 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time safety assessment of trajectories for autonomous driving
May 05, 2021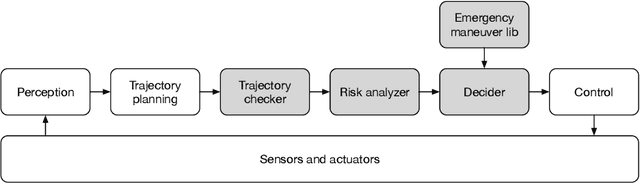
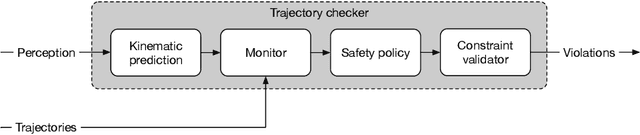

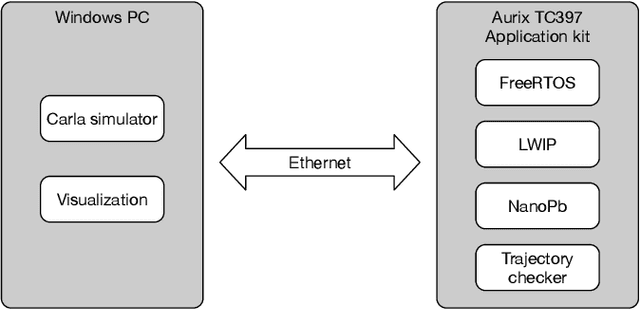
Autonomous vehicles (AVs) must always have a safe motion to guarantee that they are not causing any accidents. In an AV system, the motion of the vehicle is represented as a trajectory. A trajectory planning component is responsible to compute such a trajectory at run-time, taking into account the perception information about the environment, the dynamics of the vehicles, the predicted future states of other road users and a number of safety aspects. Due to the enormous amount of information to be considered, trajectory planning algorithms are complex, which makes it non-trivial to guarantee the safety of all planned trajectories. In this way, it is necessary to have an extra component to assess the safety of the planned trajectories at run-time. Such trajectory safety assessment component gives a diverse observation on the safety of AV trajectories and ensures that the AV only follows safe trajectories. We use the term trajectory checker to refer to the trajectory safety assessment component. The trajectory checker must evaluate planned trajectories against various safety rules, taking into account a large number of possibilities, including the worst-case behavior of other traffic participants. This must be done while guaranteeing hard real-time performance since the safety assessment is carried out while the vehicle is moving and in constant interaction with the environment. In this paper, we present a prototype of the trajectory checker we have developed at IVEX. We show how our approach works smoothly and accomplishes real-time constraints embedded in an Infineon Aurix TC397B automotive platform. Finally, we measure the performance of our trajectory checker prototype against a set of NCAPS-inspired scenarios.
