 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStickyPillars: Robust feature matching on point clouds using Graph Neural Networks
Feb 10, 2020
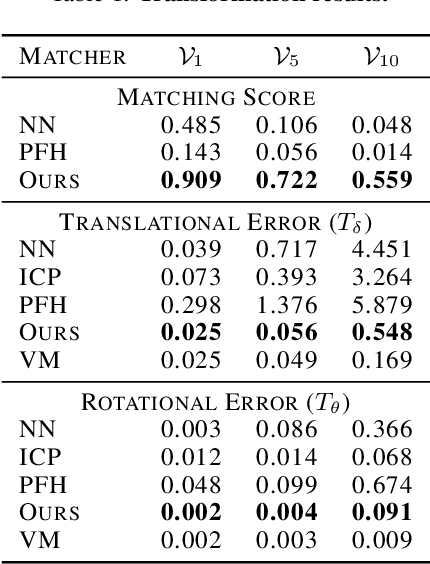
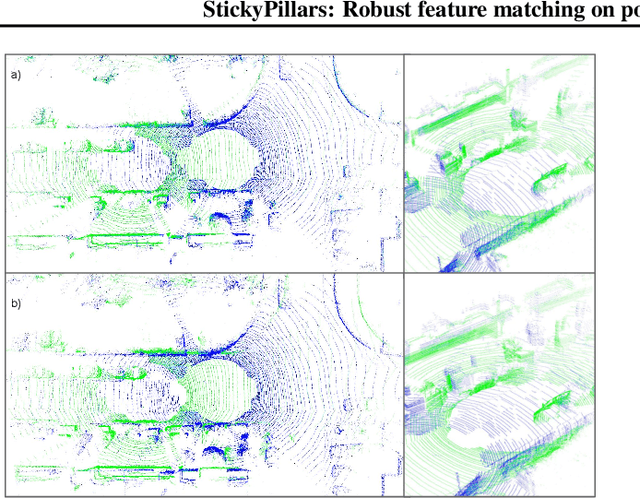
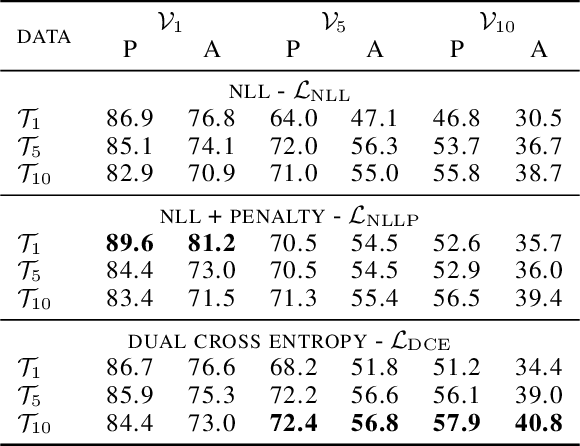
StickyPillars introduces a sparse feature matching method on point clouds. It is the first approach applying Graph Neural Networks on point clouds to stick points of interest. The feature estimation and assignment relies on the optimal transport problem, where the cost is based on the neural network itself. We utilize a Graph Neural Network for context aggregation with the aid of multihead self and cross attention. In contrast to image based feature matching methods, the architecture learns feature extraction in an end-to-end manner. Hence, the approach does not rely on handcrafted features. Our method outperforms state-of-the art matching algorithms, while providing real-time capability.
Improving Map Re-localization with Deep 'Movable' Objects Segmentation on 3D LiDAR Point Clouds
Oct 08, 2019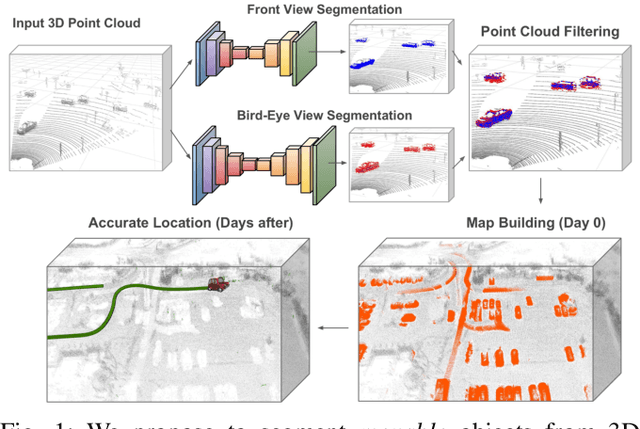
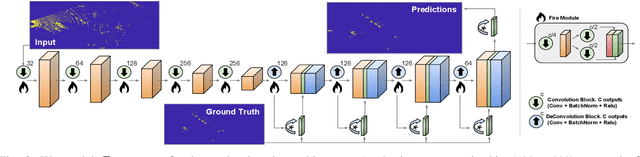
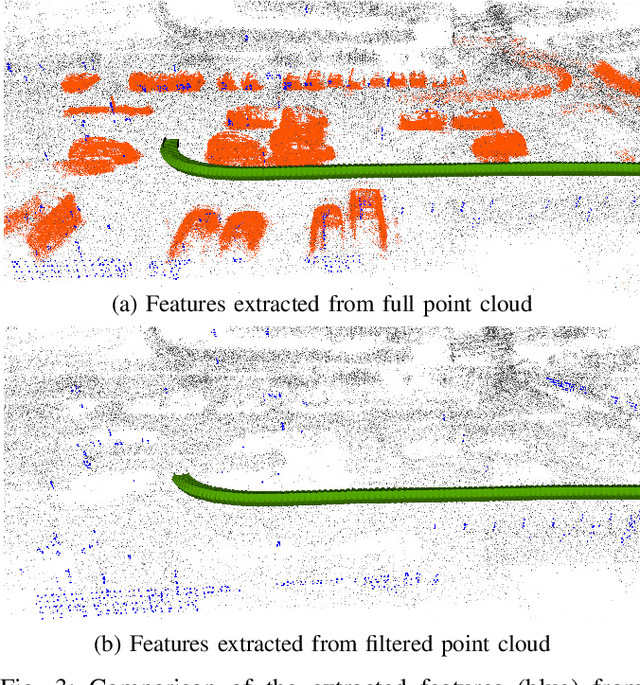
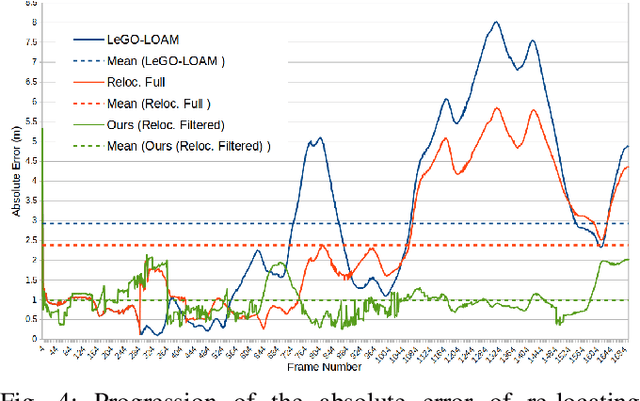
Localization and Mapping is an essential component to enable Autonomous Vehicles navigation, and requires an accuracy exceeding that of commercial GPS-based systems. Current odometry and mapping algorithms are able to provide this accurate information. However, the lack of robustness of these algorithms against dynamic obstacles and environmental changes, even for short time periods, forces the generation of new maps on every session without taking advantage of previously obtained ones. In this paper we propose the use of a deep learning architecture to segment movable objects from 3D LiDAR point clouds in order to obtain longer-lasting 