 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Hallucinations in Graph Retrieval-Augmented Generation via Attention Patterns and Semantic Alignment
Dec 09, 2025Graph-based Retrieval-Augmented Generation (GraphRAG) enhances Large Language Models (LLMs) by incorporating external knowledge from linearized subgraphs retrieved from knowledge graphs. However, LLMs struggle to interpret the relational and topological information in these inputs, resulting in hallucinations that are inconsistent with the retrieved knowledge. To analyze how LLMs attend to and retain structured knowledge during generation, we propose two lightweight interpretability metrics: Path Reliance Degree (PRD), which measures over-reliance on shortest-path triples, and Semantic Alignment Score (SAS), which assesses how well the model's internal representations align with the retrieved knowledge. Through empirical analysis on a knowledge-based QA task, we identify failure patterns associated with over-reliance on salient paths and weak semantic grounding, as indicated by high PRD and low SAS scores. We further develop a lightweight post-hoc hallucination detector, Graph Grounding and Alignment (GGA), which outperforms strong semantic and confidence-based baselines across AUC and F1. By grounding hallucination analysis in mechanistic interpretability, our work offers insights into how structural limitations in LLMs contribute to hallucinations, informing the design of more reliable GraphRAG systems in the future.
LLM-MemCluster: Empowering Large Language Models with Dynamic Memory for Text Clustering
Nov 19, 2025Large Language Models (LLMs) are reshaping unsupervised learning by offering an unprecedented ability to perform text clustering based on their deep semantic understanding. However, their direct application is fundamentally limited by a lack of stateful memory for iterative refinement and the difficulty of managing cluster granularity. As a result, existing methods often rely on complex pipelines with external modules, sacrificing a truly end-to-end approach. We introduce LLM-MemCluster, a novel framework that reconceptualizes clustering as a fully LLM-native task. It leverages a Dynamic Memory to instill state awareness and a Dual-Prompt Strategy to enable the model to reason about and determine the number of clusters. Evaluated on several benchmark datasets, our tuning-free framework significantly and consistently outperforms strong baselines. LLM-MemCluster presents an effective, interpretable, and truly end-to-end paradigm for LLM-based text clustering.
AppForge: From Assistant to Independent Developer - Are GPTs Ready for Software Development?
Oct 09, 2025



Large language models (LLMs) have demonstrated remarkable capability in function-level code generation tasks. Unlike isolated functions, real-world applications demand reasoning over the entire software system: developers must orchestrate how different components interact, maintain consistency across states over time, and ensure the application behaves correctly within the lifecycle and framework constraints. Yet, no existing benchmark adequately evaluates whether LLMs can bridge this gap and construct entire software systems from scratch. To address this gap, we propose APPFORGE, a benchmark consisting of 101 software development problems drawn from real-world Android apps. Given a natural language specification detailing the app functionality, a language model is tasked with implementing the functionality into an Android app from scratch. Developing an Android app from scratch requires understanding and coordinating app states, lifecycle management, and asynchronous operations, calling for LLMs to generate context-aware, robust, and maintainable code. To construct APPFORGE, we design a multi-agent system to automatically summarize the main functionalities from app documents and navigate the app to synthesize test cases validating the functional correctness of app implementation. Following rigorous manual verification by Android development experts, APPFORGE incorporates the test cases within an automated evaluation framework that enables reproducible assessment without human intervention, making it easily adoptable for future research. Our evaluation on 12 flagship LLMs show that all evaluated models achieve low effectiveness, with the best-performing model (GPT-5) developing only 18.8% functionally correct applications, highlighting fundamental limitations in current models' ability to handle complex, multi-component software engineering challenges.
SGCL: Unifying Self-Supervised and Supervised Learning for Graph Recommendation
Jul 17, 2025Recommender systems (RecSys) are essential for online platforms, providing personalized suggestions to users within a vast sea of information. Self-supervised graph learning seeks to harness high-order collaborative filtering signals through unsupervised augmentation on the user-item bipartite graph, primarily leveraging a multi-task learning framework that includes both supervised recommendation loss and self-supervised contrastive loss. However, this separate design introduces additional graph convolution processes and creates inconsistencies in gradient directions due to disparate losses, resulting in prolonged training times and sub-optimal performance. In this study, we introduce a unified framework of Supervised Graph Contrastive Learning for recommendation (SGCL) to address these issues. SGCL uniquely combines the training of recommendation and unsupervised contrastive losses into a cohesive supervised contrastive learning loss, aligning both tasks within a single optimization direction for exceptionally fast training. Extensive experiments on three real-world datasets show that SGCL outperforms state-of-the-art methods, achieving superior accuracy and efficiency.
Efficiency Robustness of Dynamic Deep Learning Systems
Jun 12, 2025Deep Learning Systems (DLSs) are increasingly deployed in real-time applications, including those in resourceconstrained environments such as mobile and IoT devices. To address efficiency challenges, Dynamic Deep Learning Systems (DDLSs) adapt inference computation based on input complexity, reducing overhead. While this dynamic behavior improves efficiency, such behavior introduces new attack surfaces. In particular, efficiency adversarial attacks exploit these dynamic mechanisms to degrade system performance. This paper systematically explores efficiency robustness of DDLSs, presenting the first comprehensive taxonomy of efficiency attacks. We categorize these attacks based on three dynamic behaviors: (i) attacks on dynamic computations per inference, (ii) attacks on dynamic inference iterations, and (iii) attacks on dynamic output production for downstream tasks. Through an in-depth evaluation, we analyze adversarial strategies that target DDLSs efficiency and identify key challenges in securing these systems. In addition, we investigate existing defense mechanisms, demonstrating their limitations against increasingly popular efficiency attacks and the necessity for novel mitigation strategies to secure future adaptive DDLSs.
Item Cluster-aware Prompt Learning for Session-based Recommendation
Oct 07, 2024



