 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePKCAM: Previous Knowledge Channel Attention Module
Nov 14, 2022



Recently, attention mechanisms have been explored with ConvNets, both across the spatial and channel dimensions. However, from our knowledge, all the existing methods devote the attention modules to capture local interactions from a uni-scale. In this paper, we propose a Previous Knowledge Channel Attention Module(PKCAM), that captures channel-wise relations across different layers to model the global context. Our proposed module PKCAM is easily integrated into any feed-forward CNN architectures and trained in an end-to-end fashion with a negligible footprint due to its lightweight property. We validate our novel architecture through extensive experiments on image classification and object detection tasks with different backbones. Our experiments show consistent improvements in performances against their counterparts. Our code is published at https://github.com/eslambakr/EMCA.
BEV-MODNet: Monocular Camera based Bird's Eye View Moving Object Detection for Autonomous Driving
Jul 11, 2021


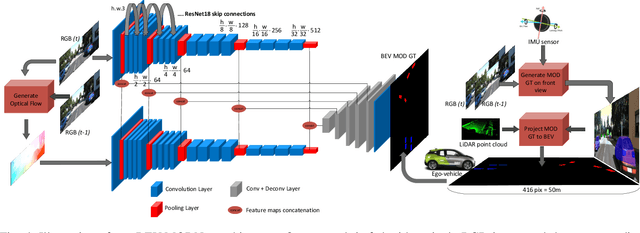
Detection of moving objects is a very important task in autonomous driving systems. After the perception phase, motion planning is typically performed in Bird's Eye View (BEV) space. This would require projection of objects detected on the image plane to top view BEV plane. Such a projection is prone to errors due to lack of depth information and noisy mapping in far away areas. CNNs can leverage the global context in the scene to project better. In this work, we explore end-to-end Moving Object Detection (MOD) on the BEV map directly using monocular images as input. To the best of our knowledge, such a dataset does not exist and we create an extended KITTI-raw dataset consisting of 12.9k images with annotations of moving object masks in BEV space for five classes. The dataset is intended to be used for class agnostic motion cue based object detection and classes are provided as meta-data for better tuning. We design and implement a two-stream RGB and optical flow fusion architecture which outputs motion segmentation directly in BEV space. We compare it with inverse perspective mapping of state-of-the-art motion segmentation predictions on the image plane. We observe a significant improvement of 13% in mIoU using the simple baseline implementation. This demonstrates the ability to directly learn motion segmentation output in BEV space. Qualitative results of our baseline and the dataset annotations can be found in https://sites.google.com/view/bev-modnet.
VM-MODNet: Vehicle Motion aware Moving Object Detection for Autonomous Driving
Apr 22, 2021


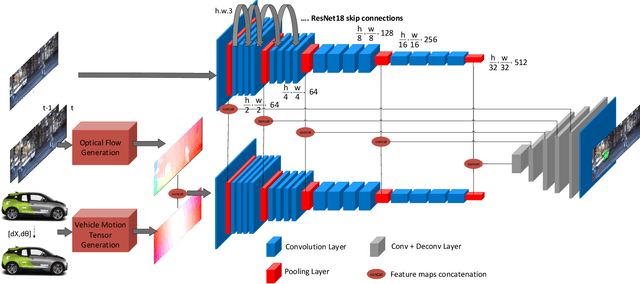
Moving object Detection (MOD) is a critical task in autonomous driving as moving agents around the ego-vehicle need to be accurately detected for safe trajectory planning. It also enables appearance agnostic detection of objects based on motion cues. There are geometric challenges like motion-parallax ambiguity which makes it a difficult problem. In this work, we aim to leverage the vehicle motion information and feed it into the model to have an adaptation mechanism based on ego-motion. The motivation is to enable the model to implicitly perform ego-motion compensation to improve performance. We convert the six degrees of freedom vehicle motion into a pixel-wise tensor which can be fed as input to the CNN model. The proposed model using Vehicle Motion Tensor (VMT) achieves an absolute improvement of 5.6% in mIoU over the baseline architecture. We also achieve state-of-the-art results on the public KITTI_MoSeg_Extended dataset even compared to methods which make use of LiDAR and additional input frames. Our model is also lightweight and runs at 85 fps on a TitanX GPU. Qualitative results are provided in https://youtu.be/ezbfjti-kTk.
