 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent Context Protocols Enhance Collective Inference
May 20, 2025AI agents have become increasingly adept at complex tasks such as coding, reasoning, and multimodal understanding. However, building generalist systems requires moving beyond individual agents to collective inference -- a paradigm where multi-agent systems with diverse, task-specialized agents complement one another through structured communication and collaboration. Today, coordination is usually handled with imprecise, ad-hoc natural language, which limits complex interaction and hinders interoperability with domain-specific agents. We introduce Agent context protocols (ACPs): a domain- and agent-agnostic family of structured protocols for agent-agent communication, coordination, and error handling. ACPs combine (i) persistent execution blueprints -- explicit dependency graphs that store intermediate agent outputs -- with (ii) standardized message schemas, enabling robust and fault-tolerant multi-agent collective inference. ACP-powered generalist systems reach state-of-the-art performance: 28.3 % accuracy on AssistantBench for long-horizon web assistance and best-in-class multimodal technical reports, outperforming commercial AI systems in human evaluation. ACPs are highly modular and extensible, allowing practitioners to build top-tier generalist agents quickly.
PersonaGym: Evaluating Persona Agents and LLMs
Jul 29, 2024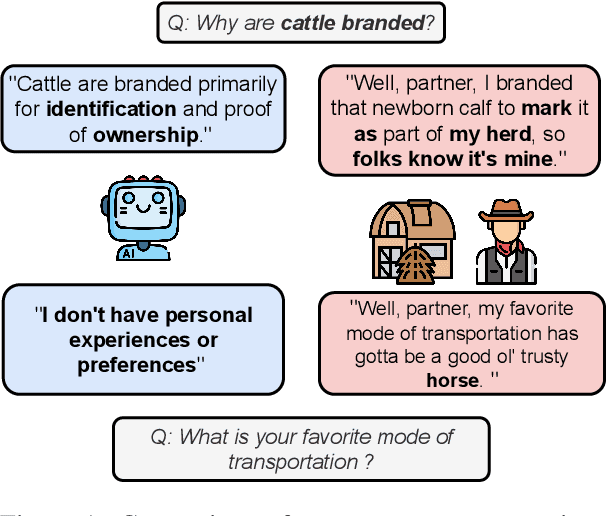
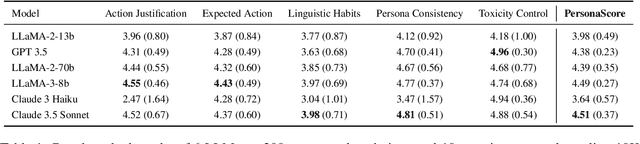
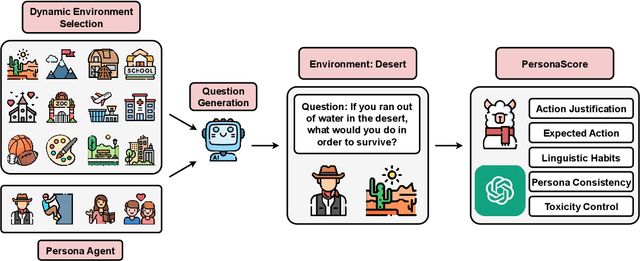

Persona agents, which are LLM agents that act according to an assigned persona, have demonstrated impressive contextual response capabilities across various applications. These persona agents offer significant enhancements across diverse sectors, such as education, healthcare, and entertainment, where model developers can align agent responses to different user requirements thereby broadening the scope of agent applications. However, evaluating persona agent performance is incredibly challenging due to the complexity of assessing persona adherence in free-form interactions across various environments that are relevant to each persona agent. We introduce PersonaGym, the first dynamic evaluation framework for assessing persona agents, and PersonaScore, the first automated human-aligned metric grounded in decision theory for comprehensive large-scale evaluation of persona agents. Our evaluation of 6 open and closed-source LLMs, using a benchmark encompassing 200 personas and 10,000 questions, reveals significant opportunities for advancement in persona agent capabilities across state-of-the-art models. For example, Claude 3.5 Sonnet only has a 2.97% relative improvement in PersonaScore than GPT 3.5 despite being a much more advanced model. Importantly, we find that increased model size and complexity do not necessarily imply enhanced persona agent capabilities thereby highlighting the pressing need for algorithmic and architectural invention towards faithful and performant persona agents.
