noise within each cluster (following standard privacy mechanisms), as the number of clients assigned to the same clusters is uncontrolled. To this end, we propose a simple and effective technique, named RR-Cluster, that can be viewed as a light-weight add-on to many federated clustering algorithms. RR-Cluster achieves reduced privacy noise via randomly rebalancing cluster assignments, guaranteeing a minimum number of clients assigned to each cluster. We analyze the tradeoffs between decreased privacy noise variance and potentially increased bias from incorrect assignments and provide convergence bounds for RR-Clsuter. Empirically, we demonstrate the RR-Cluster plugged into strong federated clustering algorithms results in significantly improved privacy/utility tradeoffs across both synthetic and real-world datasets.
Uncovering inequalities in new knowledge learning by large language models across different languages
Mar 06, 2025As large language models (LLMs) gradually become integral tools for problem solving in daily life worldwide, understanding linguistic inequality is becoming increasingly important. Existing research has primarily focused on static analyses that assess the disparities in the existing knowledge and capabilities of LLMs across languages. However, LLMs are continuously evolving, acquiring new knowledge to generate up-to-date, domain-specific responses. Investigating linguistic inequalities within this dynamic process is, therefore, also essential. In this paper, we explore inequalities in new knowledge learning by LLMs across different languages and four key dimensions: effectiveness, transferability, prioritization, and robustness. Through extensive experiments under two settings (in-context learning and fine-tuning) using both proprietary and open-source models, we demonstrate that low-resource languages consistently face disadvantages across all four dimensions. By shedding light on these disparities, we aim to raise awareness of linguistic inequalities in LLMs' new knowledge learning, fostering the development of more inclusive and equitable future LLMs.
Provably Efficient Action-Manipulation Attack Against Continuous Reinforcement Learning
Nov 20, 2024



Manipulating the interaction trajectories between the intelligent agent and the environment can control the agent's training and behavior, exposing the potential vulnerabilities of reinforcement learning (RL). For example, in Cyber-Physical Systems (CPS) controlled by RL, the attacker can manipulate the actions of the adopted RL to other actions during the training phase, which will lead to bad consequences. Existing work has studied action-manipulation attacks in tabular settings, where the states and actions are discrete. As seen in many up-and-coming RL applications, such as autonomous driving, continuous action space is widely accepted, however, its action-manipulation attacks have not been thoroughly investigated yet. In this paper, we consider this crucial problem in both white-box and black-box scenarios. Specifically, utilizing the knowledge derived exclusively from trajectories, we propose a black-box attack algorithm named LCBT, which uses the Monte Carlo tree search method for efficient action searching and manipulation. Additionally, we demonstrate that for an agent whose dynamic regret is sub-linearly related to the total number of steps, LCBT can teach the agent to converge to target policies with only sublinear attack cost, i.e., $O\left(\mathcal{R}(T) + MH^3K^E\log (MT)\right)(0<E<1)$, where $H$ is the number of steps per episode, $K$ is the total number of episodes, $T=KH$ is the total number of steps, $M$ is the number of subspaces divided in the state space, and $\mathcal{R}(T)$ is the bound of the RL algorithm's regret. We conduct our proposed attack methods on three aggressive algorithms: DDPG, PPO, and TD3 in continuous settings, which show a promising attack performance.