MultiCheXNet: A Multi-Task Learning Deep Network For Pneumonia-like Diseases Diagnosis From X-ray Scans
Aug 05, 2020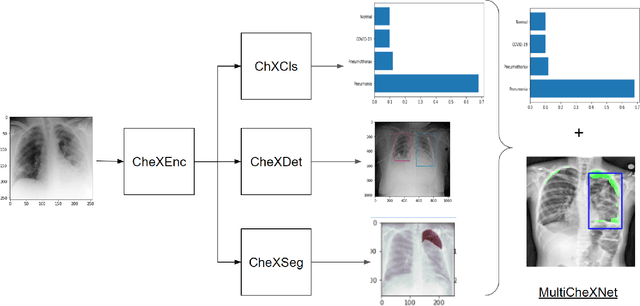
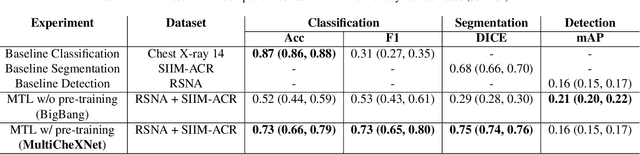
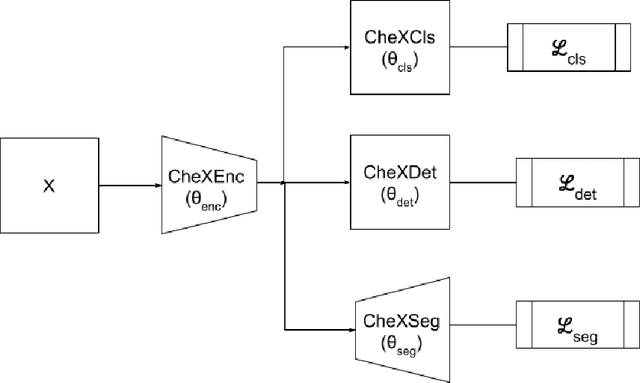
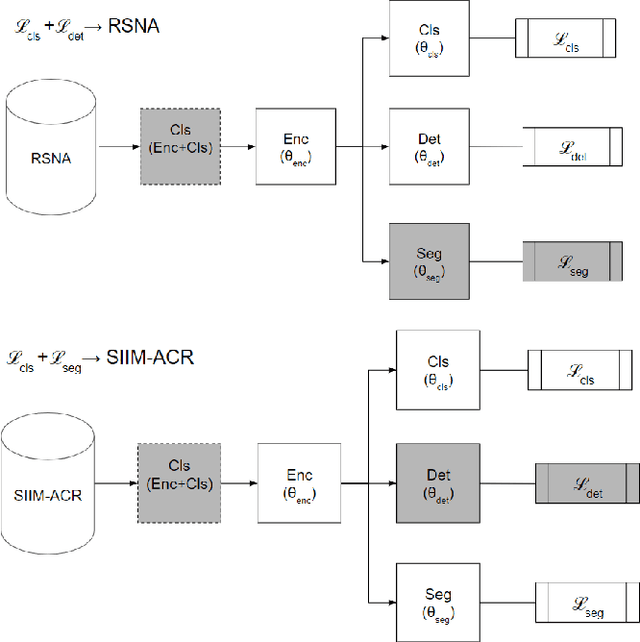
We present MultiCheXNet, an end-to-end Multi-task learning model, that is able to take advantage of different X-rays data sets of Pneumonia-like diseases in one neural architecture, performing three tasks at the same time; diagnosis, segmentation and localization. The common encoder in our architecture can capture useful common features present in the different tasks. The common encoder has another advantage of efficient computations, which speeds up the inference time compared to separate models. The specialized decoders heads can then capture the task-specific features. We employ teacher forcing to address the issue of negative samples that hurt the segmentation and localization performance. Finally,we employ transfer learning to fine tune the classifier on unseen pneumonia-like diseases. The MTL architecture can be trained on joint or dis-joint labeled data sets. The training of the architecture follows a carefully designed protocol, that pre trains different sub-models on specialized datasets, before being integrated in the joint MTL model. Our experimental setup involves variety of data sets, where the baseline performance of the 3 tasks is compared to the MTL architecture performance. Moreover, we evaluate the transfer learning mode to COVID-19 data set,both from individual classifier model, and from MTL architecture classification head.
