 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVista4D: Video Reshooting with 4D Point Clouds
Apr 23, 2026We present Vista4D, a robust and flexible video reshooting framework that grounds the input video and target cameras in a 4D point cloud. Specifically, given an input video, our method re-synthesizes the scene with the same dynamics from a different camera trajectory and viewpoint. Existing video reshooting methods often struggle with depth estimation artifacts of real-world dynamic videos, while also failing to preserve content appearance and failing to maintain precise camera control for challenging new trajectories. We build a 4D-grounded point cloud representation with static pixel segmentation and 4D reconstruction to explicitly preserve seen content and provide rich camera signals, and we train with reconstructed multiview dynamic data for robustness against point cloud artifacts during real-world inference. Our results demonstrate improved 4D consistency, camera control, and visual quality compared to state-of-the-art baselines under a variety of videos and camera paths. Moreover, our method generalizes to real-world applications such as dynamic scene expansion and 4D scene recomposition. See our project page for results, code, and models: https://eyeline-labs.github.io/Vista4D
Vid2Avatar-Pro: Authentic Avatar from Videos in the Wild via Universal Prior
Mar 03, 2025We present Vid2Avatar-Pro, a method to create photorealistic and animatable 3D human avatars from monocular in-the-wild videos. Building a high-quality avatar that supports animation with diverse poses from a monocular video is challenging because the observation of pose diversity and view points is inherently limited. The lack of pose variations typically leads to poor generalization to novel poses, and avatars can easily overfit to limited input view points, producing artifacts and distortions from other views. In this work, we address these limitations by leveraging a universal prior model (UPM) learned from a large corpus of multi-view clothed human performance capture data. We build our representation on top of expressive 3D Gaussians with canonical front and back maps shared across identities. Once the UPM is learned to accurately reproduce the large-scale multi-view human images, we fine-tune the model with an in-the-wild video via inverse rendering to obtain a personalized photorealistic human avatar that can be faithfully animated to novel human motions and rendered from novel views. The experiments show that our approach based on the learned universal prior sets a new state-of-the-art in monocular avatar reconstruction by substantially outperforming existing approaches relying only on heuristic regularization or a shape prior of minimally clothed bodies (e.g., SMPL) on publicly available datasets.
Pippo: High-Resolution Multi-View Humans from a Single Image
Feb 11, 2025
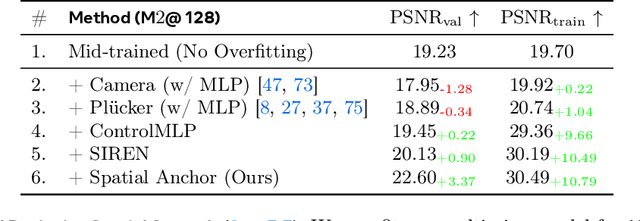
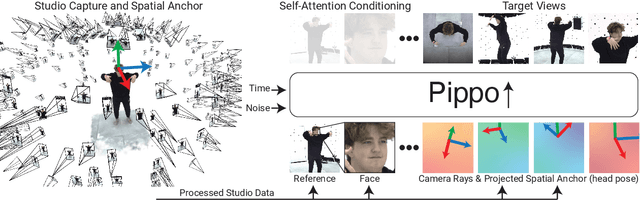

