 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterPrior: Scaling Generative Control for Physics-Based Human-Object Interactions
Feb 05, 2026Humans rarely plan whole-body interactions with objects at the level of explicit whole-body movements. High-level intentions, such as affordance, define the goal, while coordinated balance, contact, and manipulation can emerge naturally from underlying physical and motor priors. Scaling such priors is key to enabling humanoids to compose and generalize loco-manipulation skills across diverse contexts while maintaining physically coherent whole-body coordination. To this end, we introduce InterPrior, a scalable framework that learns a unified generative controller through large-scale imitation pretraining and post-training by reinforcement learning. InterPrior first distills a full-reference imitation expert into a versatile, goal-conditioned variational policy that reconstructs motion from multimodal observations and high-level intent. While the distilled policy reconstructs training behaviors, it does not generalize reliably due to the vast configuration space of large-scale human-object interactions. To address this, we apply data augmentation with physical perturbations, and then perform reinforcement learning finetuning to improve competence on unseen goals and initializations. Together, these steps consolidate the reconstructed latent skills into a valid manifold, yielding a motion prior that generalizes beyond the training data, e.g., it can incorporate new behaviors such as interactions with unseen objects. We further demonstrate its effectiveness for user-interactive control and its potential for real robot deployment.
3D-Fixup: Advancing Photo Editing with 3D Priors
May 15, 2025



Despite significant advances in modeling image priors via diffusion models, 3D-aware image editing remains challenging, in part because the object is only specified via a single image. To tackle this challenge, we propose 3D-Fixup, a new framework for editing 2D images guided by learned 3D priors. The framework supports difficult editing situations such as object translation and 3D rotation. To achieve this, we leverage a training-based approach that harnesses the generative power of diffusion models. As video data naturally encodes real-world physical dynamics, we turn to video data for generating training data pairs, i.e., a source and a target frame. Rather than relying solely on a single trained model to infer transformations between source and target frames, we incorporate 3D guidance from an Image-to-3D model, which bridges this challenging task by explicitly projecting 2D information into 3D space. We design a data generation pipeline to ensure high-quality 3D guidance throughout training. Results show that by integrating these 3D priors, 3D-Fixup effectively supports complex, identity coherent 3D-aware edits, achieving high-quality results and advancing the application of diffusion models in realistic image manipulation. The code is provided at https://3dfixup.github.io/
Virtual Pets: Animatable Animal Generation in 3D Scenes
Dec 21, 2023Toward unlocking the potential of generative models in immersive 4D experiences, we introduce Virtual Pet, a novel pipeline to model realistic and diverse motions for target animal species within a 3D environment. To circumvent the limited availability of 3D motion data aligned with environmental geometry, we leverage monocular internet videos and extract deformable NeRF representations for the foreground and static NeRF representations for the background. For this, we develop a reconstruction strategy, encompassing species-level shared template learning and per-video fine-tuning. Utilizing the reconstructed data, we then train a conditional 3D motion model to learn the trajectory and articulation of foreground animals in the context of 3D backgrounds. We showcase the efficacy of our pipeline with comprehensive qualitative and quantitative evaluations using cat videos. We also demonstrate versatility across unseen cats and indoor environments, producing temporally coherent 4D outputs for enriched virtual experiences.
SDFusion: Multimodal 3D Shape Completion, Reconstruction, and Generation
Dec 08, 2022In this work, we present a novel framework built to simplify 3D asset generation for amateur users. To enable interactive generation, our method supports a variety of input modalities that can be easily provided by a human, including images, text, partially observed shapes and combinations of these, further allowing to adjust the strength of each input. At the core of our approach is an encoder-decoder, compressing 3D shapes into a compact latent representation, upon which a diffusion model is learned. To enable a variety of multi-modal inputs, we employ task-specific encoders with dropout followed by a cross-attention mechanism. Due to its flexibility, our model naturally supports a variety of tasks, outperforming prior works on shape completion, image-based 3D reconstruction, and text-to-3D. Most interestingly, our model can combine all these tasks into one swiss-army-knife tool, enabling the user to perform shape generation using incomplete shapes, images, and textual descriptions at the same time, providing the relative weights for each input and facilitating interactivity. Despite our approach being shape-only, we further show an efficient method to texture the generated shape using large-scale text-to-image models.
Joint Forecasting of Panoptic Segmentations with Difference Attention
Apr 14, 2022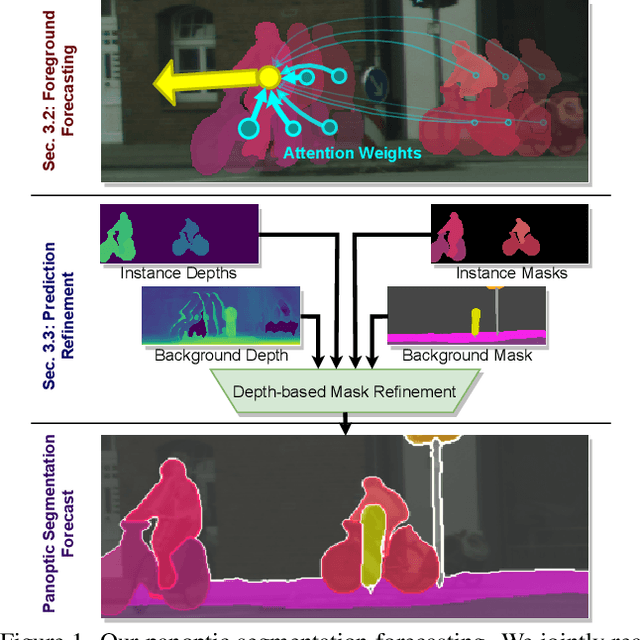

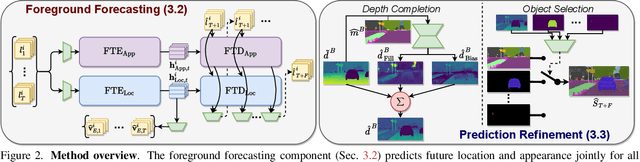
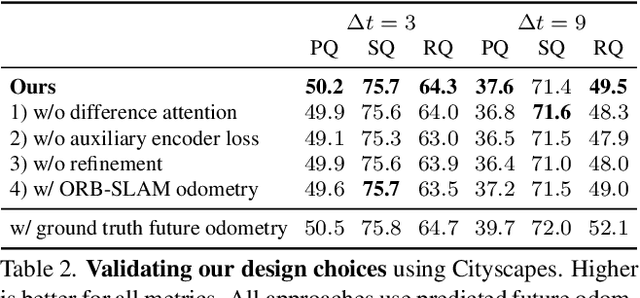
Forecasting of a representation is important for safe and effective autonomy. For this, panoptic segmentations have been studied as a compelling representation in recent work. However, recent state-of-the-art on panoptic segmentation forecasting suffers from two issues: first, individual object instances are treated independently of each other; second, individual object instance forecasts are merged in a heuristic manner. To address both issues, we study a new panoptic segmentation forecasting model that jointly forecasts all object instances in a scene using a transformer model based on 'difference attention.' It further refines the predictions by taking depth estimates into account. We evaluate the proposed model on the Cityscapes and AIODrive datasets. We find difference attention to be particularly suitable for forecasting because the difference of quantities like locations enables a model to explicitly reason about velocities and acceleration. Because of this, we attain state-of-the-art on panoptic segmentation forecasting metrics.