FuseMODNet: Real-Time Camera and LiDAR based Moving Object Detection for robust low-light Autonomous Driving
Nov 21, 2019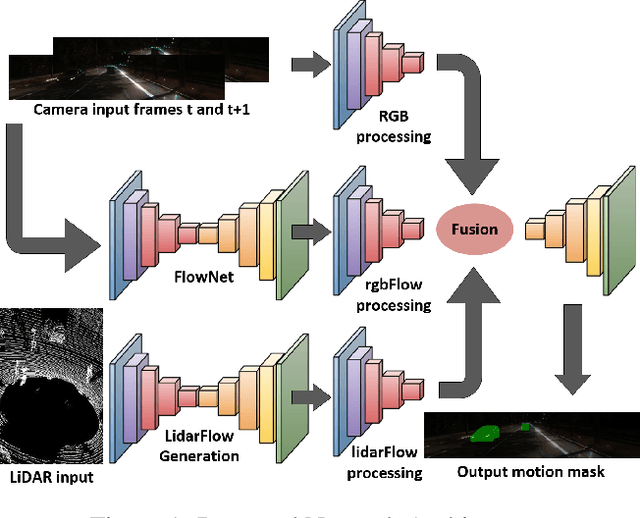
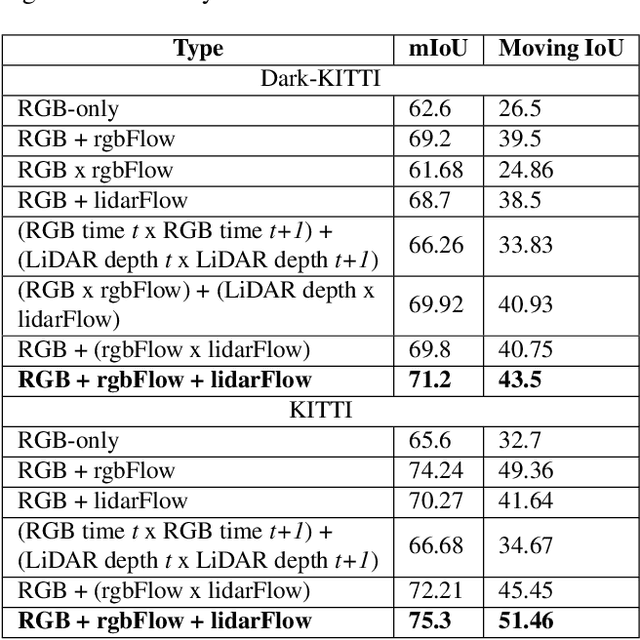


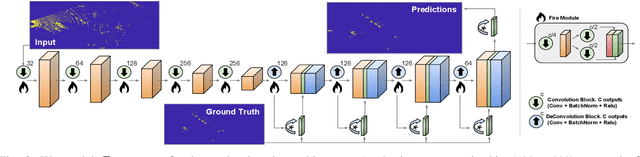
Moving object detection is a critical task for autonomous vehicles. As dynamic objects represent higher collision risk than static ones, our own ego-trajectories have to be planned attending to the future states of the moving elements of the scene. Motion can be perceived using temporal information such as optical flow. Conventional optical flow computation is based on camera sensors only, which makes it prone to failure in conditions with low illumination. On the other hand, LiDAR sensors are independent of illumination, as they measure the time-of-flight of their own emitted lasers. In this work, we propose a robust and real-time CNN architecture for Moving Object Detection (MOD) under low-light conditions by capturing motion information from both camera and LiDAR sensors. We demonstrate the impact of our algorithm on KITTI dataset where we simulate a low-light environment creating a novel dataset "Dark KITTI". We obtain a 10.1% relative improvement on Dark-KITTI, and a 4.25% improvement on standard KITTI relative to our baselines. The proposed algorithm runs at 18 fps on a standard desktop GPU using $256\times1224$ resolution images.
