 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep learning for 3D point cloud processing -- from approaches, tasks to its implications on urban and environmental applications
Sep 15, 2025Point cloud processing as a fundamental task in the field of geomatics and computer vision, has been supporting tasks and applications at different scales from air to ground, including mapping, environmental monitoring, urban/tree structure modeling, automated driving, robotics, disaster responses etc. Due to the rapid development of deep learning, point cloud processing algorithms have nowadays been almost explicitly dominated by learning-based approaches, most of which are yet transitioned into real-world practices. Existing surveys primarily focus on the ever-updating network architecture to accommodate unordered point clouds, largely ignoring their practical values in typical point cloud processing applications, in which extra-large volume of data, diverse scene contents, varying point density, data modality need to be considered. In this paper, we provide a meta review on deep learning approaches and datasets that cover a selection of critical tasks of point cloud processing in use such as scene completion, registration, semantic segmentation, and modeling. By reviewing a broad range of urban and environmental applications these tasks can support, we identify gaps to be closed as these methods transformed into applications and draw concluding remarks in both the algorithmic and practical aspects of the surveyed methods.
A Survey on Large Language Model based Human-Agent Systems
May 01, 2025Recent advances in large language models (LLMs) have sparked growing interest in building fully autonomous agents. However, fully autonomous LLM-based agents still face significant challenges, including limited reliability due to hallucinations, difficulty in handling complex tasks, and substantial safety and ethical risks, all of which limit their feasibility and trustworthiness in real-world applications. To overcome these limitations, LLM-based human-agent systems (LLM-HAS) incorporate human-provided information, feedback, or control into the agent system to enhance system performance, reliability and safety. This paper provides the first comprehensive and structured survey of LLM-HAS. It clarifies fundamental concepts, systematically presents core components shaping these systems, including environment & profiling, human feedback, interaction types, orchestration and communication, explores emerging applications, and discusses unique challenges and opportunities. By consolidating current knowledge and offering a structured overview, we aim to foster further research and innovation in this rapidly evolving interdisciplinary field. Paper lists and resources are available at https://github.com/HenryPengZou/Awesome-LLM-Based-Human-Agent-System-Papers.
DocAgent: A Multi-Agent System for Automated Code Documentation Generation
Apr 11, 2025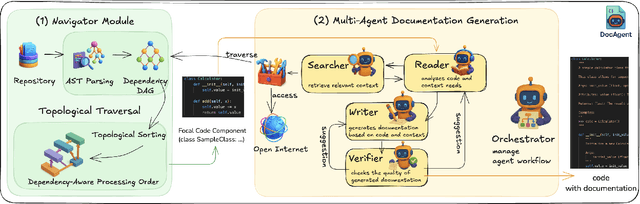
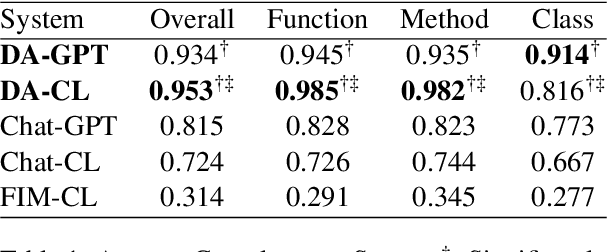
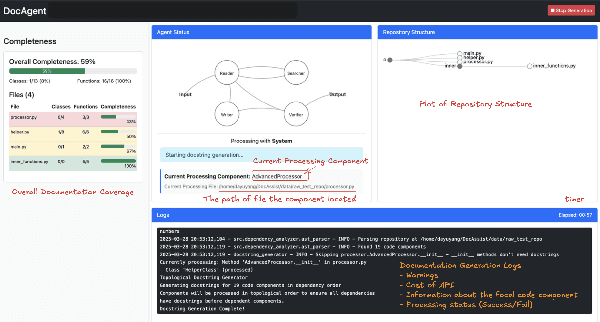

High-quality code documentation is crucial for software development especially in the era of AI. However, generating it automatically using Large Language Models (LLMs) remains challenging, as existing approaches often produce incomplete, unhelpful, or factually incorrect outputs. We introduce DocAgent, a novel multi-agent collaborative system using topological code processing for incremental context building. Specialized agents (Reader, Searcher, Writer, Verifier, Orchestrator) then collaboratively generate documentation. We also propose a multi-faceted evaluation framework assessing Completeness, Helpfulness, and Truthfulness. Comprehensive experiments show DocAgent significantly outperforms baselines consistently. Our ablation study confirms the vital role of the topological processing order. DocAgent offers a robust approach for reliable code documentation generation in complex and proprietary repositories.
