 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelTransformer: Balancing the Visual Relationship Detection from Local Context, Scene and Memory
Apr 24, 2021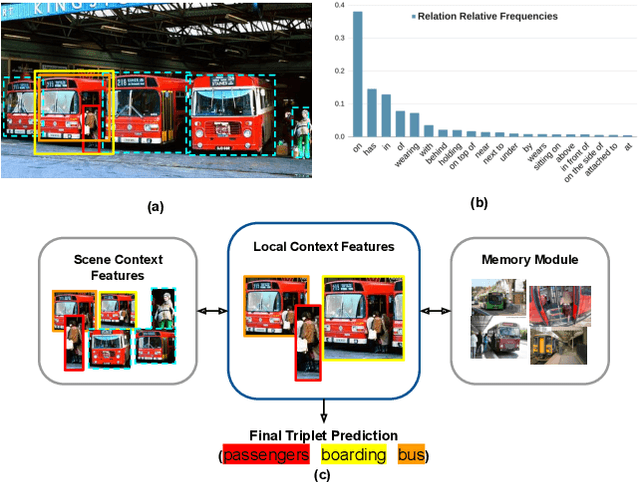
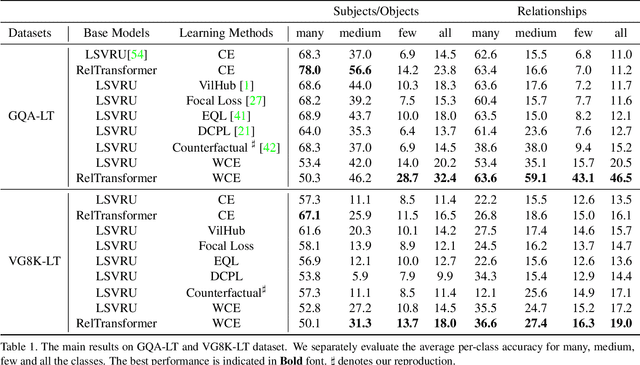
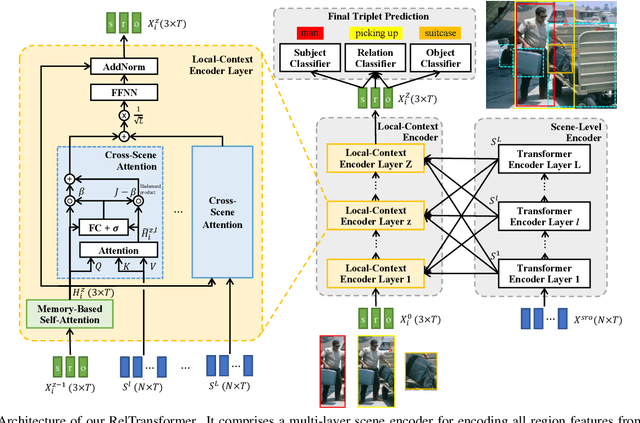
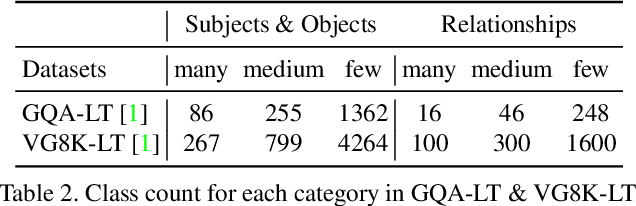
Visual relationship recognition (VRR) is a fundamental scene understanding task. The structure that VRR provides is essential to improve the AI interpretability in downstream tasks such as image captioning and visual question answering. Several recent studies showed that the long-tail problem in VRR is even more critical than that in object recognition due to the compositional complexity and structure. To overcome this limitation, we propose a novel transformer-based framework, dubbed as RelTransformer, which performs relationship prediction using rich semantic features from multiple image levels. We assume that more abundantcon textual features can generate more accurate and discriminative relationships, which can be useful when sufficient training data are lacking. The key feature of our model is its ability to aggregate three different-level features (local context, scene, and dataset-level) to compositionally predict the visual relationship. We evaluate our model on the visual genome and two "long-tail" VRR datasets, GQA-LT and VG8k-LT. Extensive experiments demonstrate that our RelTransformer could improve over the state-of-the-art baselines on all the datasets. In addition, our model significantly improves the accuracy of GQA-LT by 27.4% upon the best baselines on tail-relationship prediction. Our code is available in https://github.com/Vision-CAIR/RelTransformer.