Improving Map Re-localization with Deep 'Movable' Objects Segmentation on 3D LiDAR Point Clouds
Oct 08, 2019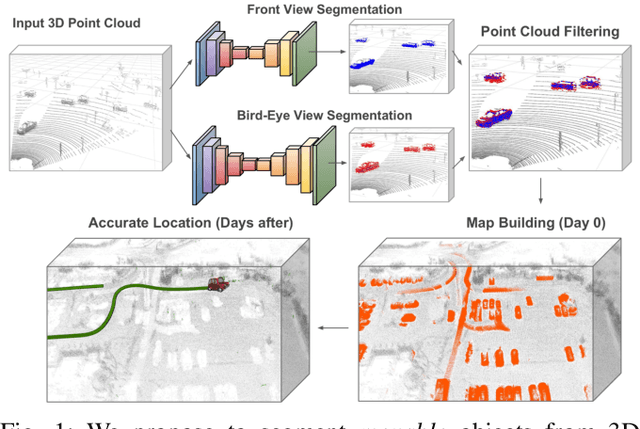
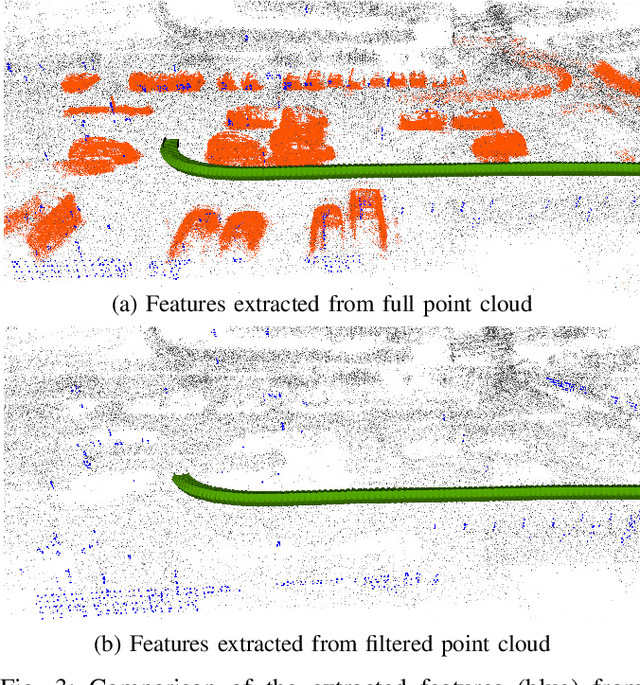
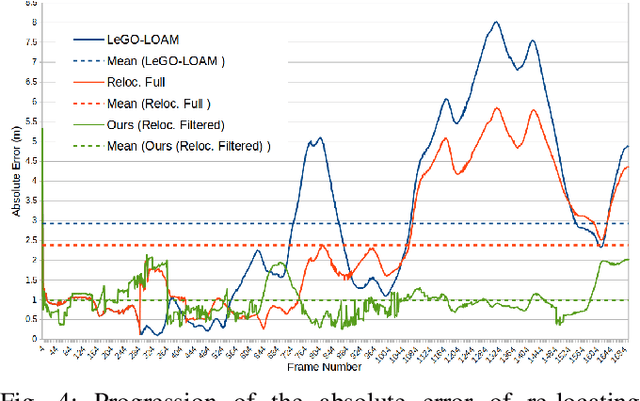
Localization and Mapping is an essential component to enable Autonomous Vehicles navigation, and requires an accuracy exceeding that of commercial GPS-based systems. Current odometry and mapping algorithms are able to provide this accurate information. However, the lack of robustness of these algorithms against dynamic obstacles and environmental changes, even for short time periods, forces the generation of new maps on every session without taking advantage of previously obtained ones. In this paper we propose the use of a deep learning architecture to segment movable objects from 3D LiDAR point clouds in order to obtain longer-lasting 3D maps. This will in turn allow for better, faster and more accurate re-localization and trajectoy estimation on subsequent days. We show the effectiveness of our approach in a very dynamic and cluttered scenario, a supermarket parking lot. For that, we record several sequences on different days and compare localization errors with and without our movable objects segmentation method. Results show that we are able to accurately re-locate over a filtered map, consistently reducing trajectory errors between an average of 35.1% with respect to a non-filtered map version and of 47.9% with respect to a standalone map created on the current session.
