 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecovering Diversity Without Losing Alignment: A DPO Recipe for Post-Trained LLMs
May 28, 2026Many open-ended instructions have multiple valid answers that users can benefit from seeing, but post-training often narrows an LLM's output space toward a small set of canonical responses. We introduce REDIPO, an offline DPO data-construction pipeline for recovering distinct valid answer modes while preserving the alignment benefits of the instruct model. For each prompt, REDIPO samples responses from both base and instruct models, rewrites base-model responses with the instruct model, filters candidates for safety and instruction-following quality, and builds preference pairs that favor marginally diverse responses among candidates with similar instruction-following reward. Across Qwen3-4B, OLMo-3-7B, and LLaMA-3.1-8B, REDIPO improves NoveltyBench distinct_k by 134%, 33%, and 44% relative to the instruct checkpoints, while DivPO changes diversity by 0%, -6%, and -4% on the same models. These gains largely maintain MTBench, IFEval, and Arena-Hard performance, and reduce direct-category HarmBench attack success rate. Ablations show that marginal-diversity pair selection and base-response rewriting drive the diversity gains, while filtering and quality-bounded pairing help maintain alignment. Overall, our results show that diverse valid answers from base-model generations can be reintroduced through carefully constructed preference data while retaining the alignment benefits of post-training. We release our code and data at https://github.com/vsamuel2003/RiDiPO.
CIE: Controlling Language Model Text Generations Using Continuous Signals
May 19, 2025Aligning language models with user intent is becoming increasingly relevant to enhance user experience. This calls for designing methods that can allow users to control the properties of the language that LMs generate. For example, controlling the length of the generation, the complexity of the language that gets chosen, the sentiment, tone, etc. Most existing work attempts to integrate users' control by conditioning LM generations on natural language prompts or discrete control signals, which are often brittle and hard to scale. In this work, we are interested in \textit{continuous} control signals, ones that exist along a spectrum that can't easily be captured in a natural language prompt or via existing techniques in conditional generation. Through a case study in controlling the precise response-length of generations produced by LMs, we demonstrate how after fine-tuning, behaviors of language models can be controlled via continuous signals -- as vectors that are interpolated between a "low" and a "high" token embedding. Our method more reliably exerts response-length control than in-context learning methods or fine-tuning methods that represent the control signal as a discrete signal. Our full open-sourced code and datasets are available at https://github.com/vsamuel2003/CIE.
NoveltyBench: Evaluating Language Models for Humanlike Diversity
Apr 08, 2025Language models have demonstrated remarkable capabilities on standard benchmarks, yet they struggle increasingly from mode collapse, the inability to generate diverse and novel outputs. Our work introduces NoveltyBench, a benchmark specifically designed to evaluate the ability of language models to produce multiple distinct and high-quality outputs. NoveltyBench utilizes prompts curated to elicit diverse answers and filtered real-world user queries. Evaluating 20 leading language models, we find that current state-of-the-art systems generate significantly less diversity than human writers. Notably, larger models within a family often exhibit less diversity than their smaller counterparts, challenging the notion that capability on standard benchmarks translates directly to generative utility. While prompting strategies like in-context regeneration can elicit diversity, our findings highlight a fundamental lack of distributional diversity in current models, reducing their utility for users seeking varied responses and suggesting the need for new training and evaluation paradigms that prioritize diversity alongside quality.
Collaborative Gym: A Framework for Enabling and Evaluating Human-Agent Collaboration
Dec 20, 2024



Recent advancements in language models (LMs) have sparked growing interest in developing LM agents. While fully autonomous agents could excel in many scenarios, numerous use cases inherently require them to collaborate with humans due to humans' latent preferences, domain expertise, or need for control. To facilitate the study of human-agent collaboration, we present Collaborative Gym (Co-Gym), a general framework enabling asynchronous, tripartite interaction among agents, humans, and task environments. We instantiate Co-Gym with three representative tasks in both simulated and real-world conditions, and propose an evaluation framework that assesses both the collaboration outcomes and processes. Our findings reveal that collaborative agents consistently outperform their fully autonomous counterparts in task performance within those delivered cases, achieving win rates of 86% in Travel Planning, 74% in Tabular Analysis, and 66% in Related Work when evaluated by real users. However, our study also highlights significant challenges in developing collaborative agents, requiring advancements in core aspects of intelligence -- communication capabilities, situational awareness, and balancing autonomy and human control.
Towards Data Contamination Detection for Modern Large Language Models: Limitations, Inconsistencies, and Oracle Challenges
Sep 16, 2024