We present Pippo, a generative model capable of producing 1K resolution dense turnaround videos of a person from a single casually clicked photo. Pippo is a multi-view diffusion transformer and does not require any additional inputs - e.g., a fitted parametric model or camera parameters of the input image. We pre-train Pippo on 3B human images without captions, and conduct multi-view mid-training and post-training on studio captured humans. During mid-training, to quickly absorb the studio dataset, we denoise several (up to 48) views at low-resolution, and encode target cameras coarsely using a shallow MLP. During post-training, we denoise fewer views at high-resolution and use pixel-aligned controls (e.g., Spatial anchor and Plucker rays) to enable 3D consistent generations. At inference, we propose an attention biasing technique that allows Pippo to simultaneously generate greater than 5 times as many views as seen during training. Finally, we also introduce an improved metric to evaluate 3D consistency of multi-view generations, and show that Pippo outperforms existing works on multi-view human generation from a single image.
Fillerbuster: Multi-View Scene Completion for Casual Captures
Feb 07, 2025
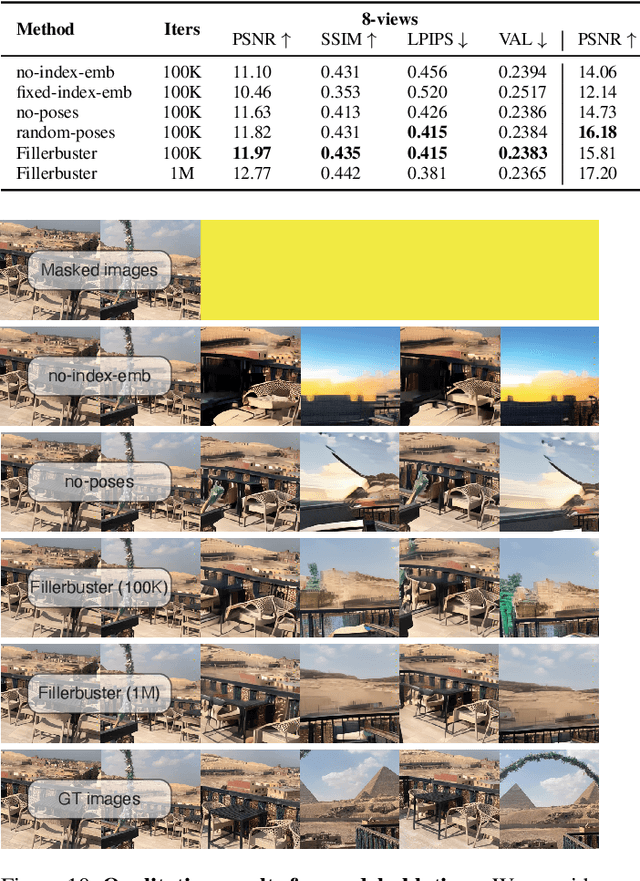
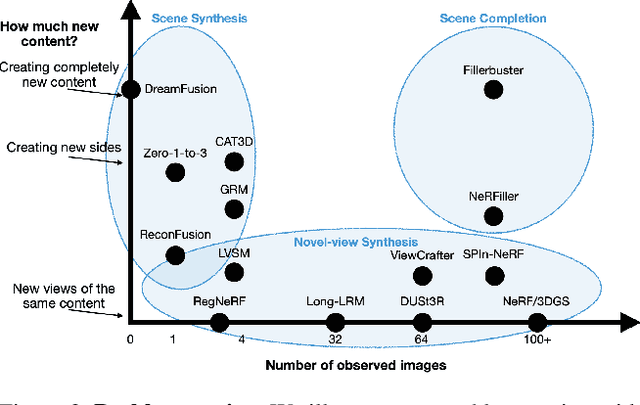

We present Fillerbuster, a method that completes unknown regions of a 3D scene by utilizing a novel large-scale multi-view latent diffusion transformer. Casual captures are often sparse and miss surrounding content behind objects or above the scene. Existing methods are not suitable for handling this challenge as they focus on making the known pixels look good with sparse-view priors, or on creating the missing sides of objects from just one or two photos. In reality, we often have hundreds of input frames and want to complete areas that are missing and unobserved from the input frames. Additionally, the images often do not have known camera parameters. Our solution is to train a generative model that can consume a large context of input frames while generating unknown target views and recovering image poses when desired. We show results where we complete partial captures on two existing datasets. We also present an uncalibrated scene completion task where our unified model predicts both poses and creates new content. Our model is the first to predict many images and poses together for scene completion.
SG-I2V: Self-Guided Trajectory Control in Image-to-Video Generation
Nov 07, 2024