Long-tail Visual Relationship Recognition with a Visiolinguistic Hubless Loss
Apr 20, 2020
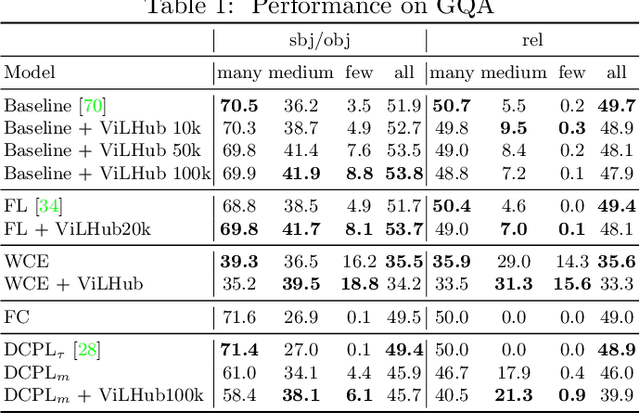
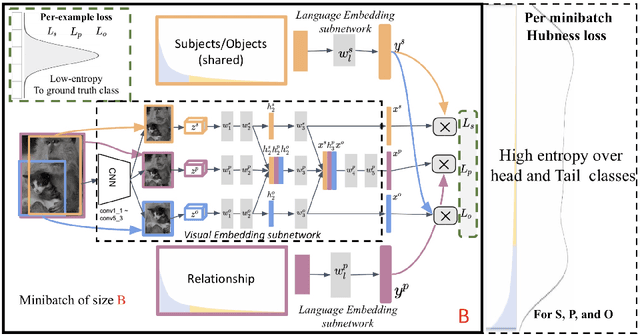
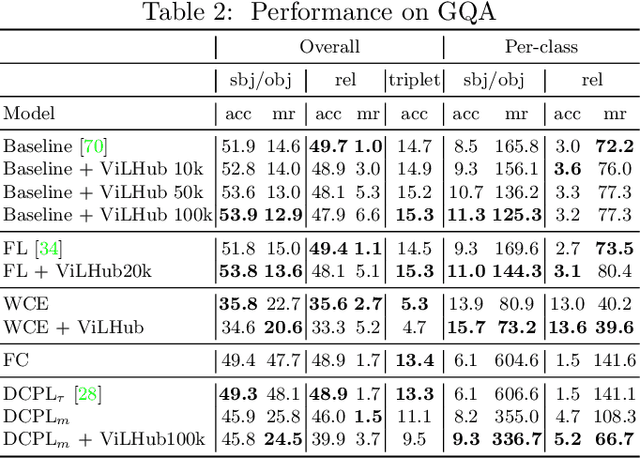
Scaling up the vocabulary and complexity of current visual understanding systems is necessary in order to bridge the gap between human and machine visual intelligence. However, a crucial impediment to this end lies in the difficulty of generalizing to data distributions that come from real-world scenarios. Typically such distributions follow Zipf's law which states that only a small portion of the collected object classes will have abundant examples (head); while most classes will contain just a few (tail). In this paper, we propose to study a novel task concerning the generalization of visual relationships that are on the distribution's tail, i.e. we investigate how to help AI systems to better recognize rare relationships like <S:dog, P:riding, O:horse>, where the subject S, predicate P, and/or the object O come from the tail of the corresponding distributions. To achieve this goal, we first introduce two large-scale visual-relationship detection benchmarks built upon the widely used Visual Genome and GQA datasets. We also propose an intuitive evaluation protocol that gives credit to classifiers who prefer concepts that are semantically close to the ground truth class according to wordNet- or word2vec-induced metrics. Finally, we introduce a visiolinguistic version of a Hubless loss which we show experimentally that it consistently encourages classifiers to be more predictive of the tail classes while still being accurate on head classes. Our code and models are available on http://bit.ly/LTVRR.