RST-MODNet: Real-time Spatio-temporal Moving Object Detection for Autonomous Driving
Dec 01, 2019
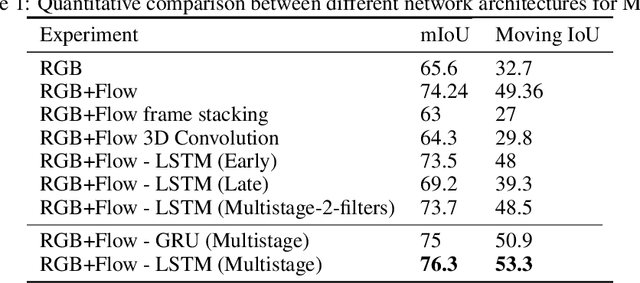


Moving Object Detection (MOD) is a critical task for autonomous vehicles as moving objects represent higher collision risk than static ones. The trajectory of the ego-vehicle is planned based on the future states of detected moving objects. It is quite challenging as the ego-motion has to be modelled and compensated to be able to understand the motion of the surrounding objects. In this work, we propose a real-time end-to-end CNN architecture for MOD utilizing spatio-temporal context to improve robustness. We construct a novel time-aware architecture exploiting temporal motion information embedded within sequential images in addition to explicit motion maps using optical flow images.We demonstrate the impact of our algorithm on KITTI dataset where we obtain an improvement of 8% relative to the baselines. We compare our algorithm with state-of-the-art methods and achieve competitive results on KITTI-Motion dataset in terms of accuracy at three times better run-time. The proposed algorithm runs at 23 fps on a standard desktop GPU targeting deployment on embedded platforms.
Unsupervised Neural Sensor Models for Synthetic LiDAR Data Augmentation
Nov 24, 2019

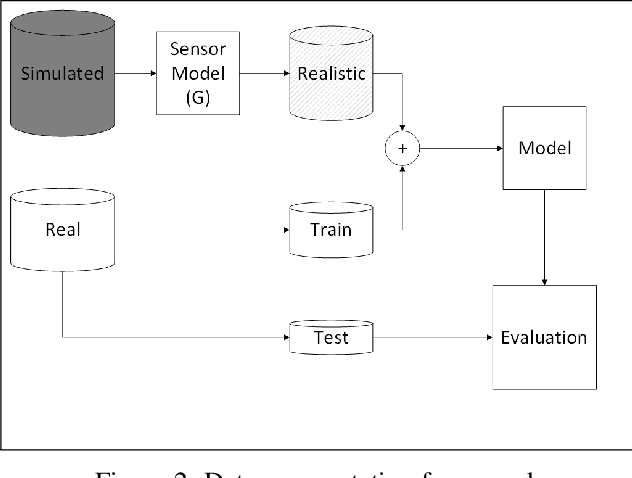

Data scarcity is a bottleneck to machine learning-based perception modules, usually tackled by augmenting real data with synthetic data from simulators. Realistic models of the vehicle perception sensors are hard to formulate in closed form, and at the same time, they require the existence of paired data to be learned. In this work, we propose two unsupervised neural sensor models based on unpaired domain translations with CycleGANs and Neural Style Transfer techniques. We employ CARLA as the simulation environment to obtain simulated LiDAR point clouds, together with their annotations for data augmentation, and we use KITTI dataset as the real LiDAR dataset from which we learn the realistic sensor model mapping. Moreover, we provide a framework for data augmentation and evaluation of the developed sensor models, through extrinsic object detection task evaluation using YOLO network adapted to provide oriented bounding boxes for LiDAR Bird-eye-View projected point clouds. Evaluation is performed on unseen real LiDAR frames from KITTI dataset, with different amounts of simulated data augmentation using the two proposed approaches, showing improvement of 6% mAP for the object detection task, in favor of the augmenting LiDAR point clouds adapted with the proposed neural sensor models over the raw simulated LiDAR.
