 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Users Change Their Mind: Evaluating Interruptible Agents in Long-Horizon Web Navigation
Apr 01, 2026As LLM agents transition from short, static problem solving to executing complex, long-horizon tasks in dynamic environments, the ability to handle user interruptions, such as adding requirement or revising goals, during mid-task execution is becoming a core requirement for realistic deployment. However, existing benchmarks largely assume uninterrupted agent behavior or study interruptions only in short, unconstrained language tasks. In this paper, we present the first systematic study of interruptible agents in long-horizon, environmentally grounded web navigation tasks, where actions induce persistent state changes. We formalize three realistic interruption types, including addition, revision, and retraction, and introduce InterruptBench, a benchmark derived from WebArena-Lite that synthesizes high-quality interruption scenarios under strict semantic constraints. Using a unified interruption simulation framework, we evaluate six strong LLM backbones across single- and multi-turn interruption settings, analyzing both their effectiveness in adapting to updated intents and their efficiency in recovering from mid-task changes. Our results show that handling user interruptions effectively and efficiently during long-horizon agentic tasks remains challenging for powerful large-scale LLMs. Code and dataset are available at https://github.com/HenryPengZou/InterruptBench.
Locally Confident, Globally Stuck: The Quality-Exploration Dilemma in Diffusion Language Models
Apr 01, 2026Diffusion large language models (dLLMs) theoretically permit token decoding in arbitrary order, a flexibility that could enable richer exploration of reasoning paths than autoregressive (AR) LLMs. In practice, however, random-order decoding often hurts generation quality. To mitigate this, low-confidence remasking improves single-sample quality (e.g., Pass@$1$) by prioritizing confident tokens, but it also suppresses exploration and limits multi-sample gains (e.g., Pass@$k$), creating a fundamental quality--exploration dilemma. In this paper, we provide a unified explanation of this dilemma. We show that low-confidence remasking improves a myopic proxy for quality while provably constraining the entropy of the induced sequence distribution. To overcome this limitation, we characterize the optimal distribution that explicitly balances quality and exploration, and develop a simple Independent Metropolis--Hastings sampler that approximately targets this distribution during decoding. Experiments across a range of reasoning benchmarks including MATH500, AIME24/25, HumanEval, and MBPP show that our approach yields better exploration-quality tradeoff than both random and low-confidence remasking.
d-TreeRPO: Towards More Reliable Policy Optimization for Diffusion Language Models
Dec 10, 2025Reliable reinforcement learning (RL) for diffusion large language models (dLLMs) requires both accurate advantage estimation and precise estimation of prediction probabilities. Existing RL methods for dLLMs fall short in both aspects: they rely on coarse or unverifiable reward signals, and they estimate prediction probabilities without accounting for the bias relative to the true, unbiased expected prediction probability that properly integrates over all possible decoding orders. To mitigate these issues, we propose \emph{d}-TreeRPO, a reliable RL framework for dLLMs that leverages tree-structured rollouts and bottom-up advantage computation based on verifiable outcome rewards to provide fine-grained and verifiable step-wise reward signals. When estimating the conditional transition probability from a parent node to a child node, we theoretically analyze the estimation error between the unbiased expected prediction probability and the estimate obtained via a single forward pass, and find that higher prediction confidence leads to lower estimation error. Guided by this analysis, we introduce a time-scheduled self-distillation loss during training that enhances prediction confidence in later training stages, thereby enabling more accurate probability estimation and improved convergence. Experiments show that \emph{d}-TreeRPO outperforms existing baselines and achieves significant gains on multiple reasoning benchmarks, including +86.2 on Sudoku, +51.6 on Countdown, +4.5 on GSM8K, and +5.3 on Math500. Ablation studies and computational cost analyses further demonstrate the effectiveness and practicality of our design choices.
