 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Scalable Video Understanding Benchmarks through Sports
Jan 19, 2023



Existing benchmarks for evaluating long video understanding falls short on multiple aspects, either lacking in scale or quality of annotations. These limitations arise from the difficulty in collecting dense annotations for long videos (e.g. actions, dialogues, etc.), which are often obtained by manually labeling many frames per second. In this work, we introduce an automated Annotation and Video Stream Alignment Pipeline (abbreviated ASAP). We demonstrate the generality of ASAP by aligning unlabeled videos of four different sports (Cricket, Football, Basketball, and American Football) with their corresponding dense annotations (i.e. commentary) freely available on the web. Our human studies indicate that ASAP can align videos and annotations with high fidelity, precision, and speed. We then leverage ASAP scalability to create LCric, a large-scale long video understanding benchmark, with over 1000 hours of densely annotated long Cricket videos (with an average sample length of 50 mins) collected at virtually zero annotation cost. We benchmark and analyze state-of-the-art video understanding models on LCric through a large set of compositional multi-choice and regression queries. We establish a human baseline that indicates significant room for new research to explore. The dataset along with the code for ASAP and baselines can be accessed here: https://asap-benchmark.github.io/.
RelTransformer: Balancing the Visual Relationship Detection from Local Context, Scene and Memory
Apr 24, 2021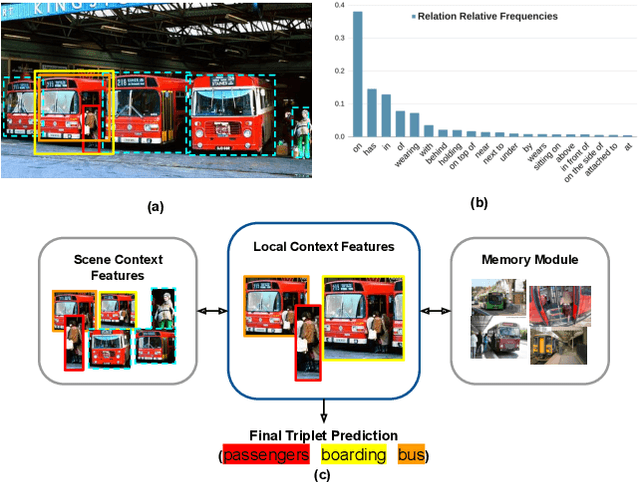
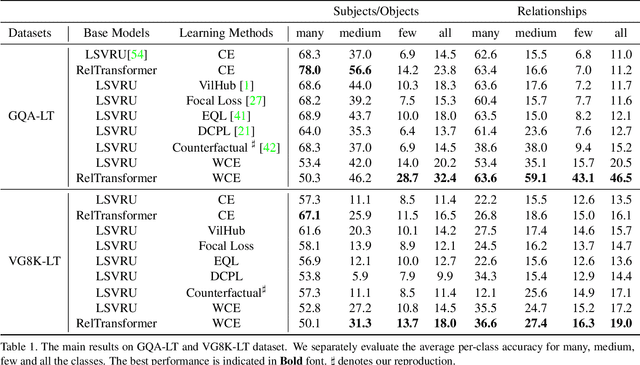
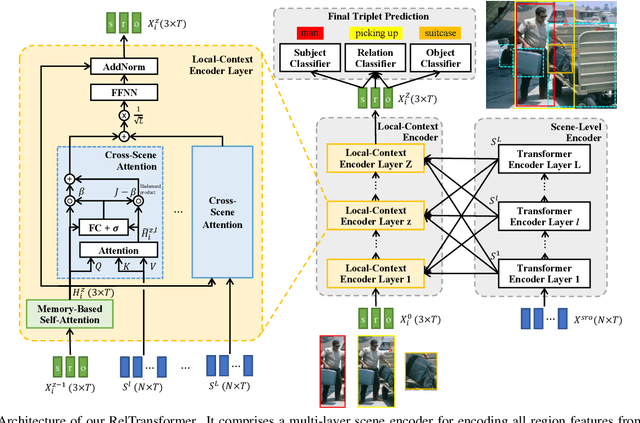
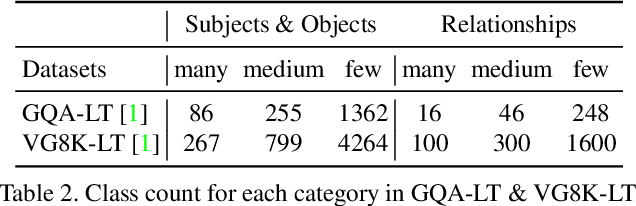
Visual relationship recognition (VRR) is a fundamental scene understanding task. The structure that VRR provides is essential to improve the AI interpretability in downstream tasks such as image captioning and visual question answering. Several recent studies showed that the long-tail problem in VRR is even more critical than that in object recognition due to the compositional complexity and structure. To overcome this limitation, we propose a novel transformer-based framework, dubbed as RelTransformer, which performs relationship prediction using rich semantic features from multiple image levels. We assume that more abundantcon textual features can generate more accurate and discriminative relationships, which can be useful when sufficient training data are lacking. The key feature of our model is its ability to aggregate three different-level features (local context, scene, and dataset-level) to compositionally predict the visual relationship. We evaluate our model on the visual genome and two "long-tail" VRR datasets, GQA-LT and VG8k-LT. Extensive experiments demonstrate that our RelTransformer could improve over the state-of-the-art baselines on all the datasets. In addition, our model significantly improves the accuracy of GQA-LT by 27.4% upon the best baselines on tail-relationship prediction. Our code is available in https://github.com/Vision-CAIR/RelTransformer.