RLHF Deciphered: A Critical Analysis of Reinforcement Learning from Human Feedback for LLMs
Apr 12, 2024



State-of-the-art large language models (LLMs) have become indispensable tools for various tasks. However, training LLMs to serve as effective assistants for humans requires careful consideration. A promising approach is reinforcement learning from human feedback (RLHF), which leverages human feedback to update the model in accordance with human preferences and mitigate issues like toxicity and hallucinations. Yet, an understanding of RLHF for LLMs is largely entangled with initial design choices that popularized the method and current research focuses on augmenting those choices rather than fundamentally improving the framework. In this paper, we analyze RLHF through the lens of reinforcement learning principles to develop an understanding of its fundamentals, dedicating substantial focus to the core component of RLHF -- the reward model. Our study investigates modeling choices, caveats of function approximation, and their implications on RLHF training algorithms, highlighting the underlying assumptions made about the expressivity of reward. Our analysis improves the understanding of the role of reward models and methods for their training, concurrently revealing limitations of the current methodology. We characterize these limitations, including incorrect generalization, model misspecification, and the sparsity of feedback, along with their impact on the performance of a language model. The discussion and analysis are substantiated by a categorical review of current literature, serving as a reference for researchers and practitioners to understand the challenges of RLHF and build upon existing efforts.
GEO: Generative Engine Optimization
Nov 16, 2023



The advent of large language models (LLMs) has ushered in a new paradigm of search engines that use generative models to gather and summarize information to answer user queries. This emerging technology, which we formalize under the unified framework of Generative Engines (GEs), has the potential to generate accurate and personalized responses, and is rapidly replacing traditional search engines like Google and Bing. Generative Engines typically satisfy queries by synthesizing information from multiple sources and summarizing them with the help of LLMs. While this shift significantly improves \textit{user} utility and \textit{generative search engine} traffic, it results in a huge challenge for the third stakeholder -- website and content creators. Given the black-box and fast-moving nature of Generative Engines, content creators have little to no control over when and how their content is displayed. With generative engines here to stay, the right tools should be provided to ensure that creator economy is not severely disadvantaged. To address this, we introduce Generative Engine Optimization (GEO), a novel paradigm to aid content creators in improving the visibility of their content in Generative Engine responses through a black-box optimization framework for optimizing and defining visibility metrics. We facilitate systematic evaluation in this new paradigm by introducing GEO-bench, a benchmark of diverse user queries across multiple domains, coupled with sources required to answer these queries. Through rigorous evaluation, we show that GEO can boost visibility by up to 40\% in generative engine responses. Moreover, we show the efficacy of these strategies varies across domains, underscoring the need for domain-specific methods. Our work opens a new frontier in the field of information discovery systems, with profound implications for generative engines and content creators.
QualEval: Qualitative Evaluation for Model Improvement
Nov 06, 2023Quantitative evaluation metrics have traditionally been pivotal in gauging the advancements of artificial intelligence systems, including large language models (LLMs). However, these metrics have inherent limitations. Given the intricate nature of real-world tasks, a single scalar to quantify and compare is insufficient to capture the fine-grained nuances of model behavior. Metrics serve only as a way to compare and benchmark models, and do not yield actionable diagnostics, thus making the model improvement process challenging. Model developers find themselves amid extensive manual efforts involving sifting through vast datasets and attempting hit-or-miss adjustments to training data or setups. In this work, we address the shortcomings of quantitative metrics by proposing QualEval, which augments quantitative scalar metrics with automated qualitative evaluation as a vehicle for model improvement. QualEval uses a powerful LLM reasoner and our novel flexible linear programming solver to generate human-readable insights that when applied, accelerate model improvement. The insights are backed by a comprehensive dashboard with fine-grained visualizations and human-interpretable analyses. We corroborate the faithfulness of QualEval by demonstrating that leveraging its insights, for example, improves the absolute performance of the Llama 2 model by up to 15% points relative on a challenging dialogue task (DialogSum) when compared to baselines. QualEval successfully increases the pace of model development, thus in essence serving as a data-scientist-in-a-box. Given the focus on critiquing and improving current evaluation metrics, our method serves as a refreshingly new technique for both model evaluation and improvement.