A Survey on Parallel Text Generation: From Parallel Decoding to Diffusion Language Models
Aug 12, 2025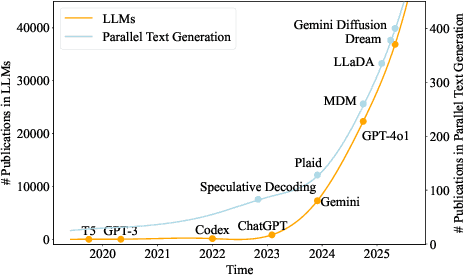
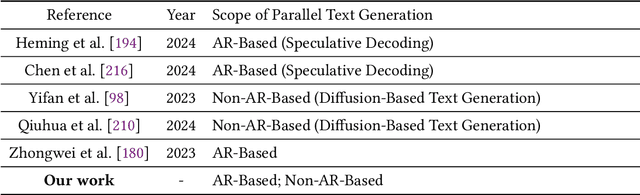
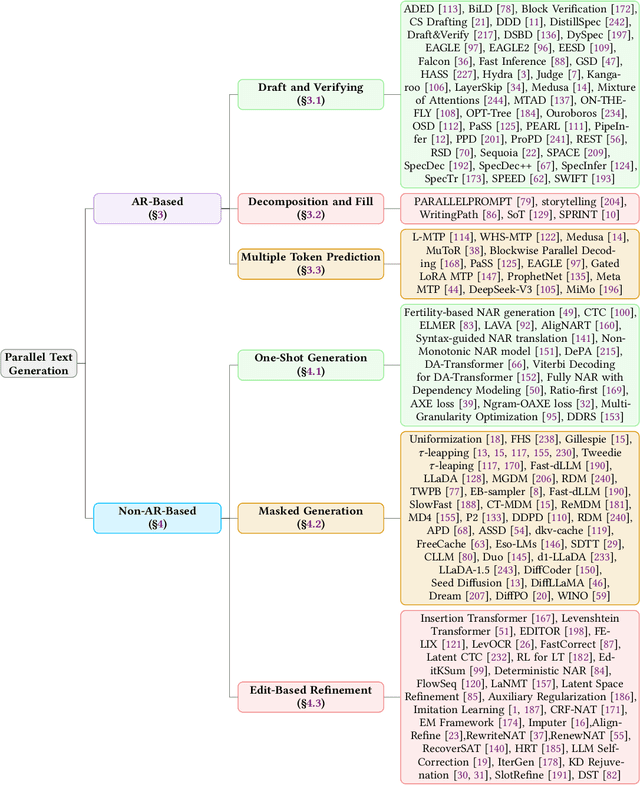
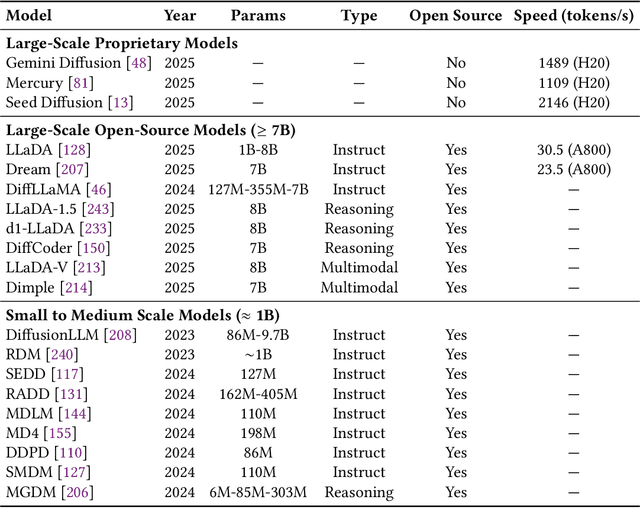
As text generation has become a core capability of modern Large Language Models (LLMs), it underpins a wide range of downstream applications. However, most existing LLMs rely on autoregressive (AR) generation, producing one token at a time based on previously generated context-resulting in limited generation speed due to the inherently sequential nature of the process. To address this challenge, an increasing number of researchers have begun exploring parallel text generation-a broad class of techniques aimed at breaking the token-by-token generation bottleneck and improving inference efficiency. Despite growing interest, there remains a lack of comprehensive analysis on what specific techniques constitute parallel text generation and how they improve inference performance. To bridge this gap, we present a systematic survey of parallel text generation methods. We categorize existing approaches into AR-based and Non-AR-based paradigms, and provide a detailed examination of the core techniques within each category. Following this taxonomy, we assess their theoretical trade-offs in terms of speed, quality, and efficiency, and examine their potential for combination and comparison with alternative acceleration strategies. Finally, based on our findings, we highlight recent advancements, identify open challenges, and outline promising directions for future research in parallel text generation.
A Call for Collaborative Intelligence: Why Human-Agent Systems Should Precede AI Autonomy
Jun 11, 2025Recent improvements in large language models (LLMs) have led many researchers to focus on building fully autonomous AI agents. This position paper questions whether this approach is the right path forward, as these autonomous systems still have problems with reliability, transparency, and understanding the actual requirements of human. We suggest a different approach: LLM-based Human-Agent Systems (LLM-HAS), where AI works with humans rather than replacing them. By keeping human involved to provide guidance, answer questions, and maintain control, these systems can be more trustworthy and adaptable. Looking at examples from healthcare, finance, and software development, we show how human-AI teamwork can handle complex tasks better than AI working alone. We also discuss the challenges of building these collaborative systems and offer practical solutions. This paper argues that progress in AI should not be measured by how independent systems become, but by how well they can work with humans. The most promising future for AI is not in systems that take over human roles, but in those that enhance human capabilities through meaningful partnership.