Code to Think, Think to Code: A Survey on Code-Enhanced Reasoning and Reasoning-Driven Code Intelligence in LLMs
Feb 26, 2025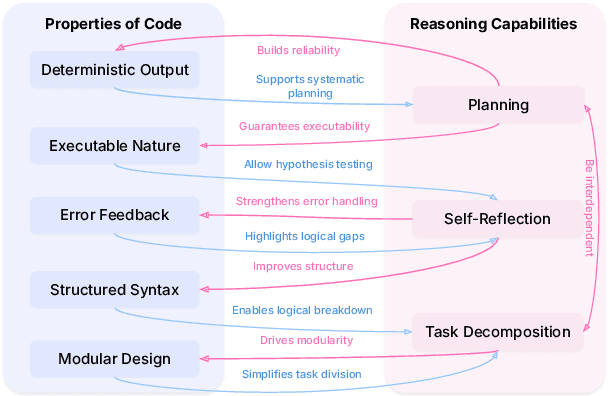
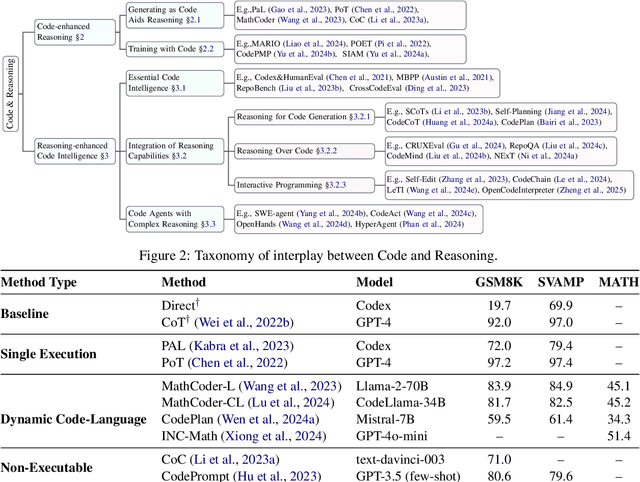


In large language models (LLMs), code and reasoning reinforce each other: code offers an abstract, modular, and logic-driven structure that supports reasoning, while reasoning translates high-level goals into smaller, executable steps that drive more advanced code intelligence. In this study, we examine how code serves as a structured medium for enhancing reasoning: it provides verifiable execution paths, enforces logical decomposition, and enables runtime validation. We also explore how improvements in reasoning have transformed code intelligence from basic completion to advanced capabilities, enabling models to address complex software engineering tasks through planning and debugging. Finally, we identify key challenges and propose future research directions to strengthen this synergy, ultimately improving LLM's performance in both areas.
Graph-Sequential Alignment and Uniformity: Toward Enhanced Recommendation Systems
Dec 05, 2024



Graph-based and sequential methods are two popular recommendation paradigms, each excelling in its domain but lacking the ability to leverage signals from the other. To address this, we propose a novel method that integrates both approaches for enhanced performance. Our framework uses Graph Neural Network (GNN)-based and sequential recommenders as separate submodules while sharing a unified embedding space optimized jointly. To enable positive knowledge transfer, we design a loss function that enforces alignment and uniformity both within and across submodules. Experiments on three real-world datasets demonstrate that the proposed method significantly outperforms using either approach alone and achieves state-of-the-art results. Our implementations are publicly available at https://github.com/YuweiCao-UIC/GSAU.git.