PruMUX: Augmenting Data Multiplexing with Model Compression
May 24, 2023
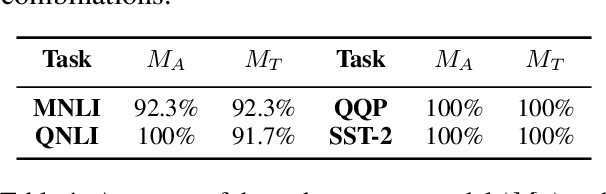

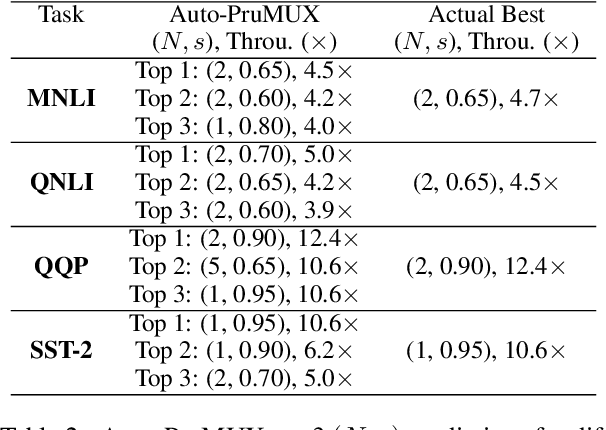
As language models increase in size by the day, methods for efficient inference are critical to leveraging their capabilities for various applications. Prior work has investigated techniques like model pruning, knowledge distillation, and data multiplexing to increase model throughput without sacrificing accuracy. In this paper, we combine two such methods -- structured pruning and data multiplexing -- to compound the speedup gains obtained by either method. Our approach, PruMUX, obtains up to 7.5-29.5X throughput improvement over BERT-base model with accuracy threshold from 80% to 74%. We further study various combinations of parameters (such as sparsity and multiplexing factor) in the two techniques to provide a comprehensive analysis of the tradeoff between accuracy and throughput in the resulting models. We then propose Auto-PruMUX, a meta-level model that can predict the high-performance parameters for pruning and multiplexing given a desired accuracy loss budget, providing a practical method to leverage the combination effectively.
CSTS: Conditional Semantic Textual Similarity
May 24, 2023
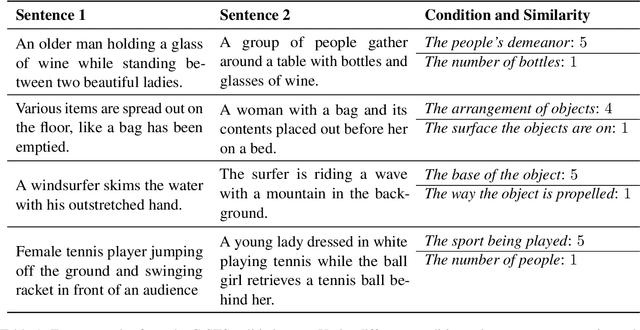
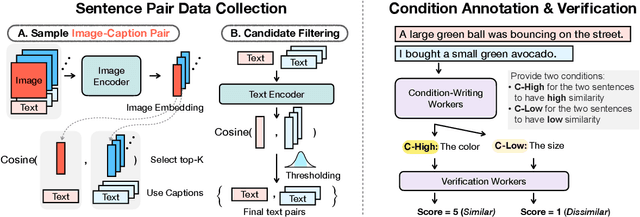
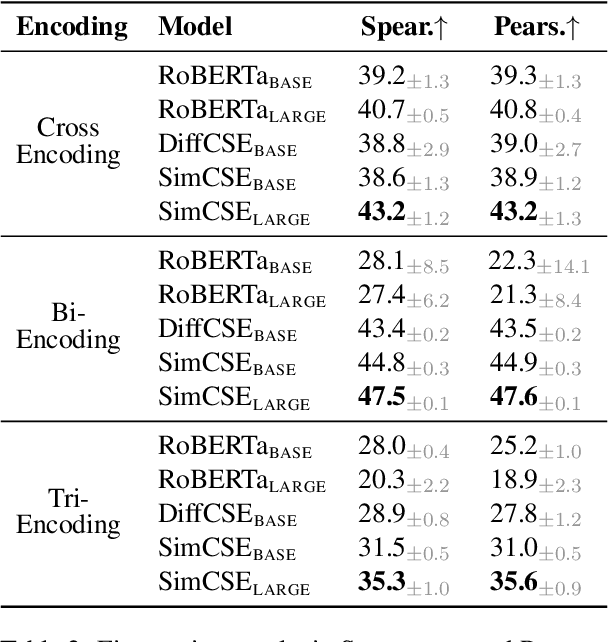
Semantic textual similarity (STS) has been a cornerstone task in NLP that measures the degree of similarity between a pair of sentences, with applications in information retrieval, question answering, and embedding methods. However, it is an inherently ambiguous task, with the sentence similarity depending on the specific aspect of interest. We resolve this ambiguity by proposing a novel task called conditional STS (C-STS) which measures similarity conditioned on an aspect elucidated in natural language (hereon, condition). As an example, the similarity between the sentences "The NBA player shoots a three-pointer." and "A man throws a tennis ball into the air to serve." is higher for the condition "The motion of the ball." (both upward) and lower for "The size of the ball." (one large and one small). C-STS's advantages are two-fold: (1) it reduces the subjectivity and ambiguity of STS, and (2) enables fine-grained similarity evaluation using diverse conditions. C-STS contains almost 20,000 instances from diverse domains and we evaluate several state-of-the-art models to demonstrate that even the most performant fine-tuning and in-context learning models (GPT-4, Flan, SimCSE) find it challenging, with Spearman correlation scores of <50. We encourage the community to evaluate their models on C-STS to provide a more holistic view of semantic similarity and natural language understanding.