A Survey on Large Language Model based Human-Agent Systems
May 01, 2025Recent advances in large language models (LLMs) have sparked growing interest in building fully autonomous agents. However, fully autonomous LLM-based agents still face significant challenges, including limited reliability due to hallucinations, difficulty in handling complex tasks, and substantial safety and ethical risks, all of which limit their feasibility and trustworthiness in real-world applications. To overcome these limitations, LLM-based human-agent systems (LLM-HAS) incorporate human-provided information, feedback, or control into the agent system to enhance system performance, reliability and safety. This paper provides the first comprehensive and structured survey of LLM-HAS. It clarifies fundamental concepts, systematically presents core components shaping these systems, including environment & profiling, human feedback, interaction types, orchestration and communication, explores emerging applications, and discusses unique challenges and opportunities. By consolidating current knowledge and offering a structured overview, we aim to foster further research and innovation in this rapidly evolving interdisciplinary field. Paper lists and resources are available at https://github.com/HenryPengZou/Awesome-LLM-Based-Human-Agent-System-Papers.
TestNUC: Enhancing Test-Time Computing Approaches through Neighboring Unlabeled Data Consistency
Feb 26, 2025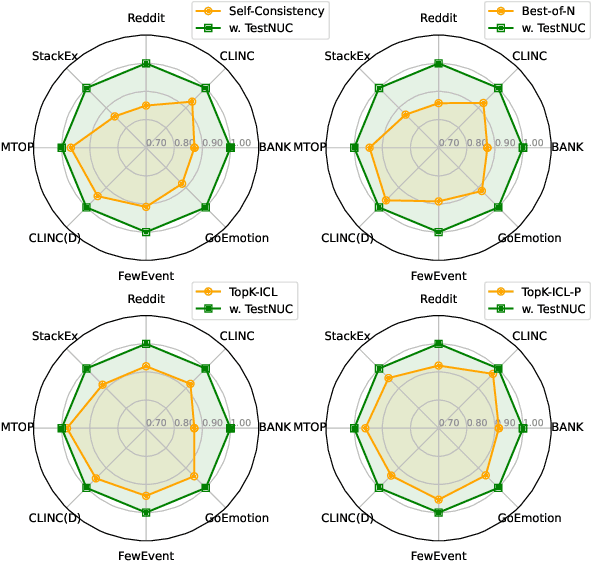
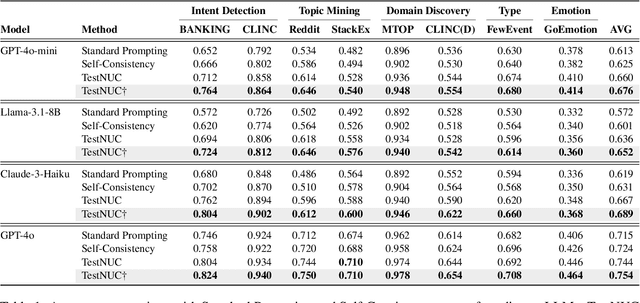
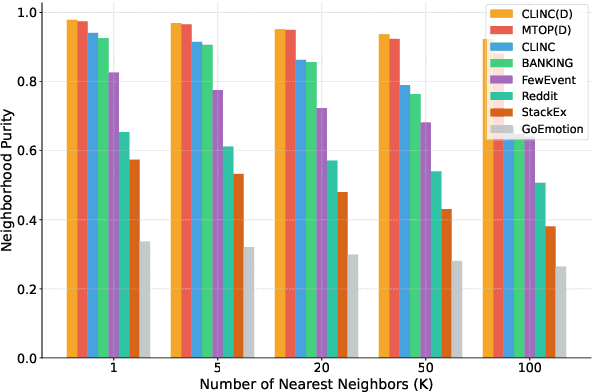
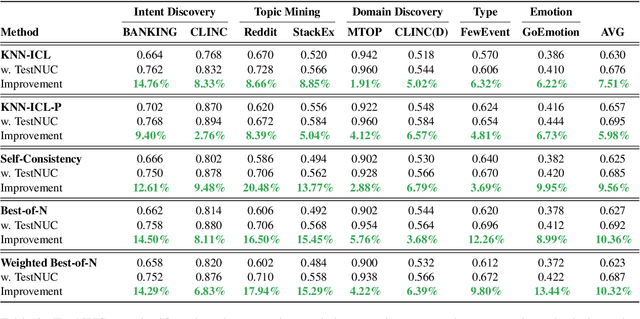
Test-time computing approaches, which leverage additional computational resources during inference, have been proven effective in enhancing large language model performance. This work introduces a novel, linearly scaling approach, TestNUC, that improves test-time predictions by leveraging the local consistency of neighboring unlabeled data-it classifies an input instance by considering not only the model's prediction on that instance but also on neighboring unlabeled instances. We evaluate TestNUC across eight diverse datasets, spanning intent classification, topic mining, domain discovery, and emotion detection, demonstrating its consistent superiority over baseline methods such as standard prompting and self-consistency. Furthermore, TestNUC can be seamlessly integrated with existing test-time computing approaches, substantially boosting their performance. Our analysis reveals that TestNUC scales effectively with increasing amounts of unlabeled data and performs robustly across different embedding models, making it practical for real-world applications. Our code is available at https://github.com/HenryPengZou/TestNUC.