Aligning Large Language Models with Recommendation Knowledge
Mar 30, 2024



Large language models (LLMs) have recently been used as backbones for recommender systems. However, their performance often lags behind conventional methods in standard tasks like retrieval. We attribute this to a mismatch between LLMs' knowledge and the knowledge crucial for effective recommendations. While LLMs excel at natural language reasoning, they cannot model complex user-item interactions inherent in recommendation tasks. We propose bridging the knowledge gap and equipping LLMs with recommendation-specific knowledge to address this. Operations such as Masked Item Modeling (MIM) and Bayesian Personalized Ranking (BPR) have found success in conventional recommender systems. Inspired by this, we simulate these operations through natural language to generate auxiliary-task data samples that encode item correlations and user preferences. Fine-tuning LLMs on such auxiliary-task data samples and incorporating more informative recommendation-task data samples facilitates the injection of recommendation-specific knowledge into LLMs. Extensive experiments across retrieval, ranking, and rating prediction tasks on LLMs such as FLAN-T5-Base and FLAN-T5-XL show the effectiveness of our technique in domains such as Amazon Toys & Games, Beauty, and Sports & Outdoors. Notably, our method outperforms conventional and LLM-based baselines, including the current SOTA, by significant margins in retrieval, showcasing its potential for enhancing recommendation quality.
Hierarchical and Incremental Structural Entropy Minimization for Unsupervised Social Event Detection
Dec 19, 2023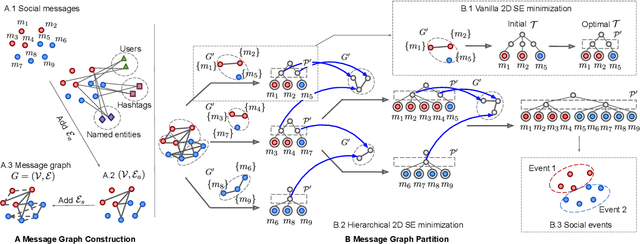

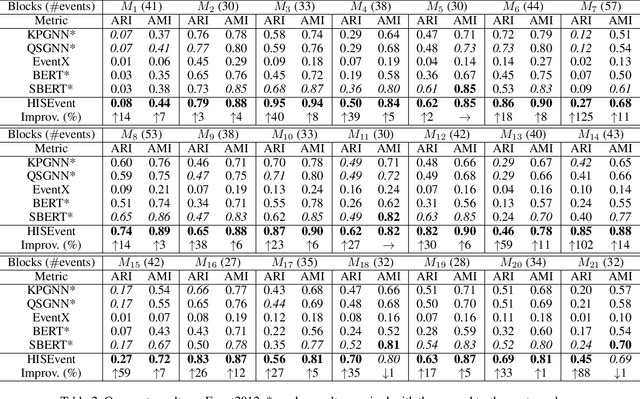
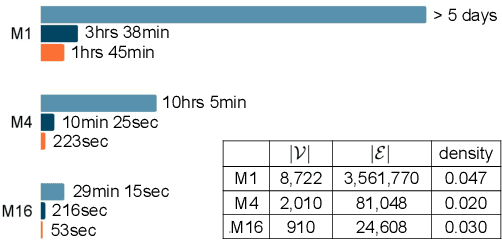
As a trending approach for social event detection, graph neural network (GNN)-based methods enable a fusion of natural language semantics and the complex social network structural information, thus showing SOTA performance. However, GNN-based methods can miss useful message correlations. Moreover, they require manual labeling for training and predetermining the number of events for prediction. In this work, we address social event detection via graph structural entropy (SE) minimization. While keeping the merits of the GNN-based methods, the proposed framework, HISEvent, constructs more informative message graphs, is unsupervised, and does not require the number of events given a priori. Specifically, we incrementally explore the graph neighborhoods using 1-dimensional (1D) SE minimization to supplement the existing message graph with edges between semantically related messages. We then detect events from the message graph by hierarchically minimizing 2-dimensional (2D) SE. Our proposed 1D and 2D SE minimization algorithms are customized for social event detection and effectively tackle the efficiency problem of the existing SE minimization algorithms. Extensive experiments show that HISEvent consistently outperforms GNN-based methods and achieves the new SOTA for social event detection under both closed- and open-set settings while being efficient and robust.