Methods for image-to-video generation have achieved impressive, photo-realistic quality. However, adjusting specific elements in generated videos, such as object motion or camera movement, is often a tedious process of trial and error, e.g., involving re-generating videos with different random seeds. Recent techniques address this issue by fine-tuning a pre-trained model to follow conditioning signals, such as bounding boxes or point trajectories. Yet, this fine-tuning procedure can be computationally expensive, and it requires datasets with annotated object motion, which can be difficult to procure. In this work, we introduce SG-I2V, a framework for controllable image-to-video generation that is self-guided$\unicode{x2013}$offering zero-shot control by relying solely on the knowledge present in a pre-trained image-to-video diffusion model without the need for fine-tuning or external knowledge. Our zero-shot method outperforms unsupervised baselines while being competitive with supervised models in terms of visual quality and motion fidelity.
Realistic Evaluation of Model Merging for Compositional Generalization
Sep 26, 2024Merging has become a widespread way to cheaply combine individual models into a single model that inherits their capabilities and attains better performance. This popularity has spurred rapid development of many new merging methods, which are typically validated in disparate experimental settings and frequently differ in the assumptions made about model architecture, data availability, and computational budget. In this work, we characterize the relative merits of different merging methods by evaluating them in a shared experimental setting and precisely identifying the practical requirements of each method. Specifically, our setting focuses on using merging for compositional generalization of capabilities in image classification, image generation, and natural language processing. Additionally, we measure the computational costs of different merging methods as well as how they perform when scaling the number of models being merged. Taken together, our results clarify the state of the field of model merging and provide a comprehensive and rigorous experimental setup to test new methods.
Pixel-Aligned Multi-View Generation with Depth Guided Decoder
Aug 26, 2024
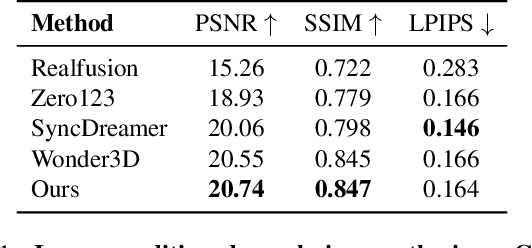
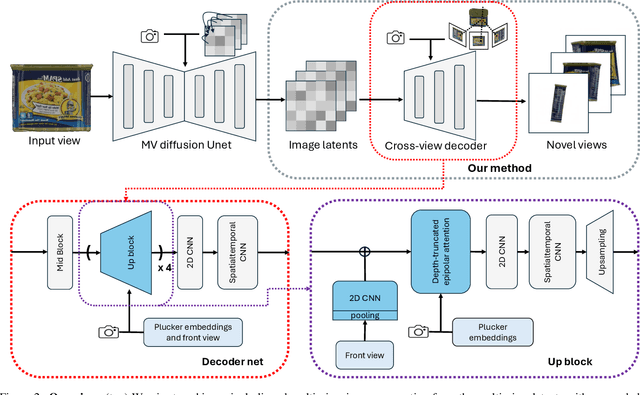

The task of image-to-multi-view generation refers to generating novel views of an instance from a single image. Recent methods achieve this by extending text-to-image latent diffusion models to multi-view version, which contains an VAE image encoder and a U-Net diffusion model. Specifically, these generation methods usually fix VAE and finetune the U-Net only. However, the significant downscaling of the latent vectors computed from the input images and independent decoding leads to notable pixel-level misalignment across multiple views. To address this, we propose a novel method for pixel-level image-to-multi-view generation. Unlike prior work, we incorporate attention layers across multi-view images in the VAE decoder of a latent video diffusion model. Specifically, we introduce a depth-truncated epipolar attention, enabling the model to focus on spatially adjacent regions while remaining memory efficient. Applying depth-truncated attn is challenging during inference as the ground-truth depth is usually difficult to obtain and pre-trained depth estimation models is hard to provide accurate depth. Thus, to enhance the generalization to inaccurate depth when ground truth depth is missing, we perturb depth inputs during training. During inference, we employ a rapid multi-view to 3D reconstruction approach, NeuS, to obtain coarse depth for the depth-truncated epipolar attention. Our model enables better pixel alignment across multi-view images. Moreover, we demonstrate the efficacy of our approach in improving downstream multi-view to 3D reconstruction tasks.
SPAD : Spatially Aware Multiview Diffusers
Feb 07, 2024