Hallucinating Dense Optical Flow from Sparse Lidar for Autonomous Vehicles
Aug 30, 2018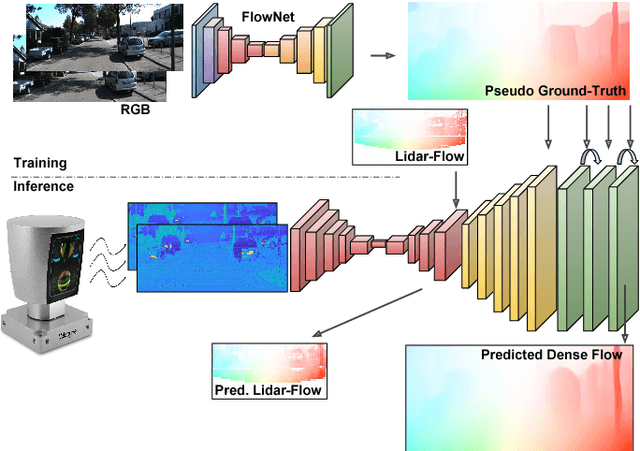
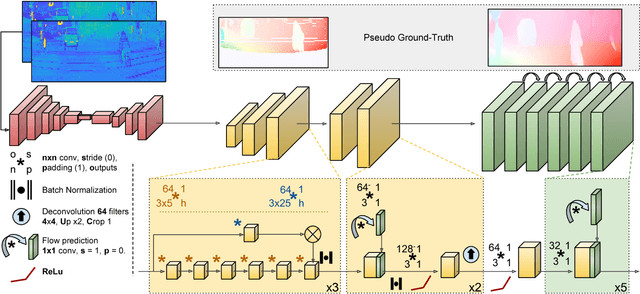
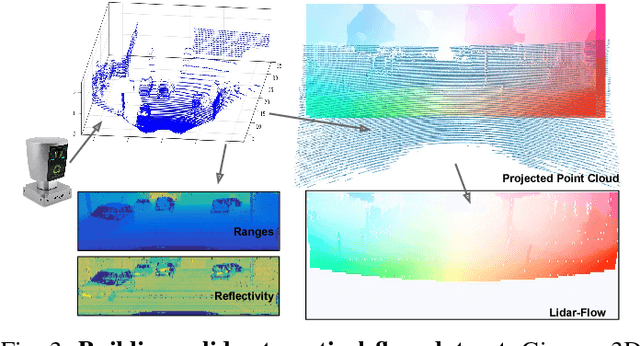

In this paper we propose a novel approach to estimate dense optical flow from sparse lidar data acquired on an autonomous vehicle. This is intended to be used as a drop-in replacement of any image-based optical flow system when images are not reliable due to e.g. adverse weather conditions or at night. In order to infer high resolution 2D flows from discrete range data we devise a three-block architecture of multiscale filters that combines multiple intermediate objectives, both in the lidar and image domain. To train this network we introduce a dataset with approximately 20K lidar samples of the Kitti dataset which we have augmented with a pseudo ground-truth image-based optical flow computed using FlowNet2. We demonstrate the effectiveness of our approach on Kitti, and show that despite using the low-resolution and sparse measurements of the lidar, we can regress dense optical flow maps which are at par with those estimated with image-based methods.
Deep Lidar CNN to Understand the Dynamics of Moving Vehicles
Aug 30, 2018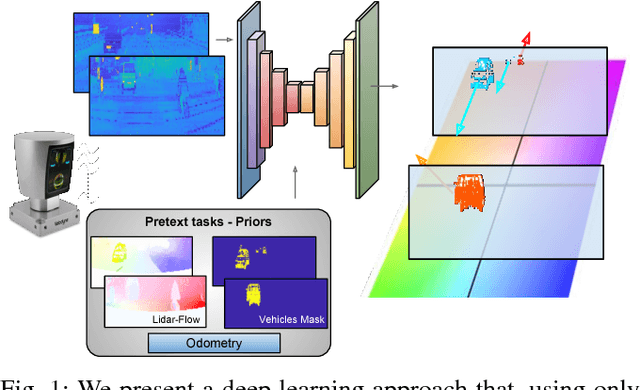

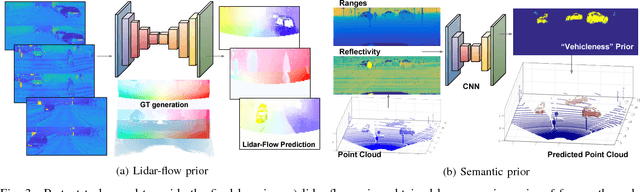
Perception technologies in Autonomous Driving are experiencing their golden age due to the advances in Deep Learning. Yet, most of these systems rely on the semantically rich information of RGB images. Deep Learning solutions applied to the data of other sensors typically mounted on autonomous cars (e.g. lidars or radars) are not explored much. In this paper we propose a novel solution to understand the dynamics of moving vehicles of the scene from only lidar information. The main challenge of this problem stems from the fact that we need to disambiguate the proprio-motion of the 'observer' vehicle from that of the external 'observed' vehicles. For this purpose, we devise a CNN architecture which at testing time is fed with pairs of consecutive lidar scans. However, in order to properly learn the parameters of this network, during training we introduce a series of so-called pretext tasks which also leverage on image data. These tasks include semantic information about vehicleness and a novel lidar-flow feature which combines standard image-based optical flow with lidar scans. We obtain very promising results and show that including distilled image information only during training, allows improving the inference results of the network at test time, even when image data is no longer used.