Visual Relationship Detection using Scene Graphs: A Survey
May 16, 2020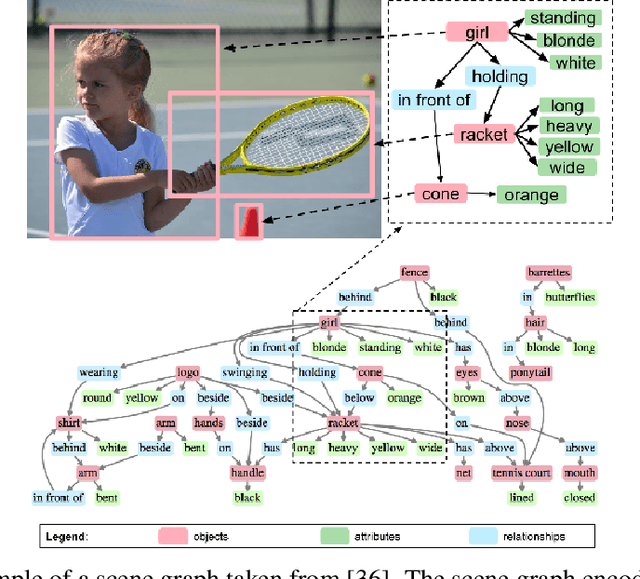
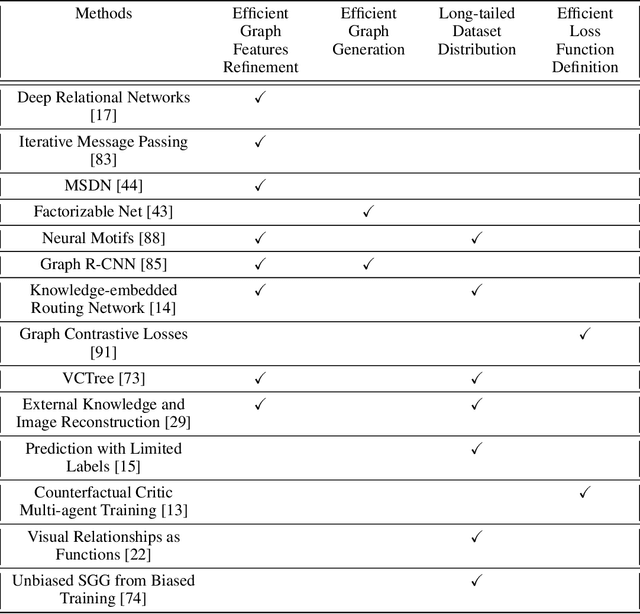
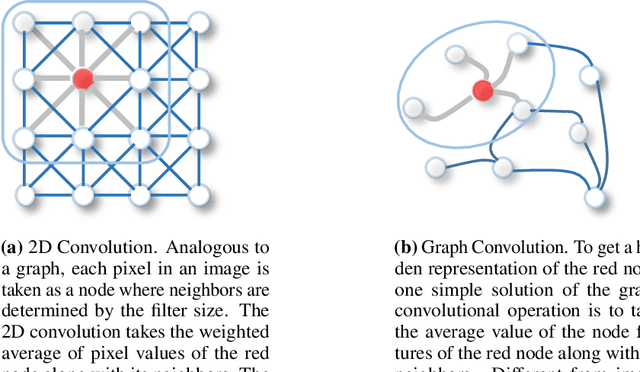
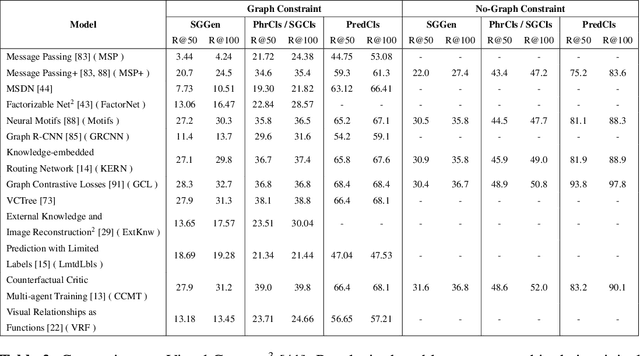
Understanding a scene by decoding the visual relationships depicted in an image has been a long studied problem. While the recent advances in deep learning and the usage of deep neural networks have achieved near human accuracy on many tasks, there still exists a pretty big gap between human and machine level performance when it comes to various visual relationship detection tasks. Developing on earlier tasks like object recognition, segmentation and captioning which focused on a relatively coarser image understanding, newer tasks have been introduced recently to deal with a finer level of image understanding. A Scene Graph is one such technique to better represent a scene and the various relationships present in it. With its wide number of applications in various tasks like Visual Question Answering, Semantic Image Retrieval, Image Generation, among many others, it has proved to be a useful tool for deeper and better visual relationship understanding. In this paper, we present a detailed survey on the various techniques for scene graph generation, their efficacy to represent visual relationships and how it has been used to solve various downstream tasks. We also