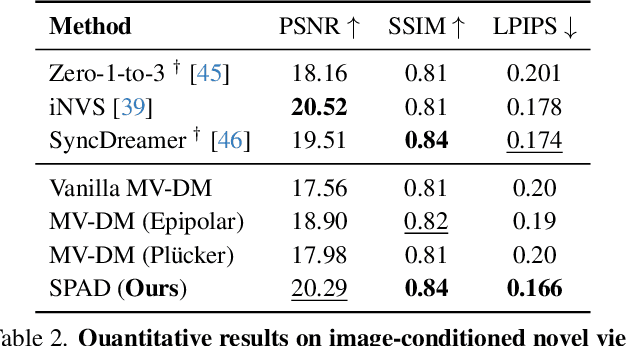

We present SPAD, a novel approach for creating consistent multi-view images from text prompts or single images. To enable multi-view generation, we repurpose a pretrained 2D diffusion model by extending its self-attention layers with cross-view interactions, and fine-tune it on a high quality subset of Objaverse. We find that a naive extension of the self-attention proposed in prior work (e.g. MVDream) leads to content copying between views. Therefore, we explicitly constrain the cross-view attention based on epipolar geometry. To further enhance 3D consistency, we utilize Plucker coordinates derived from camera rays and inject them as positional encoding. This enables SPAD to reason over spatial proximity in 3D well. In contrast to recent works that can only generate views at fixed azimuth and elevation, SPAD offers full camera control and achieves state-of-the-art results in novel view synthesis on unseen objects from the Objaverse and Google Scanned Objects datasets. Finally, we demonstrate that text-to-3D generation using SPAD prevents the multi-face Janus issue. See more details at our webpage: https://yashkant.github.io/spad
AToM: Amortized Text-to-Mesh using 2D Diffusion
Feb 01, 2024



We introduce Amortized Text-to-Mesh (AToM), a feed-forward text-to-mesh framework optimized across multiple text prompts simultaneously. In contrast to existing text-to-3D methods that often entail time-consuming per-prompt optimization and commonly output representations other than polygonal meshes, AToM directly generates high-quality textured meshes in less than 1 second with around 10 times reduction in the training cost, and generalizes to unseen prompts. Our key idea is a novel triplane-based text-to-mesh architecture with a two-stage amortized optimization strategy that ensures stable training and enables scalability. Through extensive experiments on various prompt benchmarks, AToM significantly outperforms state-of-the-art amortized approaches with over 4 times higher accuracy (in DF415 dataset) and produces more distinguishable and higher-quality 3D outputs. AToM demonstrates strong generalizability, offering finegrained 3D assets for unseen interpolated prompts without further optimization during inference, unlike per-prompt solutions.
Virtual Pets: Animatable Animal Generation in 3D Scenes
Dec 21, 2023Toward unlocking the potential of generative models in immersive 4D experiences, we introduce Virtual Pet, a novel pipeline to model realistic and diverse motions for target animal species within a 3D environment. To circumvent the limited availability of 3D motion data aligned with environmental geometry, we leverage monocular internet videos and extract deformable NeRF representations for the foreground and static NeRF representations for the background. For this, we develop a reconstruction strategy, encompassing species-level shared template learning and per-video fine-tuning. Utilizing the reconstructed data, we then train a conditional 3D motion model to learn the trajectory and articulation of foreground animals in the context of 3D backgrounds. We showcase the efficacy of our pipeline with comprehensive qualitative and quantitative evaluations using cat videos. We also demonstrate versatility across unseen cats and indoor environments, producing temporally coherent 4D outputs for enriched virtual experiences.