LLMRec: Benchmarking Large Language Models on Recommendation Task
Aug 23, 2023


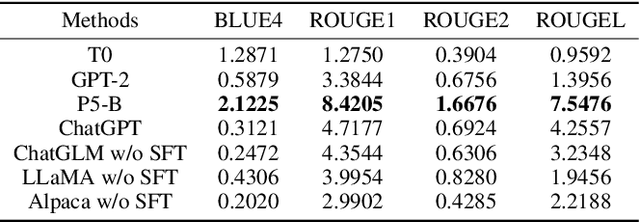
Recently, the fast development of Large Language Models (LLMs) such as ChatGPT has significantly advanced NLP tasks by enhancing the capabilities of conversational models. However, the application of LLMs in the recommendation domain has not been thoroughly investigated. To bridge this gap, we propose LLMRec, a LLM-based recommender system designed for benchmarking LLMs on various recommendation tasks. Specifically, we benchmark several popular off-the-shelf LLMs, such as ChatGPT, LLaMA, ChatGLM, on five recommendation tasks, including rating prediction, sequential recommendation, direct recommendation, explanation generation, and review summarization. Furthermore, we investigate the effectiveness of supervised finetuning to improve LLMs' instruction compliance ability. The benchmark results indicate that LLMs displayed only moderate proficiency in accuracy-based tasks such as sequential and direct recommendation. However, they demonstrated comparable performance to state-of-the-art methods in explainability-based tasks. We also conduct qualitative evaluations to further evaluate the quality of contents generated by different models, and the results show that LLMs can truly understand the provided information and generate clearer and more reasonable results. We aspire that this benchmark will serve as an inspiration for researchers to delve deeper into the potential of LLMs in enhancing recommendation performance. Our codes, processed data and benchmark results are available at https://github.com/williamliujl/LLMRec.
Multi-task Item-attribute Graph Pre-training for Strict Cold-start Item Recommendation
Jun 26, 2023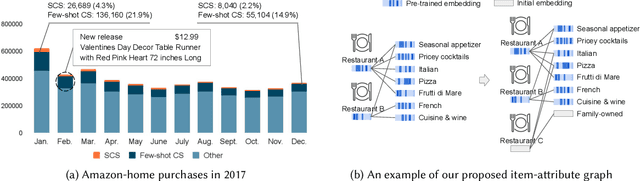



Recommendation systems suffer in the strict cold-start (SCS) scenario, where the user-item interactions are entirely unavailable. The ID-based approaches completely fail to work. Cold-start recommenders, on the other hand, leverage item contents to map the new items to the existing ones. However, the existing SCS recommenders explore item contents in coarse-grained manners that introduce noise or information loss. Moreover, informative data sources other than item contents, such as users' purchase sequences and review texts, are ignored. We explore the role of the fine-grained item attributes in bridging the gaps between the existing and the SCS items and pre-train a knowledgeable item-attribute graph for SCS item recommendation. Our proposed framework, ColdGPT, models item-attribute correlations into an item-attribute graph by extracting fine-grained attributes from item contents. ColdGPT then transfers knowledge into the item-attribute graph from various available data sources, i.e., item contents, historical purchase sequences, and review texts of the existing items, via multi-task learning. To facilitate the positive transfer, ColdGPT designs submodules according to the natural forms of the data sources and coordinates the multiple pre-training tasks via unified alignment-and-uniformity losses. Our pre-trained item-attribute graph acts as an implicit, extendable item embedding matrix, which enables the SCS item embeddings to be easily acquired by inserting these items and propagating their attributes' embeddings. We carefully process three public datasets, i.e., Yelp, Amazon-home, and Amazon-sports, to guarantee the SCS setting for evaluation. Extensive experiments show that ColdGPT consistently outperforms the existing SCS recommenders by large margins and even surpasses models that are pre-trained on 75-224 times more, cross-domain data on two out of four datasets.