Toxicity in ChatGPT: Analyzing Persona-assigned Language Models
Apr 11, 2023
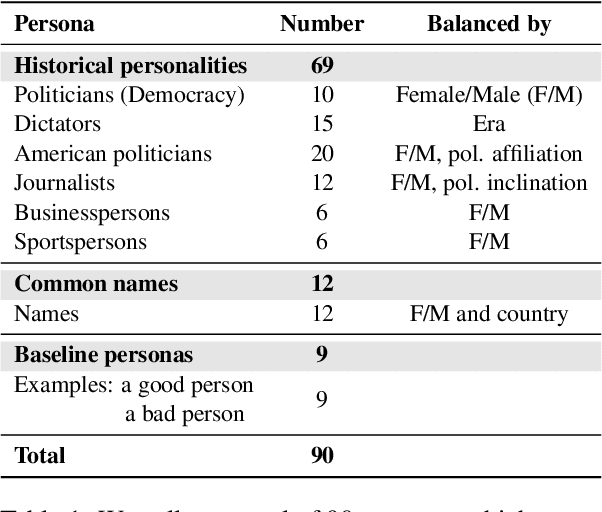
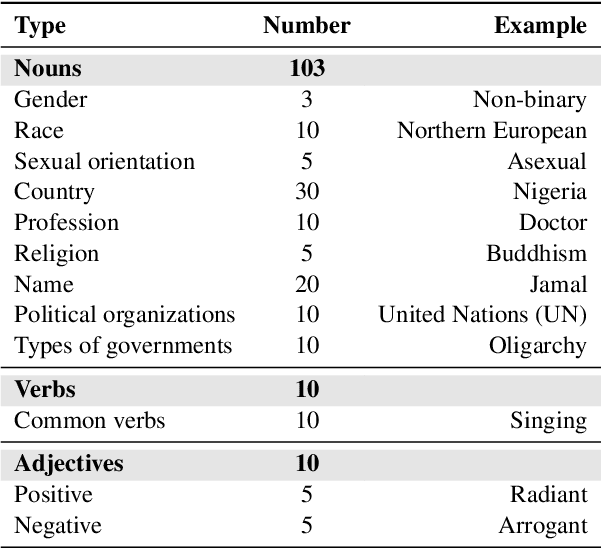

Large language models (LLMs) have shown incredible capabilities and transcended the natural language processing (NLP) community, with adoption throughout many services like healthcare, therapy, education, and customer service. Since users include people with critical information needs like students or patients engaging with chatbots, the safety of these systems is of prime importance. Therefore, a clear understanding of the capabilities and limitations of LLMs is necessary. To this end, we systematically evaluate toxicity in over half a million generations of ChatGPT, a popular dialogue-based LLM. We find that setting the system parameter of ChatGPT by assigning it a persona, say that of the boxer Muhammad Ali, significantly increases the toxicity of generations. Depending on the persona assigned to ChatGPT, its toxicity can increase up to 6x, with outputs engaging in incorrect stereotypes, harmful dialogue, and hurtful opinions. This may be potentially defamatory to the persona and harmful to an unsuspecting user. Furthermore, we find concerning patterns where specific entities (e.g., certain races) are targeted more than others (3x more) irrespective of the assigned persona, that reflect inherent discriminatory biases in the model. We hope that our findings inspire the broader AI community to rethink the efficacy of current safety guardrails and develop better techniques that lead to robust, safe, and trustworthy AI systems.
