 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiNVS: Repurposing Diffusion Inpainters for Novel View Synthesis
Paper and Code

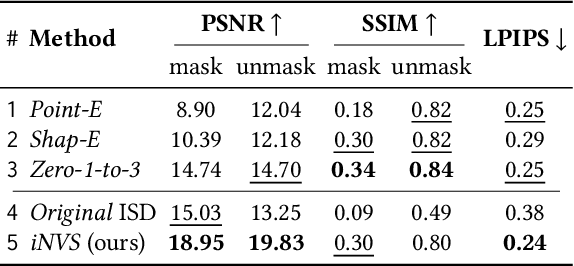
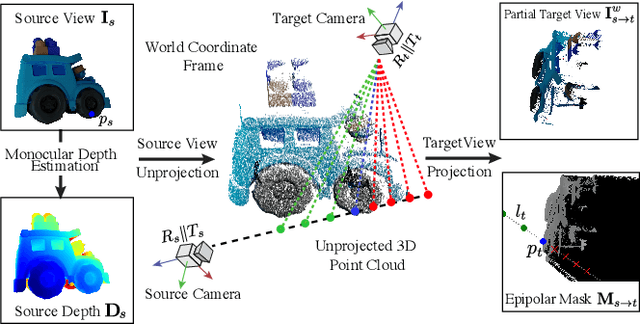

We present a method for generating consistent novel views from a single source image. Our approach focuses on maximizing the reuse of visible pixels from the source image. To achieve this, we use a monocular depth estimator that transfers visible pixels from the source view to the target view. Starting from a pre-trained 2D inpainting diffusion model, we train our method on the large-scale Objaverse dataset to learn 3D object priors. While training we use a novel masking mechanism based on epipolar lines to further improve the quality of our approach. This allows our framework to perform zero-shot novel view synthesis on a variety of objects. We evaluate the zero-shot abilities of our framework on three challenging datasets: Google Scanned Objects, Ray Traced Multiview, and Common Objects in 3D. See our webpage for more details: https://yashkant.github.io/invs/