FuseMODNet: Real-Time Camera and LiDAR based Moving Object Detection for robust low-light Autonomous Driving
Nov 21, 2019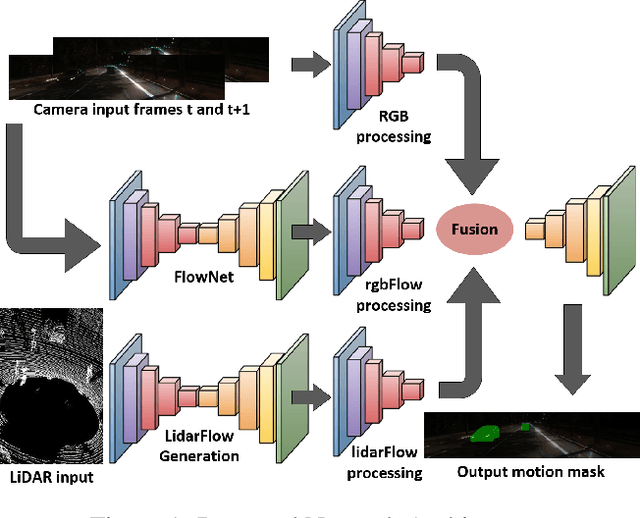
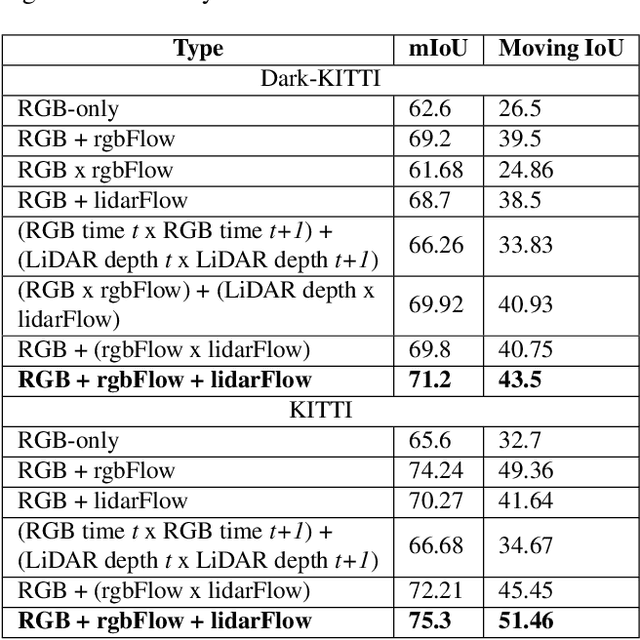


Moving object detection is a critical task for autonomous vehicles. As dynamic objects represent higher collision risk than static ones, our own ego-trajectories have to be planned attending to the future states of the moving elements of the scene. Motion can be perceived using temporal information such as optical flow. Conventional optical flow computation is based on camera sensors only, which makes it prone to failure in conditions with low illumination. On the other hand, LiDAR sensors are independent of illumination, as they measure the time-of-flight of their own emitted lasers. In this work, we propose a robust and real-time CNN architecture for Moving Object Detection (MOD) under low-light conditions by capturing motion information from both camera and LiDAR sensors. We demonstrate the impact of our algorithm on KITTI dataset where we simulate a low-light environment creating a novel dataset "Dark KITTI". We obtain a 10.1% relative improvement on Dark-KITTI, and a 4.25% improvement on standard KITTI relative to our baselines. The proposed algorithm runs at 18 fps on a standard desktop GPU using $256\times1224$ resolution images.