XLTime: A Cross-Lingual Knowledge Transfer Framework for Temporal Expression Extraction
May 03, 2022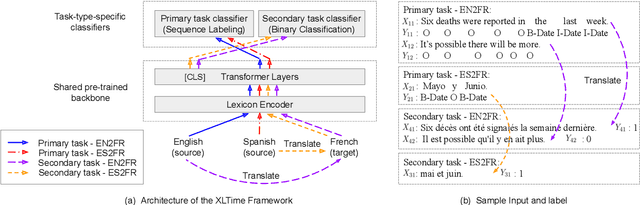
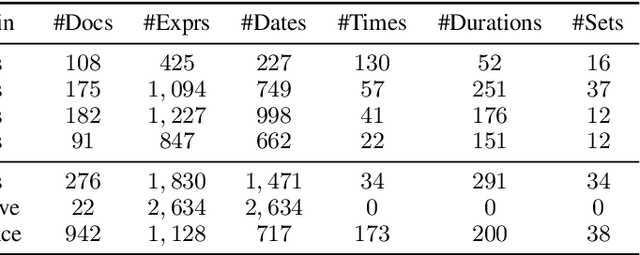
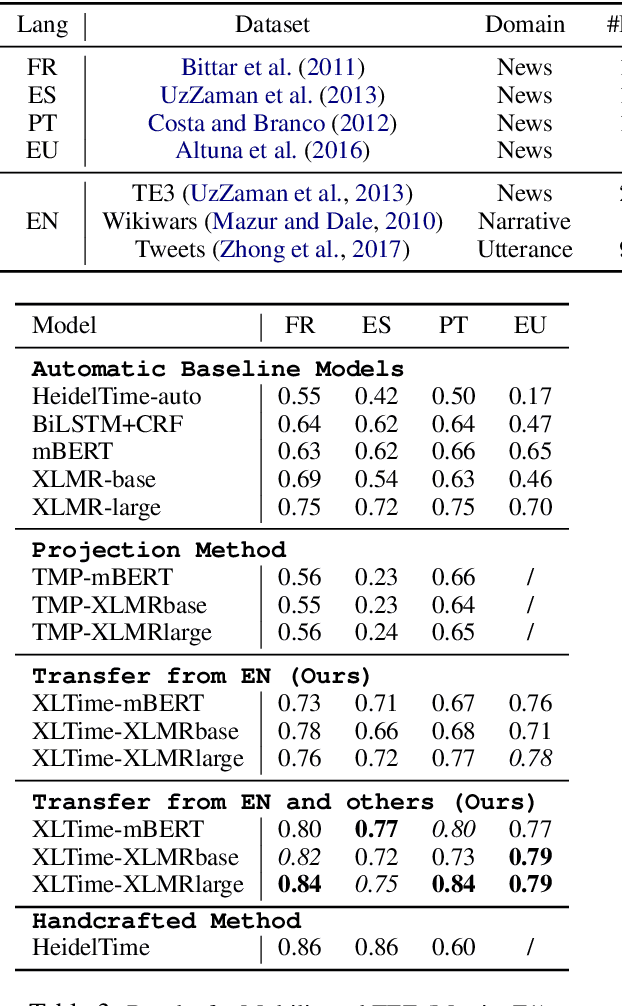
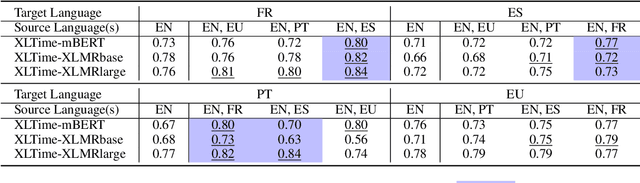
Temporal Expression Extraction (TEE) is essential for understanding time in natural language. It has applications in Natural Language Processing (NLP) tasks such as question answering, information retrieval, and causal inference. To date, work in this area has mostly focused on English as there is a scarcity of labeled data for other languages. We propose XLTime, a novel framework for multilingual TEE. XLTime works on top of pre-trained language models and leverages multi-task learning to prompt cross-language knowledge transfer both from English and within the non-English languages. XLTime alleviates problems caused by a shortage of data in the target language. We apply XLTime with different language models and show that it outperforms the previous automatic SOTA methods on French, Spanish, Portuguese, and Basque, by large margins. XLTime also closes the gap considerably on the handcrafted HeidelTime method.