 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixel-Aligned Multi-View Generation with Depth Guided Decoder
Paper and Code
Aug 26, 2024
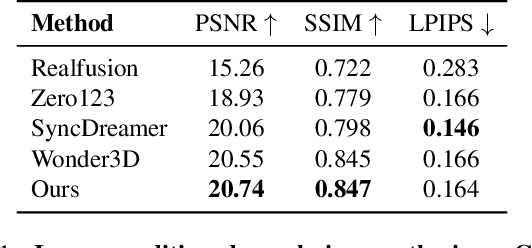
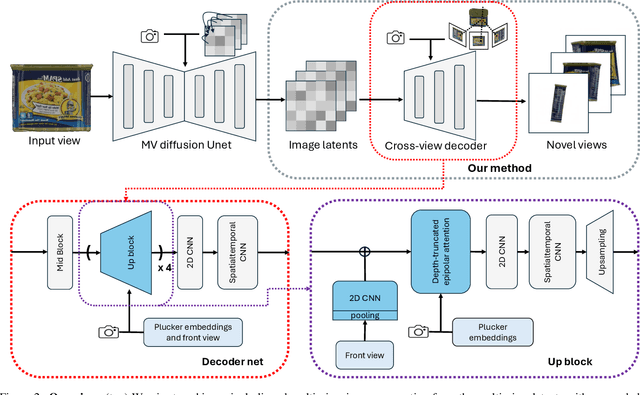

The task of image-to-multi-view generation refers to generating novel views of an instance from a single image. Recent methods achieve this by extending text-to-image latent diffusion models to multi-view version, which contains an VAE image encoder and a U-Net diffusion model. Specifically, these generation methods usually fix VAE and finetune the U-Net only. However, the significant downscaling of the latent vectors computed from the input images and independent decoding leads to notable pixel-level misalignment across multiple views. To address this, we propose a novel method for pixel-level image-to-multi-view generation. Unlike prior work, we incorporate attention layers across multi-view images in the VAE decoder of a latent video diffusion model. Specifically, we introduce a depth-truncated epipolar attention, enabling the model to focus on spatially adjacent regions while remaining memory efficient. Applying depth-truncated attn is challenging during inference as the ground-truth depth is usually difficult to obtain and pre-trained depth estimation models is hard to provide accurate depth. Thus, to enhance the generalization to inaccurate depth when ground truth depth is missing, we perturb depth inputs during training. During inference, we employ a rapid multi-view to 3D reconstruction approach, NeuS, to obtain coarse depth for the depth-truncated epipolar attention. Our model enables better pixel alignment across multi-view images. Moreover, we demonstrate the efficacy of our approach in improving downstream multi-view to 3D reconstruction tasks.