Session-based recommendation (SBR) aims to capture dynamic user preferences by analyzing item sequences within individual sessions. However, most existing approaches focus mainly on intra-session item relationships, neglecting the connections between items across different sessions (inter-session relationships), which limits their ability to fully capture complex item interactions. While some methods incorporate inter-session information, they often suffer from high computational costs, leading to longer training times and reduced efficiency. To address these challenges, we propose the CLIP-SBR (Cluster-aware Item Prompt learning for Session-Based Recommendation) framework. CLIP-SBR is composed of two modules: 1) an item relationship mining module that builds a global graph to effectively model both intra- and inter-session relationships, and 2) an item cluster-aware prompt learning module that uses soft prompts to integrate these relationships into SBR models efficiently. We evaluate CLIP-SBR across eight SBR models and three benchmark datasets, consistently demonstrating improved recommendation performance and establishing CLIP-SBR as a robust solution for session-based recommendation tasks.
Do We Really Need Graph Convolution During Training? Light Post-Training Graph-ODE for Efficient Recommendation
Jul 29, 2024



The efficiency and scalability of graph convolution networks (GCNs) in training recommender systems (RecSys) have been persistent concerns, hindering their deployment in real-world applications. This paper presents a critical examination of the necessity of graph convolutions during the training phase and introduces an innovative alternative: the Light Post-Training Graph Ordinary-Differential-Equation (LightGODE). Our investigation reveals that the benefits of GCNs are more pronounced during testing rather than training. Motivated by this, LightGODE utilizes a novel post-training graph convolution method that bypasses the computation-intensive message passing of GCNs and employs a non-parametric continuous graph ordinary-differential-equation (ODE) to dynamically model node representations. This approach drastically reduces training time while achieving fine-grained post-training graph convolution to avoid the distortion of the original training embedding space, termed the embedding discrepancy issue. We validate our model across several real-world datasets of different scales, demonstrating that LightGODE not only outperforms GCN-based models in terms of efficiency and effectiveness but also significantly mitigates the embedding discrepancy commonly associated with deeper graph convolution layers. Our LightGODE challenges the prevailing paradigms in RecSys training and suggests re-evaluating the role of graph convolutions, potentially guiding future developments of efficient large-scale graph-based RecSys.
Mixed Supervised Graph Contrastive Learning for Recommendation
Apr 25, 2024



Recommender systems (RecSys) play a vital role in online platforms, offering users personalized suggestions amidst vast information. Graph contrastive learning aims to learn from high-order collaborative filtering signals with unsupervised augmentation on the user-item bipartite graph, which predominantly relies on the multi-task learning framework involving both the pair-wise recommendation loss and the contrastive loss. This decoupled design can cause inconsistent optimization direction from different losses, which leads to longer convergence time and even sub-optimal performance. Besides, the self-supervised contrastive loss falls short in alleviating the data sparsity issue in RecSys as it learns to differentiate users/items from different views without providing extra supervised collaborative filtering signals during augmentations. In this paper, we propose Mixed Supervised Graph Contrastive Learning for Recommendation (MixSGCL) to address these concerns. MixSGCL originally integrates the training of recommendation and unsupervised contrastive losses into a supervised contrastive learning loss to align the two tasks within one optimization direction. To cope with the data sparsity issue, instead unsupervised augmentation, we further propose node-wise and edge-wise mixup to mine more direct supervised collaborative filtering signals based on existing user-item interactions. Extensive experiments on three real-world datasets demonstrate that MixSGCL surpasses state-of-the-art methods, achieving top performance on both accuracy and efficiency. It validates the effectiveness of MixSGCL with our coupled design on supervised graph contrastive learning.
ImplicitAVE: An Open-Source Dataset and Multimodal LLMs Benchmark for Implicit Attribute Value Extraction
Apr 24, 2024