Learning Dynamic Context Augmentation for Global Entity Linking
Sep 04, 2019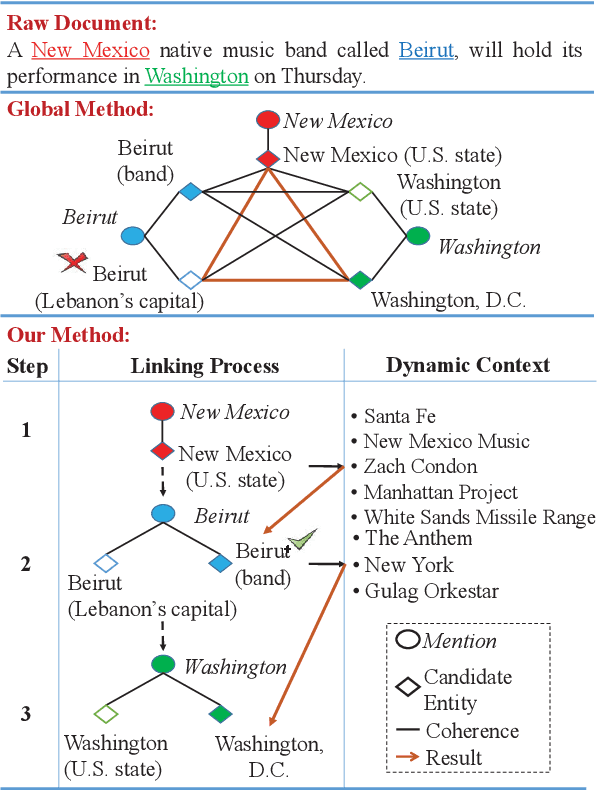
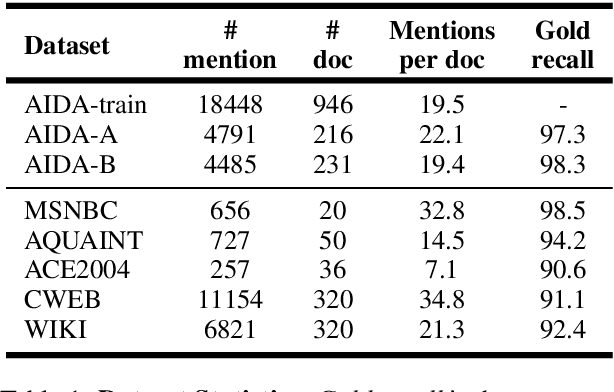
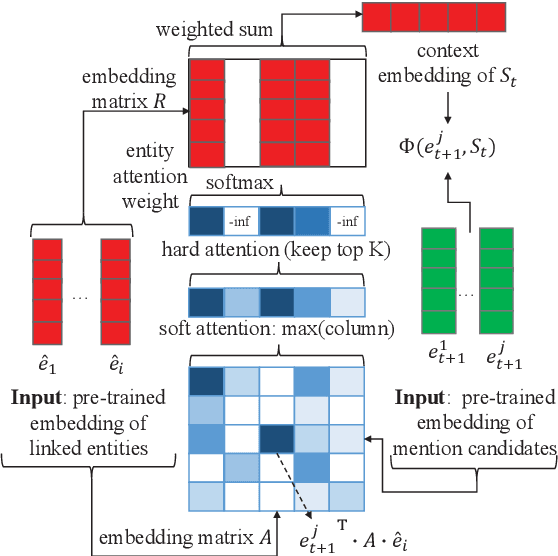
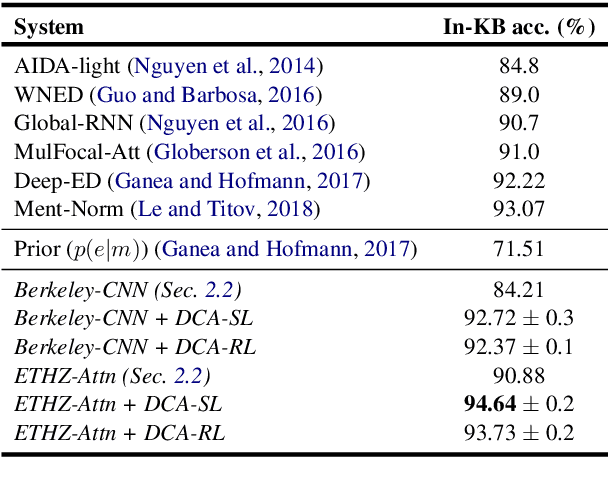
Despite of the recent success of collective entity linking (EL) methods, these "global" inference methods may yield sub-optimal results when the "all-mention coherence" assumption breaks, and often suffer from high computational cost at the inference stage, due to the complex search space. In this paper, we propose a simple yet effective solution, called Dynamic Context Augmentation (DCA), for collective EL, which requires only one pass through the mentions in a document. DCA sequentially accumulates context information to make efficient, collective inference, and can cope with different local EL models as a plug-and-enhance module. We explore both supervised and reinforcement learning strategies for learning the DCA model. Extensive experiments show the effectiveness of our model with different learning settings, base models, decision orders and attention mechanisms.