RGB and LiDAR fusion based 3D Semantic Segmentation for Autonomous Driving
Jun 01, 2019

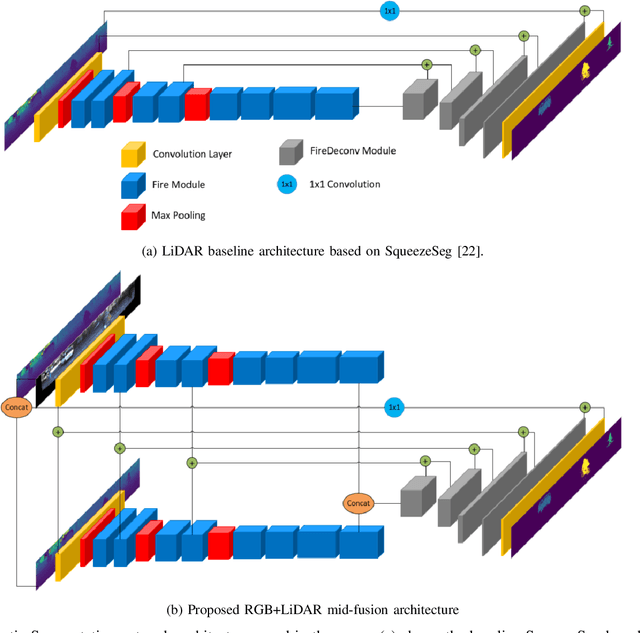
LiDAR has become a standard sensor for autonomous driving applications as they provide highly precise 3D point clouds. LiDAR is also robust for low-light scenarios at night-time or due to shadows where the performance of cameras is degraded. LiDAR perception is gradually becoming mature for algorithms including object detection and SLAM. However, semantic segmentation algorithm remains to be relatively less explored. Motivated by the fact that semantic segmentation is a mature algorithm on image data, we explore sensor fusion based 3D segmentation. To the best of our knowledge, this is the first attempt at RGB and LiDAR based 3D segmentation for autonomous driving. Our main contribution is to convert the RGB image to a polar-grid mapping representation used for LiDAR and design early and mid-level fusion architectures. Additionally, we design a hybrid fusion architecture that combines both fusion algorithms. We evaluate our algorithm on KITTI dataset which provides segmentation annotation for cars, pedestrians and cyclists. We evaluate two state-of-the-art architectures namely SqueezeSeg and PointSeg and improve the mIoU score by 10 % in both cases relative to the LiDAR only baseline.
LiDAR Sensor modeling and Data augmentation with GANs for Autonomous driving
May 17, 2019



In the autonomous driving domain, data collection and annotation from real vehicles are expensive and sometimes unsafe. Simulators are often used for data augmentation, which requires realistic sensor models that are hard to formulate and model in closed forms. Instead, sensors models can be learned from real data. The main challenge is the absence of paired data set, which makes traditional supervised learning techniques not suitable. In this work, we formulate the problem as image translation from unpaired data and employ CycleGANs to solve the sensor modeling problem for LiDAR, to produce realistic LiDAR from simulated LiDAR (sim2real). Further, we generate high-resolution, realistic LiDAR from lower resolution one (real2real). The LiDAR 3D point cloud is processed in Bird-eye View and Polar 2D representations. The experimental results show a high potential of the proposed approach.