Deconvolutional Networks for Point-Cloud Vehicle Detection and Tracking in Driving Scenarios
Aug 23, 2018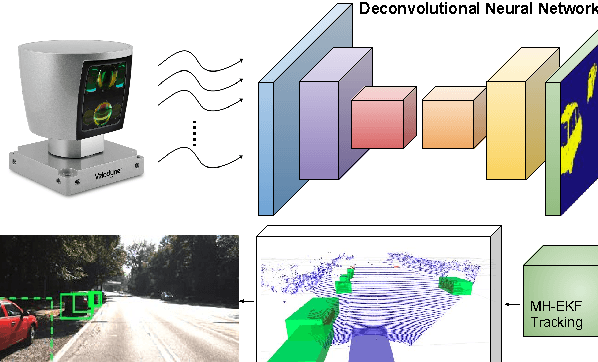
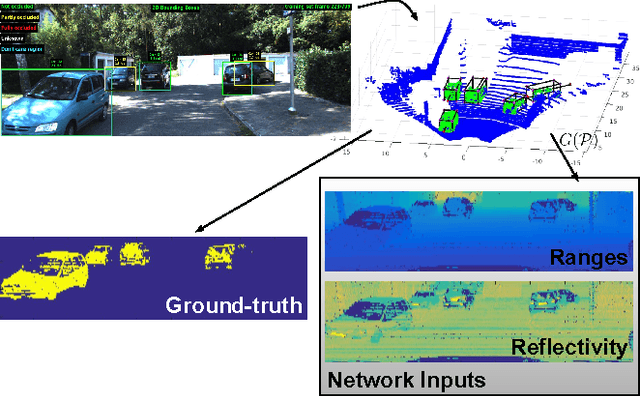
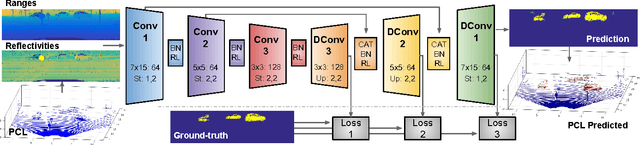

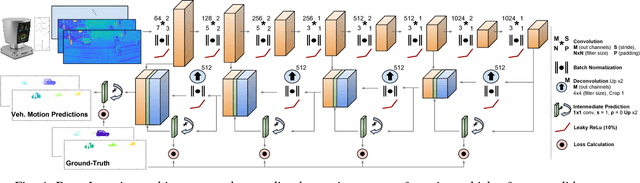
Vehicle detection and tracking is a core ingredient for developing autonomous driving applications in urban scenarios. Recent image-based Deep Learning (DL) techniques are obtaining breakthrough results in these perceptive tasks. However, DL research has not yet advanced much towards processing 3D point clouds from lidar range-finders. These sensors are very common in autonomous vehicles since, despite not providing as semantically rich information as images, their performance is more robust under harsh weather conditions than vision sensors. In this paper we present a full vehicle detection and tracking system that works with 3D lidar information only. Our detection step uses a Convolutional Neural Network (CNN) that receives as input a featured representation of the 3D information provided by a Velodyne HDL-64 sensor and returns a per-point classification of whether it belongs to a vehicle or not. The classified point cloud is then geometrically processed to generate observations for a multi-object tracking system implemented via a number of Multi-Hypothesis Extended Kalman Filters (MH-EKF) that estimate the position and velocity of the surrounding vehicles. The system is thoroughly evaluated on the KITTI tracking dataset, and we show the performance boost provided by our CNN-based vehicle detector over a standard geometric approach. Our lidar-based approach uses about a 4% of the data needed for an image-based detector with similarly competitive results.