3D maps. This will in turn allow for better, faster and more accurate re-localization and trajectoy estimation on subsequent days. We show the effectiveness of our approach in a very dynamic and cluttered scenario, a supermarket parking lot. For that, we record several sequences on different days and compare localization errors with and without our movable objects segmentation method. Results show that we are able to accurately re-locate over a filtered map, consistently reducing trajectory errors between an average of 35.1% with respect to a non-filtered map version and of 47.9% with respect to a standalone map created on the current session.
Points2Pix: 3D Point-Cloud to Image Translation using conditional Generative Adversarial Networks
Jan 26, 2019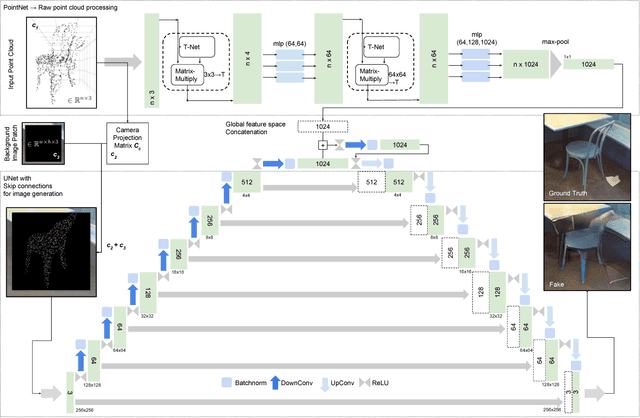
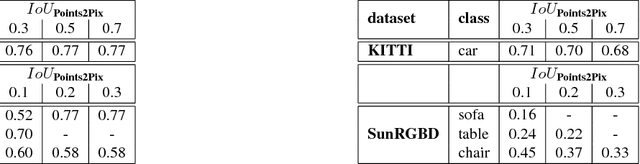
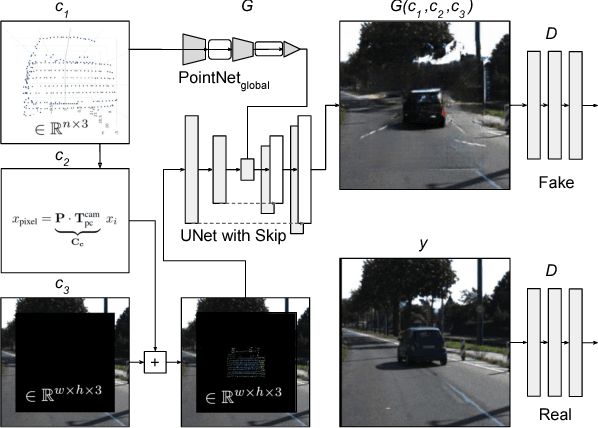

We present the first approach for 3D point-cloud to image translation based on conditional Generative Adversarial Networks (cGAN). The model handles multi-modal information sources from different domains, i.e. raw point-sets and images. The generator is capable of processing three conditions, whereas the point-cloud is encoded as raw point-set and camera projection. An image background patch is used as constraint to bias environmental texturing. A global approximation function within the generator is directly applied on the point-cloud (Point-Net). Hence, the representative learning model incorporates global 3D characteristics directly at the latent feature space. Conditions are used to bias the background and the viewpoint of the generated image. This opens up new ways in augmenting or texturing 3D data to aim the generation of fully individual images. We successfully evaluated our method on the Kitti and SunRGBD dataset with an outstanding object detection inception score.