YOLO3D: End-to-end real-time 3D Oriented Object Bounding Box Detection from LiDAR Point Cloud
Aug 07, 2018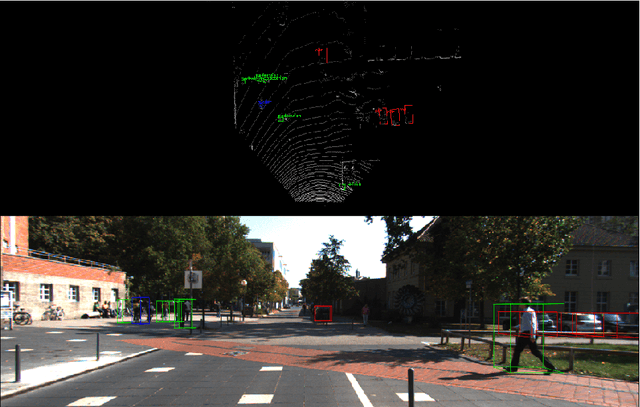
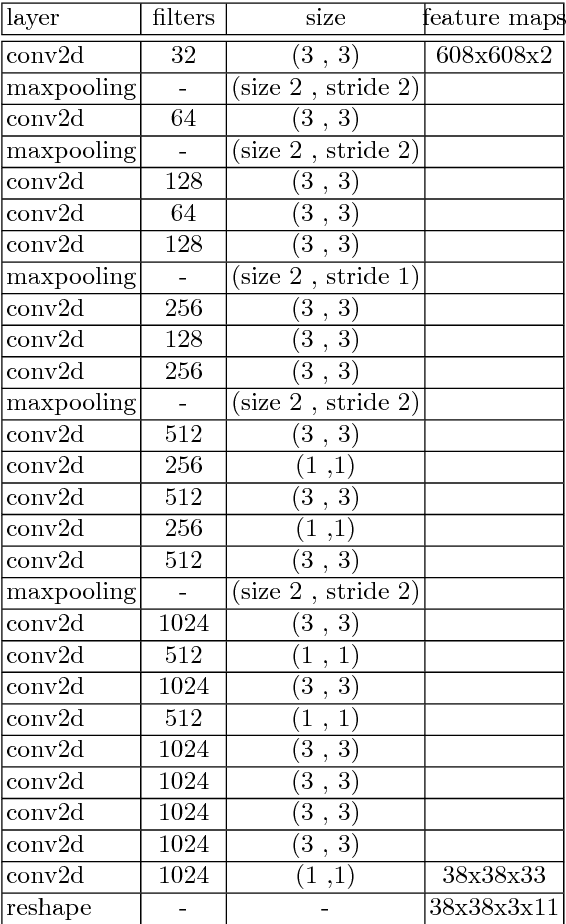

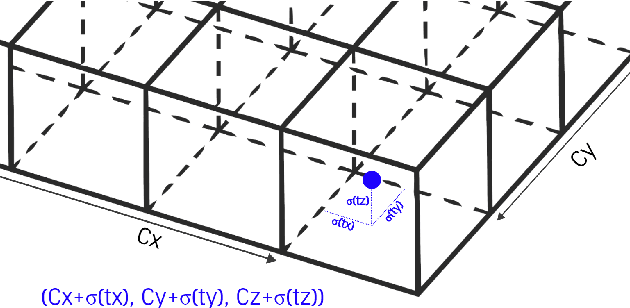
Object detection and classification in 3D is a key task in Automated Driving (AD). LiDAR sensors are employed to provide the 3D point cloud reconstruction of the surrounding environment, while the task of 3D object bounding box detection in real time remains a strong algorithmic challenge. In this paper, we build on the success of the one-shot regression meta-architecture in the 2D perspective image space and extend it to generate oriented 3D object bounding boxes from LiDAR point cloud. Our main contribution is in extending the loss function of YOLO v2 to include the yaw angle, the 3D box center in Cartesian coordinates and the height of the box as a direct regression problem. This formulation enables real-time performance, which is essential for automated driving. Our results are showing promising figures on KITTI benchmark, achieving real-time performance (40 fps) on Titan X GPU.