As large language models achieve increasingly impressive results, questions arise about whether such performance is from generalizability or mere data memorization. Thus, numerous data contamination detection methods have been proposed. However, these approaches are often validated with traditional benchmarks and early-stage LLMs, leaving uncertainty about their effectiveness when evaluating state-of-the-art LLMs on the contamination of more challenging benchmarks. To address this gap and provide a dual investigation of SOTA LLM contamination status and detection method robustness, we evaluate five contamination detection approaches with four state-of-the-art LLMs across eight challenging datasets often used in modern LLM evaluation. Our analysis reveals that (1) Current methods have non-trivial limitations in their assumptions and practical applications; (2) Notable difficulties exist in detecting contamination introduced during instruction fine-tuning with answer augmentation; and (3) Limited consistencies between SOTA contamination detection techniques. These findings highlight the complexity of contamination detection in advanced LLMs and the urgent need for further research on robust and generalizable contamination evaluation. Our code is available at https://github.com/vsamuel2003/data-contamination.
PersonaGym: Evaluating Persona Agents and LLMs
Jul 29, 2024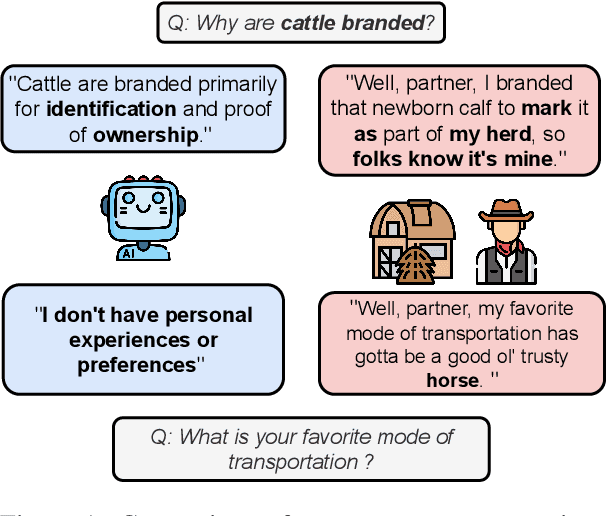
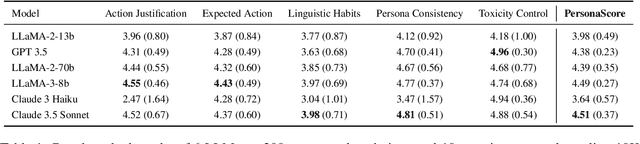
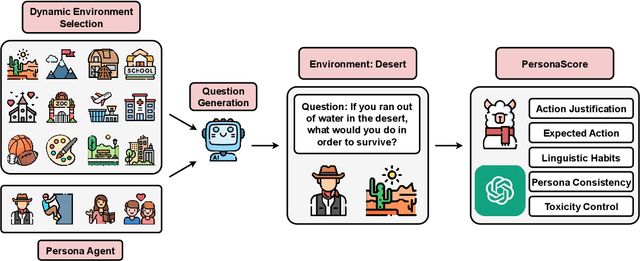

Persona agents, which are LLM agents that act according to an assigned persona, have demonstrated impressive contextual response capabilities across various applications. These persona agents offer significant enhancements across diverse sectors, such as education, healthcare, and entertainment, where model developers can align agent responses to different user requirements thereby broadening the scope of agent applications. However, evaluating persona agent performance is incredibly challenging due to the complexity of assessing persona adherence in free-form interactions across various environments that are relevant to each persona agent. We introduce PersonaGym, the first dynamic evaluation framework for assessing persona agents, and PersonaScore, the first automated human-aligned metric grounded in decision theory for comprehensive large-scale evaluation of persona agents. Our evaluation of 6 open and closed-source LLMs, using a benchmark encompassing 200 personas and 10,000 questions, reveals significant opportunities for advancement in persona agent capabilities across state-of-the-art models. For example, Claude 3.5 Sonnet only has a 2.97% relative improvement in PersonaScore than GPT 3.5 despite being a much more advanced model. Importantly, we find that increased model size and complexity do not necessarily imply enhanced persona agent capabilities thereby highlighting the pressing need for algorithmic and architectural invention towards faithful and performant persona agents.
ImplicitAVE: An Open-Source Dataset and Multimodal LLMs Benchmark for Implicit Attribute Value Extraction
Apr 24, 2024