Joint Coarse-And-Fine Reasoning for Deep Optical Flow
Aug 22, 2018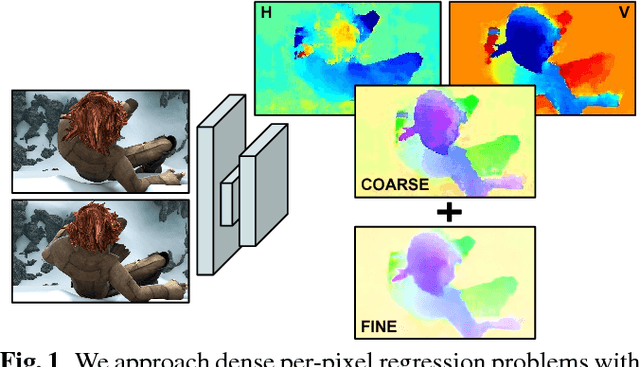
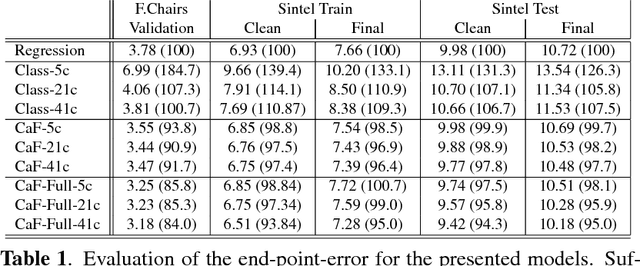
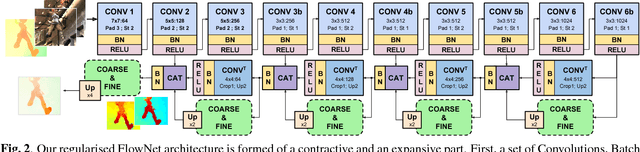
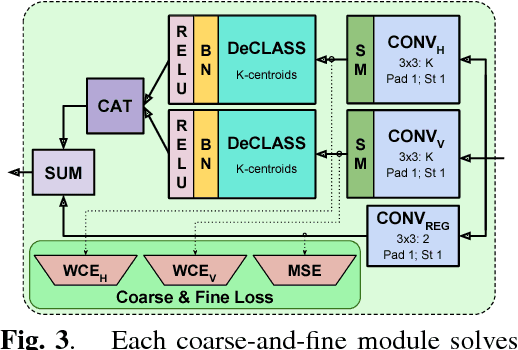
We propose a novel representation for dense pixel-wise estimation tasks using CNNs that boosts accuracy and reduces training time, by explicitly exploiting joint coarse-and-fine reasoning. The coarse reasoning is performed over a discrete classification space to obtain a general rough solution, while the fine details of the solution are obtained over a continuous regression space. In our approach both components are jointly estimated, which proved to be beneficial for improving estimation accuracy. Additionally, we propose a new network architecture, which combines coarse and fine components by treating the fine estimation as a refinement built on top of the coarse solution, and therefore adding details to the general prediction. We apply our approach to the challenging problem of optical flow estimation and empirically validate it against state-of-the-art CNN-based solutions trained from scratch and tested on large optical flow datasets.