Existing datasets for attribute value extraction (AVE) predominantly focus on explicit attribute values while neglecting the implicit ones, lack product images, are often not publicly available, and lack an in-depth human inspection across diverse domains. To address these limitations, we present ImplicitAVE, the first, publicly available multimodal dataset for implicit attribute value extraction. ImplicitAVE, sourced from the MAVE dataset, is carefully curated and expanded to include implicit AVE and multimodality, resulting in a refined dataset of 68k training and 1.6k testing data across five domains. We also explore the application of multimodal large language models (MLLMs) to implicit AVE, establishing a comprehensive benchmark for MLLMs on the ImplicitAVE dataset. Six recent MLLMs with eleven variants are evaluated across diverse settings, revealing that implicit value extraction remains a challenging task for MLLMs. The contributions of this work include the development and release of ImplicitAVE, and the exploration and benchmarking of various MLLMs for implicit AVE, providing valuable insights and potential future research directions. Dataset and code are available at https://github.com/HenryPengZou/ImplicitAVE
NMTSloth: Understanding and Testing Efficiency Degradation of Neural Machine Translation Systems
Oct 07, 2022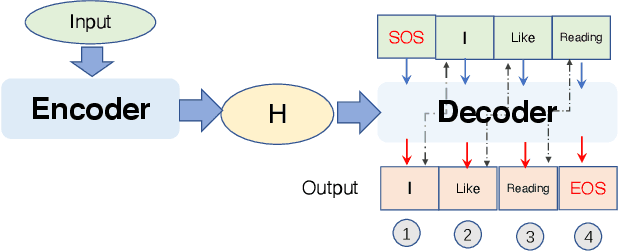

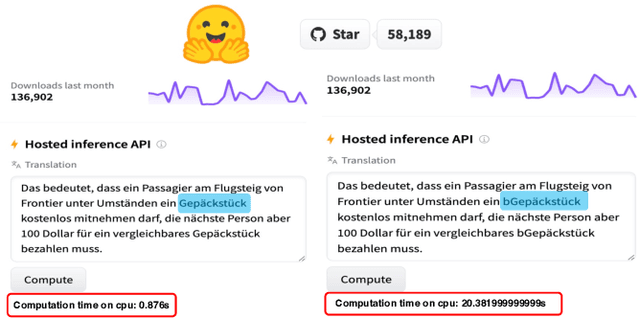
Neural Machine Translation (NMT) systems have received much recent attention due to their human-level accuracy. While existing works mostly focus on either improving accuracy or testing accuracy robustness, the computation efficiency of NMT systems, which is of paramount importance due to often vast translation demands and real-time requirements, has surprisingly received little attention. In this paper, we make the first attempt to understand and test potential computation efficiency robustness in state-of-the-art NMT systems. By analyzing the working mechanism and implementation of 1455 public-accessible NMT systems, we observe a fundamental property in NMT systems that could be manipulated in an adversarial manner to reduce computation efficiency significantly. Our key motivation is to generate test inputs that could sufficiently delay the generation of EOS such that NMT systems would have to go through enough iterations to satisfy the pre-configured threshold. We present NMTSloth, which develops a gradient-guided technique that searches for a minimal and unnoticeable perturbation at character-level, token-level, and structure-level, which sufficiently delays the appearance of EOS and forces these inputs to reach the naturally-unreachable threshold. To demonstrate the effectiveness of NMTSloth, we conduct a systematic evaluation on three public-available NMT systems: Google T5, AllenAI WMT14, and Helsinki-NLP translators. Experimental results show that NMTSloth can increase NMT systems' response latency and energy consumption by 85% to 3153% and 86% to 3052%, respectively, by perturbing just one character or token in the input sentence. Our case study shows that inputs generated by NMTSloth significantly affect the battery power in real-world mobile devices (i.e., drain more than 30 times battery power than normal inputs).