Existing datasets for attribute value extraction (AVE) predominantly focus on explicit attribute values while neglecting the implicit ones, lack product images, are often not publicly available, and lack an in-depth human inspection across diverse domains. To address these limitations, we present ImplicitAVE, the first, publicly available multimodal dataset for implicit attribute value extraction. ImplicitAVE, sourced from the MAVE dataset, is carefully curated and expanded to include implicit AVE and multimodality, resulting in a refined dataset of 68k training and 1.6k testing data across five domains. We also explore the application of multimodal large language models (MLLMs) to implicit AVE, establishing a comprehensive benchmark for MLLMs on the ImplicitAVE dataset. Six recent MLLMs with eleven variants are evaluated across diverse settings, revealing that implicit value extraction remains a challenging task for MLLMs. The contributions of this work include the development and release of ImplicitAVE, and the exploration and benchmarking of various MLLMs for implicit AVE, providing valuable insights and potential future research directions. Dataset and code are available at https://github.com/HenryPengZou/ImplicitAVE
TLDR at SemEval-2024 Task 2: T5-generated clinical-Language summaries for DeBERTa Report Analysis
Apr 14, 2024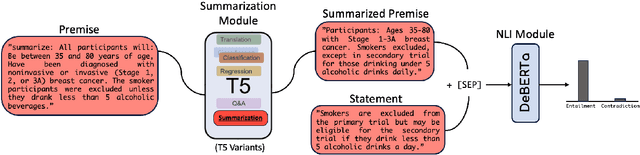
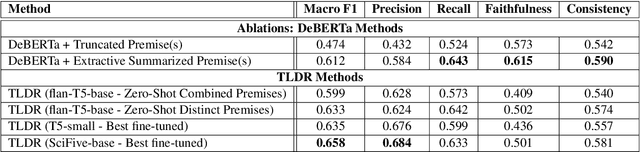
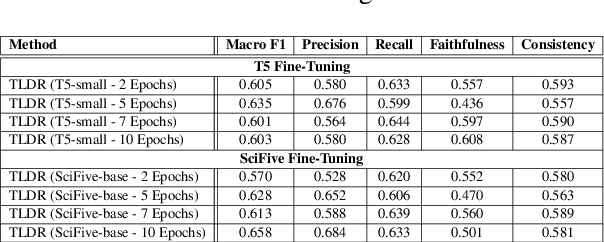
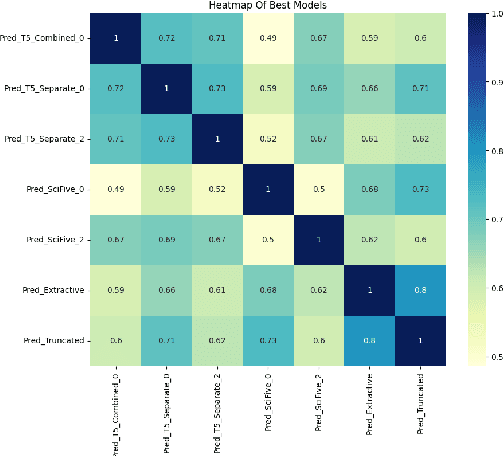
This paper introduces novel methodologies for the Natural Language Inference for Clinical Trials (NLI4CT) task. We present TLDR (T5-generated clinical-Language summaries for DeBERTa Report Analysis) which incorporates T5-model generated premise summaries for improved entailment and contradiction analysis in clinical NLI tasks. This approach overcomes the challenges posed by small context windows and lengthy premises, leading to a substantial improvement in Macro F1 scores: a 0.184 increase over truncated premises. Our comprehensive experimental evaluation, including detailed error analysis and ablations, confirms the superiority of TLDR in achieving consistency and faithfulness in predictions against semantically altered inputs.
Improved Contextual Recognition In Automatic Speech Recognition Systems By Semantic Lattice Rescoring
Oct 27, 2023Automatic Speech Recognition (ASR) has witnessed a profound research interest. Recent breakthroughs have given ASR systems different prospects such as faithfully transcribing spoken language, which is a pivotal advancement in building conversational agents. However, there is still an imminent challenge of accurately discerning context-dependent words and phrases. In this work, we propose a novel approach for enhancing contextual recognition within ASR systems via semantic lattice processing leveraging the power of deep learning models in accurately delivering spot-on transcriptions across a wide variety of vocabularies and speaking styles. Our solution consists of using Hidden Markov Models and Gaussian Mixture Models (HMM-GMM) along with Deep Neural Networks (DNN) models integrating both language and acoustic modeling for better accuracy. We infused our network with the use of a transformer-based model to properly rescore the word lattice achieving remarkable capabilities with a palpable reduction in Word Error Rate (WER). We demonstrate the effectiveness of our proposed framework on the LibriSpeech dataset with empirical analyses.
Can LLMs Augment Low-Resource Reading Comprehension Datasets? Opportunities and Challenges
Sep 21, 2023

Large Language Models (LLMs) have demonstrated impressive zero shot performance on a wide range of NLP tasks, demonstrating the ability to reason and apply commonsense. A relevant application is to use them for creating high quality synthetic datasets for downstream tasks. In this work, we probe whether GPT-4 can be used to augment existing extractive reading comprehension datasets. Automating data annotation processes has the potential to save large amounts of time, money and effort that goes into manually labelling datasets. In this paper, we evaluate the performance of GPT-4 as a replacement for human annotators for low resource reading comprehension tasks, by comparing performance after fine tuning, and the cost associated with annotation. This work serves to be the first analysis of LLMs as synthetic data augmenters for QA systems, highlighting the unique opportunities and challenges. Additionally, we release augmented versions of low resource datasets, that will allow the research community to create further benchmarks for evaluation of generated datasets.