 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRST-MODNet: Real-time Spatio-temporal Moving Object Detection for Autonomous Driving
Paper and Code
Dec 01, 2019
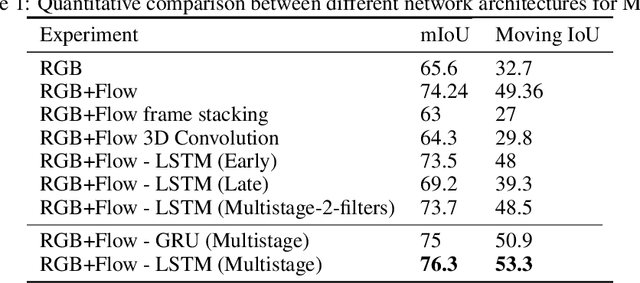


Moving Object Detection (MOD) is a critical task for autonomous vehicles as moving objects represent higher collision risk than static ones. The trajectory of the ego-vehicle is planned based on the future states of detected moving objects. It is quite challenging as the ego-motion has to be modelled and compensated to be able to understand the motion of the surrounding objects. In this work, we propose a real-time end-to-end CNN architecture for MOD utilizing spatio-temporal context to improve robustness. We construct a novel time-aware architecture exploiting temporal motion information embedded within sequential images in addition to explicit motion maps using optical flow images.We demonstrate the impact of our algorithm on KITTI dataset where we obtain an improvement of 8% relative to the baselines. We compare our algorithm with state-of-the-art methods and achieve competitive results on KITTI-Motion dataset in terms of accuracy at three times better run-time. The proposed algorithm runs at 23 fps on a standard desktop GPU targeting deployment on embedded platforms.