 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Hallucinations in Graph Retrieval-Augmented Generation via Attention Patterns and Semantic Alignment
Dec 09, 2025Graph-based Retrieval-Augmented Generation (GraphRAG) enhances Large Language Models (LLMs) by incorporating external knowledge from linearized subgraphs retrieved from knowledge graphs. However, LLMs struggle to interpret the relational and topological information in these inputs, resulting in hallucinations that are inconsistent with the retrieved knowledge. To analyze how LLMs attend to and retain structured knowledge during generation, we propose two lightweight interpretability metrics: Path Reliance Degree (PRD), which measures over-reliance on shortest-path triples, and Semantic Alignment Score (SAS), which assesses how well the model's internal representations align with the retrieved knowledge. Through empirical analysis on a knowledge-based QA task, we identify failure patterns associated with over-reliance on salient paths and weak semantic grounding, as indicated by high PRD and low SAS scores. We further develop a lightweight post-hoc hallucination detector, Graph Grounding and Alignment (GGA), which outperforms strong semantic and confidence-based baselines across AUC and F1. By grounding hallucination analysis in mechanistic interpretability, our work offers insights into how structural limitations in LLMs contribute to hallucinations, informing the design of more reliable GraphRAG systems in the future.
LLM-MemCluster: Empowering Large Language Models with Dynamic Memory for Text Clustering
Nov 19, 2025Large Language Models (LLMs) are reshaping unsupervised learning by offering an unprecedented ability to perform text clustering based on their deep semantic understanding. However, their direct application is fundamentally limited by a lack of stateful memory for iterative refinement and the difficulty of managing cluster granularity. As a result, existing methods often rely on complex pipelines with external modules, sacrificing a truly end-to-end approach. We introduce LLM-MemCluster, a novel framework that reconceptualizes clustering as a fully LLM-native task. It leverages a Dynamic Memory to instill state awareness and a Dual-Prompt Strategy to enable the model to reason about and determine the number of clusters. Evaluated on several benchmark datasets, our tuning-free framework significantly and consistently outperforms strong baselines. LLM-MemCluster presents an effective, interpretable, and truly end-to-end paradigm for LLM-based text clustering.
SGCL: Unifying Self-Supervised and Supervised Learning for Graph Recommendation
Jul 17, 2025Recommender systems (RecSys) are essential for online platforms, providing personalized suggestions to users within a vast sea of information. Self-supervised graph learning seeks to harness high-order collaborative filtering signals through unsupervised augmentation on the user-item bipartite graph, primarily leveraging a multi-task learning framework that includes both supervised recommendation loss and self-supervised contrastive loss. However, this separate design introduces additional graph convolution processes and creates inconsistencies in gradient directions due to disparate losses, resulting in prolonged training times and sub-optimal performance. In this study, we introduce a unified framework of Supervised Graph Contrastive Learning for recommendation (SGCL) to address these issues. SGCL uniquely combines the training of recommendation and unsupervised contrastive losses into a cohesive supervised contrastive learning loss, aligning both tasks within a single optimization direction for exceptionally fast training. Extensive experiments on three real-world datasets show that SGCL outperforms state-of-the-art methods, achieving superior accuracy and efficiency.
Mixed Supervised Graph Contrastive Learning for Recommendation
Apr 25, 2024



Recommender systems (RecSys) play a vital role in online platforms, offering users personalized suggestions amidst vast information. Graph contrastive learning aims to learn from high-order collaborative filtering signals with unsupervised augmentation on the user-item bipartite graph, which predominantly relies on the multi-task learning framework involving both the pair-wise recommendation loss and the contrastive loss. This decoupled design can cause inconsistent optimization direction from different losses, which leads to longer convergence time and even sub-optimal performance. Besides, the self-supervised contrastive loss falls short in alleviating the data sparsity issue in RecSys as it learns to differentiate users/items from different views without providing extra supervised collaborative filtering signals during augmentations. In this paper, we propose Mixed Supervised Graph Contrastive Learning for Recommendation (MixSGCL) to address these concerns. MixSGCL originally integrates the training of recommendation and unsupervised contrastive losses into a supervised contrastive learning loss to align the two tasks within one optimization direction. To cope with the data sparsity issue, instead unsupervised augmentation, we further propose node-wise and edge-wise mixup to mine more direct supervised collaborative filtering signals based on existing user-item interactions. Extensive experiments on three real-world datasets demonstrate that MixSGCL surpasses state-of-the-art methods, achieving top performance on both accuracy and efficiency. It validates the effectiveness of MixSGCL with our coupled design on supervised graph contrastive learning.
Graph Neural Ordinary Differential Equations-based method for Collaborative Filtering
Nov 21, 2023



Graph Convolution Networks (GCNs) are widely considered state-of-the-art for collaborative filtering. Although several GCN-based methods have been proposed and achieved state-of-the-art performance in various tasks, they can be computationally expensive and time-consuming to train if too many layers are created. However, since the linear GCN model can be interpreted as a differential equation, it is possible to transfer it to an ODE problem. This inspired us to address the computational limitations of GCN-based models by designing a simple and efficient NODE-based model that can skip some GCN layers to reach the final state, thus avoiding the need to create many layers. In this work, we propose a Graph Neural Ordinary Differential Equation-based method for Collaborative Filtering (GODE-CF). This method estimates the final embedding by utilizing the information captured by one or two GCN layers. To validate our approach, we conducted experiments on multiple datasets. The results demonstrate that our model outperforms competitive baselines, including GCN-based models and other state-of-the-art CF methods. Notably, our proposed GODE-CF model has several advantages over traditional GCN-based models. It is simple, efficient, and has a fast training time, making it a practical choice for real-world situations.
Automatic Streaming Segmentation of Stereo Video Using Bilateral Space
Nov 28, 2017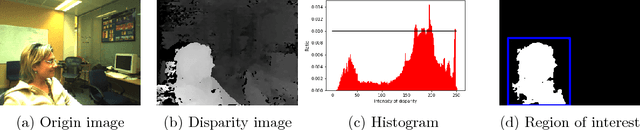
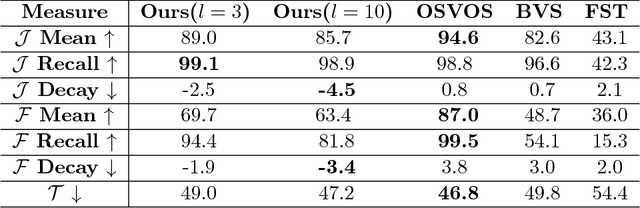


In this paper, we take advantage of binocular camera and propose an unsupervised algorithm based on semi-supervised segmentation algorithm and extracting foreground part efficiently. We creatively embed depth information into bilateral grid in the graph cut model and achieve considerable segmenting accuracy in the case of no user input. The experi- ment approves the high precision, time efficiency of our algorithm and its adaptation to complex natural scenario which is significant for practical application.