 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVM-MODNet: Vehicle Motion aware Moving Object Detection for Autonomous Driving
Paper and Code
Apr 22, 2021


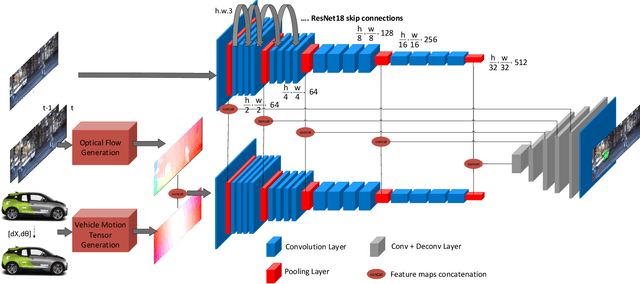
Moving object Detection (MOD) is a critical task in autonomous driving as moving agents around the ego-vehicle need to be accurately detected for safe trajectory planning. It also enables appearance agnostic detection of objects based on motion cues. There are geometric challenges like motion-parallax ambiguity which makes it a difficult problem. In this work, we aim to leverage the vehicle motion information and feed it into the model to have an adaptation mechanism based on ego-motion. The motivation is to enable the model to implicitly perform ego-motion compensation to improve performance. We convert the six degrees of freedom vehicle motion into a pixel-wise tensor which can be fed as input to the CNN model. The proposed model using Vehicle Motion Tensor (VMT) achieves an absolute improvement of 5.6% in mIoU over the baseline architecture. We also achieve state-of-the-art results on the public KITTI_MoSeg_Extended dataset even compared to methods which make use of LiDAR and additional input frames. Our model is also lightweight and runs at 85 fps on a TitanX GPU. Qualitative results are provided in https://youtu.be/ezbfjti-kTk.