 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePKCAM: Previous Knowledge Channel Attention Module
Nov 14, 2022



Recently, attention mechanisms have been explored with ConvNets, both across the spatial and channel dimensions. However, from our knowledge, all the existing methods devote the attention modules to capture local interactions from a uni-scale. In this paper, we propose a Previous Knowledge Channel Attention Module(PKCAM), that captures channel-wise relations across different layers to model the global context. Our proposed module PKCAM is easily integrated into any feed-forward CNN architectures and trained in an end-to-end fashion with a negligible footprint due to its lightweight property. We validate our novel architecture through extensive experiments on image classification and object detection tasks with different backbones. Our experiments show consistent improvements in performances against their counterparts. Our code is published at https://github.com/eslambakr/EMCA.
3D Camouflaging Object using RGB-D Sensors
Sep 24, 2017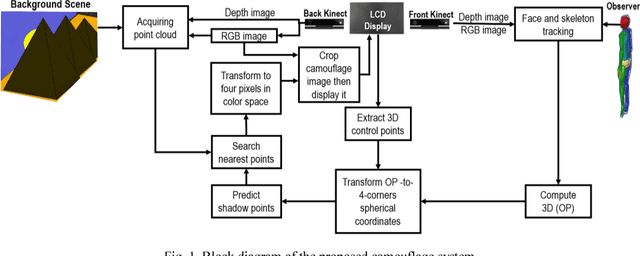
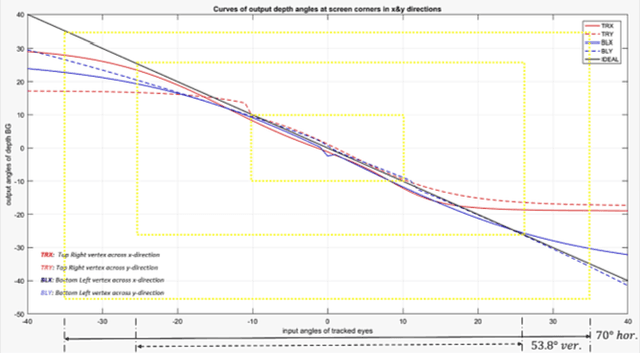
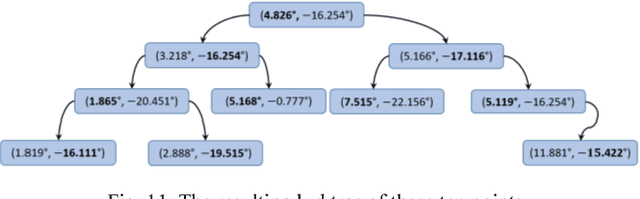

This paper proposes a new optical camouflage system that uses RGB-D cameras, for acquiring point cloud of background scene, and tracking observers eyes. This system enables a user to conceal an object located behind a display that surrounded by 3D objects. If we considered here the tracked point of observer s eyes is a light source, the system will work on estimating shadow shape of the display device that falls on the objects in background. The system uses the 3d observer s eyes and the locations of display corners to predict their shadow points which have nearest neighbors in the constructed point cloud of background scene.