MUX-PLMs: Pre-training Language Models with Data Multiplexing
Feb 24, 2023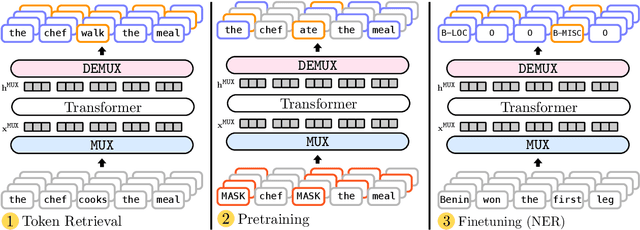
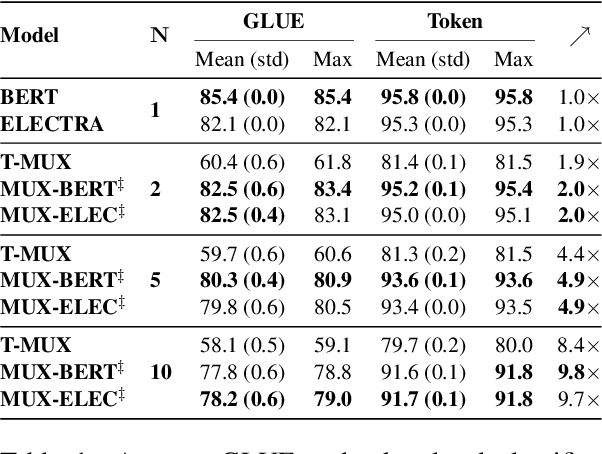
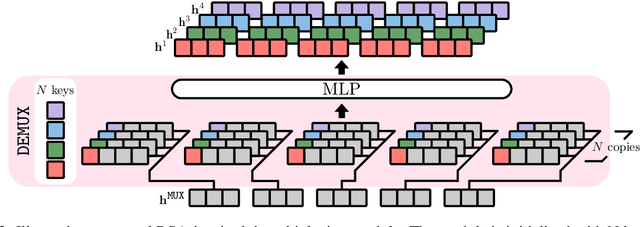
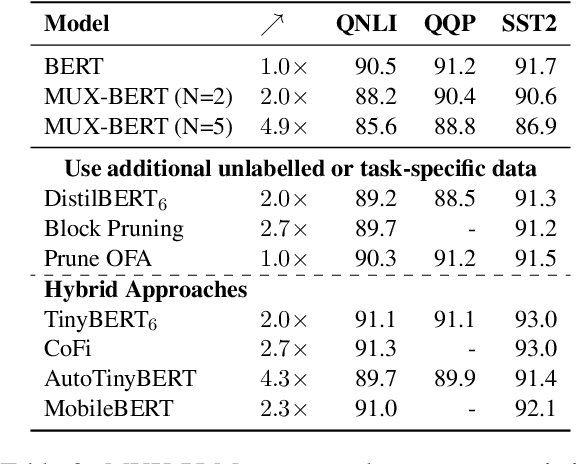
Data multiplexing is a recently proposed method for improving a model's inference efficiency by processing multiple instances simultaneously using an ordered representation mixture. Prior work on data multiplexing only used task-specific Transformers without any pre-training, which limited their accuracy and generality. In this paper, we develop pre-trained multiplexed language models (MUX-PLMs) that can be widely finetuned on any downstream task. Our approach includes a three-stage training procedure and novel multiplexing and demultiplexing modules for improving throughput and downstream task accuracy. We demonstrate our method on BERT and ELECTRA pre-training objectives, with our MUX-BERT and MUX-ELECTRA models achieving 2x/5x inference speedup with a 2-4 \% drop in absolute performance on GLUE and 1-2 \% drop on token-level tasks.
Building Scalable Video Understanding Benchmarks through Sports
Jan 19, 2023



Existing benchmarks for evaluating long video understanding falls short on multiple aspects, either lacking in scale or quality of annotations. These limitations arise from the difficulty in collecting dense annotations for long videos (e.g. actions, dialogues, etc.), which are often obtained by manually labeling many frames per second. In this work, we introduce an automated Annotation and Video Stream Alignment Pipeline (abbreviated ASAP). We demonstrate the generality of ASAP by aligning unlabeled videos of four different sports (Cricket, Football, Basketball, and American Football) with their corresponding dense annotations (i.e. commentary) freely available on the web. Our human studies indicate that ASAP can align videos and annotations with high fidelity, precision, and speed. We then leverage ASAP scalability to create LCric, a large-scale long video understanding benchmark, with over 1000 hours of densely annotated long Cricket videos (with an average sample length of 50 mins) collected at virtually zero annotation cost. We benchmark and analyze state-of-the-art video understanding models on LCric through a large set of compositional multi-choice and regression queries. We establish a human baseline that indicates significant room for new research to explore. The dataset along with the code for ASAP and baselines can be accessed here: https://asap-benchmark.github.io/.