 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranscending Domains through Text-to-Image Diffusion: A Source-Free Approach to Domain Adaptation
Paper and Code
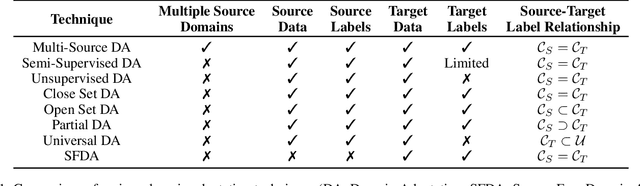
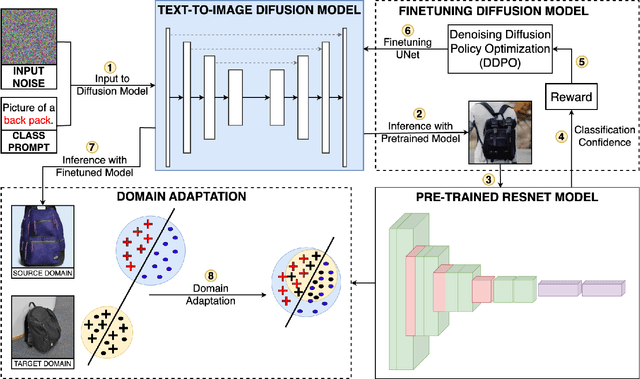

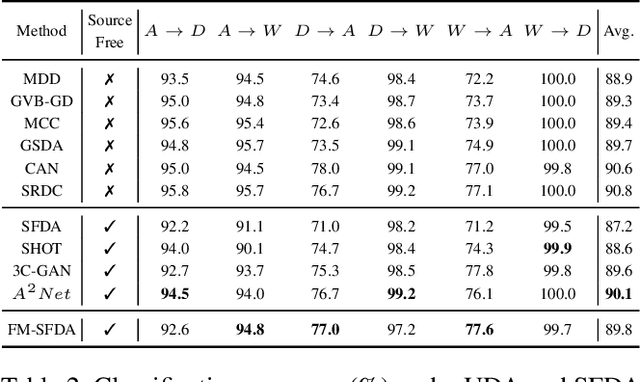
Domain Adaptation (DA) is a method for enhancing a model's performance on a target domain with inadequate annotated data by applying the information the model has acquired from a related source domain with sufficient labeled data. The escalating enforcement of data-privacy regulations like HIPAA, COPPA, FERPA, etc. have sparked a heightened interest in adapting models to novel domains while circumventing the need for direct access to the source data, a problem known as Source-Free Domain Adaptation (SFDA). In this paper, we propose a novel framework for SFDA that generates source data using a text-to-image diffusion model trained on the target domain samples. Our method starts by training a text-to-image diffusion model on the labeled target domain samples, which is then fine-tuned using the pre-trained source model to generate samples close to the source data. Finally, we use Domain Adaptation techniques to align the artificially generated source data with the target domain data, resulting in significant performance improvements of the model on the target domain. Through extensive comparison against several baselines on the standard Office-31, Office-Home, and VisDA benchmarks, we demonstrate the effectiveness of our approach for the SFDA task.