 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSource-Free Domain Adaptation with Diffusion-Guided Source Data Generation
Feb 07, 2024



This paper introduces a novel approach to leverage the generalizability capability of Diffusion Models for Source-Free Domain Adaptation (DM-SFDA). Our proposed DM-SFDA method involves fine-tuning a pre-trained text-to-image diffusion model to generate source domain images using features from the target images to guide the diffusion process. Specifically, the pre-trained diffusion model is fine-tuned to generate source samples that minimize entropy and maximize confidence for the pre-trained source model. We then apply established unsupervised domain adaptation techniques to align the generated source images with target domain data. We validate our approach through comprehensive experiments across a range of datasets, including Office-31, Office-Home, and VisDA. The results highlight significant improvements in SFDA performance, showcasing the potential of diffusion models in generating contextually relevant, domain-specific images.
Transcending Domains through Text-to-Image Diffusion: A Source-Free Approach to Domain Adaptation
Oct 14, 2023
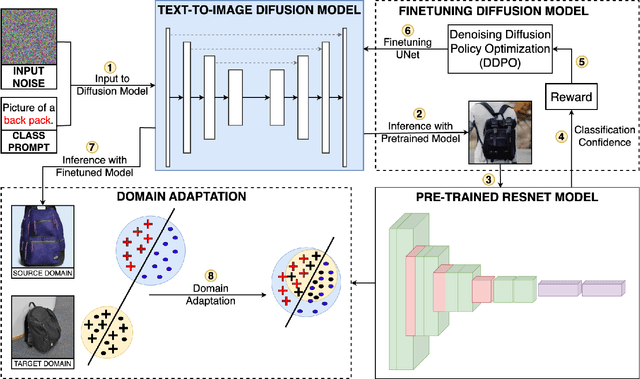

Domain Adaptation (DA) is a method for enhancing a model's performance on a target domain with inadequate annotated data by applying the information the model has acquired from a related source domain with sufficient labeled data. The escalating enforcement of data-privacy regulations like HIPAA, COPPA, FERPA, etc. have sparked a heightened interest in adapting models to novel domains while circumventing the need for direct access to the source data, a problem known as Source-Free Domain Adaptation (SFDA). In this paper, we propose a novel framework for SFDA that generates source data using a text-to-image diffusion model trained on the target domain samples. Our method starts by training a text-to-image diffusion model on the labeled target domain samples, which is then fine-tuned using the pre-trained source model to generate samples close to the source data. Finally, we use Domain Adaptation techniques to align the artificially generated source data with the target domain data, resulting in significant performance improvements of the model on the target domain. Through extensive comparison against several baselines on the standard Office-31, Office-Home, and VisDA benchmarks, we demonstrate the effectiveness of our approach for the SFDA task.
Can LLMs Augment Low-Resource Reading Comprehension Datasets? Opportunities and Challenges
Sep 21, 2023

Large Language Models (LLMs) have demonstrated impressive zero shot performance on a wide range of NLP tasks, demonstrating the ability to reason and apply commonsense. A relevant application is to use them for creating high quality synthetic datasets for downstream tasks. In this work, we probe whether GPT-4 can be used to augment existing extractive reading comprehension datasets. Automating data annotation processes has the potential to save large amounts of time, money and effort that goes into manually labelling datasets. In this paper, we evaluate the performance of GPT-4 as a replacement for human annotators for low resource reading comprehension tasks, by comparing performance after fine tuning, and the cost associated with annotation. This work serves to be the first analysis of LLMs as synthetic data augmenters for QA systems, highlighting the unique opportunities and challenges. Additionally, we release augmented versions of low resource datasets, that will allow the research community to create further benchmarks for evaluation of generated datasets.