attempt to analyze the various future directions in which the field might advance in the future. Being one of the first papers to give a detailed survey on this topic, we also hope to give a succinct introduction to scene graphs, and guide practitioners while developing approaches for their applications.
Revisiting CycleGAN for semi-supervised segmentation
Aug 30, 2019
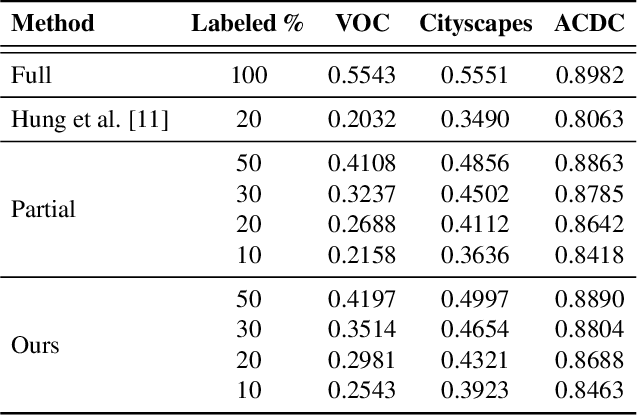

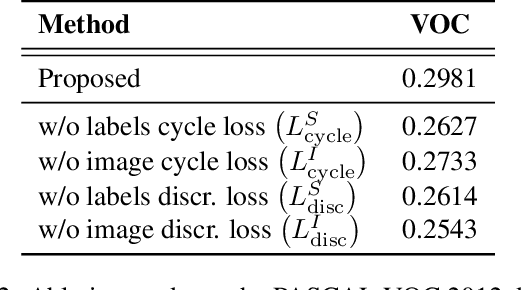
In this work, we study the problem of training deep networks for semantic image segmentation using only a fraction of annotated images, which may significantly reduce human annotation efforts. Particularly, we propose a strategy that exploits the unpaired image style transfer capabilities of CycleGAN in semi-supervised segmentation. Unlike recent works using adversarial learning for semi-supervised segmentation, we enforce cycle consistency to learn a bidirectional mapping between unpaired images and segmentation masks. This adds an unsupervised regularization effect that boosts the segmentation performance when annotated data is limited. Experiments on three different public segmentation benchmarks (PASCAL VOC 2012, Cityscapes and ACDC) demonstrate the effectiveness of the proposed method. The proposed model achieves 2-4% of improvement with respect to the baseline and outperforms recent approaches for this task, particularly in low labeled data regime.