YOLO3D: End-to-end real-time 3D Oriented Object Bounding Box Detection from LiDAR Point Cloud
Aug 07, 2018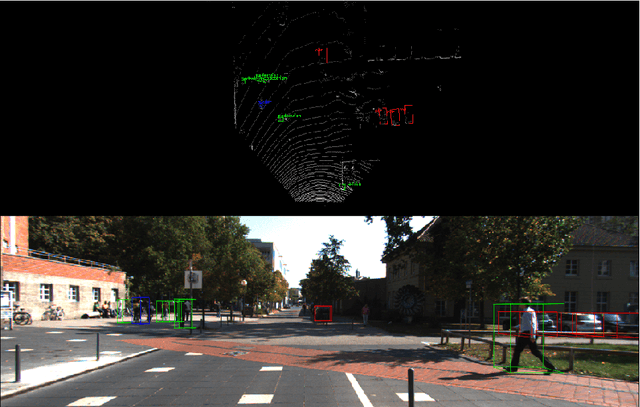
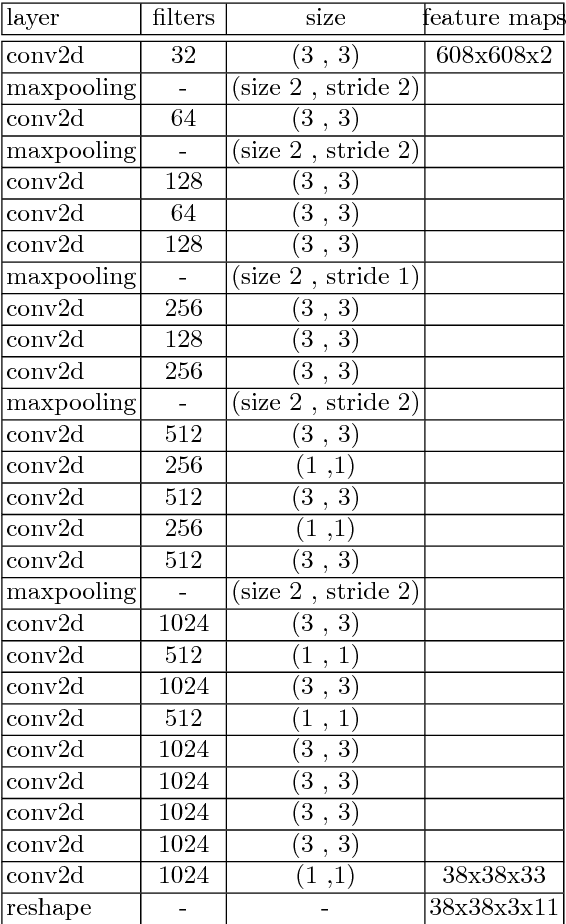

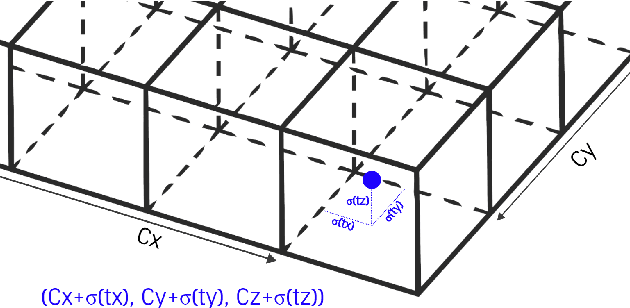
Object detection and classification in 3D is a key task in Automated Driving (AD). LiDAR sensors are employed to provide the 3D point cloud reconstruction of the surrounding environment, while the task of 3D object bounding box detection in real time remains a strong algorithmic challenge. In this paper, we build on the success of the one-shot regression meta-architecture in the 2D perspective image space and extend it to generate oriented 3D object bounding boxes from LiDAR point cloud. Our main contribution is in extending the loss function of YOLO v2 to include the yaw angle, the 3D box center in Cartesian coordinates and the height of the box as a direct regression problem. This formulation enables real-time performance, which is essential for automated driving. Our results are showing promising figures on KITTI benchmark, achieving real-time performance (40 fps) on Titan X GPU.