Multi-Agent Autonomous Driving Systems with Large Language Models: A Survey of Recent Advances
Feb 24, 2025Autonomous Driving Systems (ADSs) are revolutionizing transportation by reducing human intervention, improving operational efficiency, and enhancing safety. Large Language Models (LLMs), known for their exceptional planning and reasoning capabilities, have been integrated into ADSs to assist with driving decision-making. However, LLM-based single-agent ADSs face three major challenges: limited perception, insufficient collaboration, and high computational demands. To address these issues, recent advancements in LLM-based multi-agent ADSs have focused on improving inter-agent communication and cooperation. This paper provides a frontier survey of LLM-based multi-agent ADSs. We begin with a background introduction to related concepts, followed by a categorization of existing LLM-based approaches based on different agent interaction modes. We then discuss agent-human interactions in scenarios where LLM-based agents engage with humans. Finally, we summarize key applications, datasets, and challenges in this field to support future research (https://anonymous.4open.science/r/LLM-based_Multi-agent_ADS-3A5C/README.md).
TabGen-ICL: Residual-Aware In-Context Example Selection for Tabular Data Generation
Feb 23, 2025Large Language models (LLMs) have achieved encouraging results in tabular data generation. However, existing approaches require fine-tuning, which is computationally expensive. This paper explores an alternative: prompting a fixed LLM with in-context examples. We observe that using randomly selected in-context examples hampers the LLM's performance, resulting in sub-optimal generation quality. To address this, we propose a novel in-context learning framework: TabGen-ICL, to enhance the in-context learning ability of LLMs for tabular data generation. TabGen-ICL operates iteratively, retrieving a subset of real samples that represent the residual between currently generated samples and true data distributions. This approach serves two purposes: locally, it provides more effective in-context learning examples for the LLM in each iteration; globally, it progressively narrows the gap between generated and real data. Extensive experiments on five real-world tabular datasets demonstrate that TabGen-ICL significantly outperforms the random selection strategy. Specifically, it reduces the error rate by a margin of $3.5\%-42.2\%$ on fidelity metrics. We demonstrate for the first time that prompting a fixed LLM can yield high-quality synthetic tabular data. The code is provided in the \href{https://github.com/fangliancheng/TabGEN-ICL}{link}.
Diffusion-nested Auto-Regressive Synthesis of Heterogeneous Tabular Data
Oct 28, 2024Autoregressive models are predominant in natural language generation, while their application in tabular data remains underexplored. We posit that this can be attributed to two factors: 1) tabular data contains heterogeneous data type, while the autoregressive model is primarily designed to model discrete-valued data; 2) tabular data is column permutation-invariant, requiring a generation model to generate columns in arbitrary order. This paper proposes a Diffusion-nested Autoregressive model (TabDAR) to address these issues. To enable autoregressive methods for continuous columns, TabDAR employs a diffusion model to parameterize the conditional distribution of continuous features. To ensure arbitrary generation order, TabDAR resorts to masked transformers with bi-directional attention, which simulate various permutations of column order, hence enabling it to learn the conditional distribution of a target column given an arbitrary combination of other columns. These designs enable TabDAR to not only freely handle heterogeneous tabular data but also support convenient and flexible unconditional/conditional sampling. We conduct extensive experiments on ten datasets with distinct properties, and the proposed TabDAR outperforms previous state-of-the-art methods by 18% to 45% on eight metrics across three distinct aspects.