 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelTransformer: Balancing the Visual Relationship Detection from Local Context, Scene and Memory
Paper and Code
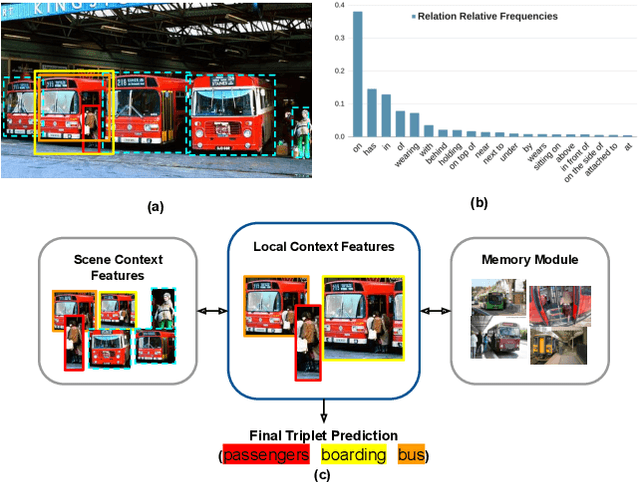
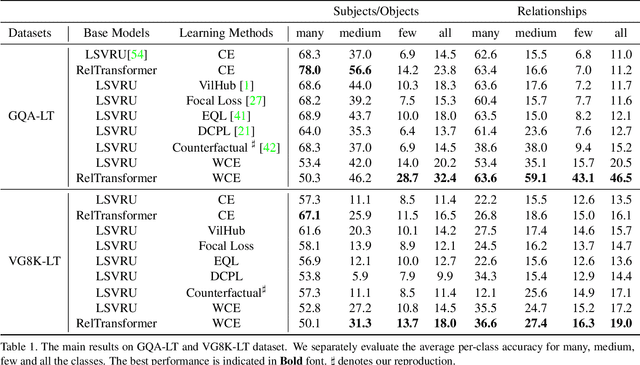
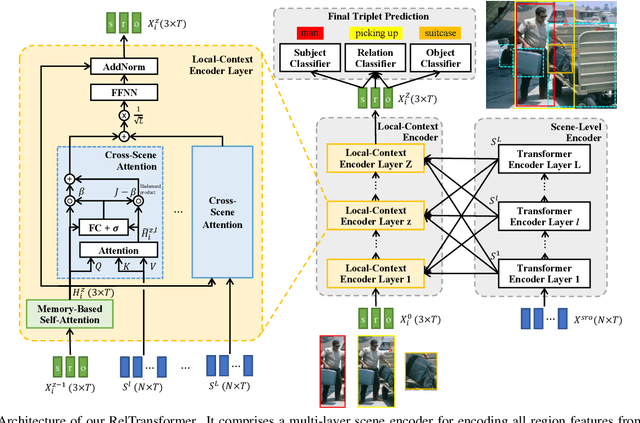
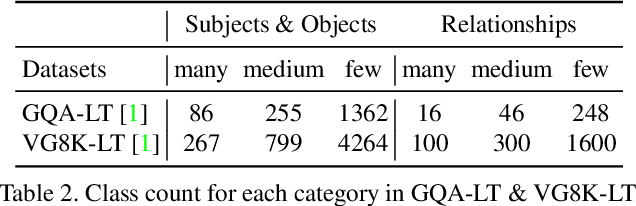
Visual relationship recognition (VRR) is a fundamental scene understanding task. The structure that VRR provides is essential to improve the AI interpretability in downstream tasks such as image captioning and visual question answering. Several recent studies showed that the long-tail problem in VRR is even more critical than that in object recognition due to the compositional complexity and structure. To overcome this limitation, we propose a novel transformer-based framework, dubbed as RelTransformer, which performs relationship prediction using rich semantic features from multiple image levels. We assume that more abundantcon textual features can generate more accurate and discriminative relationships, which can be useful when sufficient training data are lacking. The key feature of our model is its ability to aggregate three different-level features (local context, scene, and dataset-level) to compositionally predict the visual relationship. We evaluate our model on the visual genome and two "long-tail" VRR datasets, GQA-LT and VG8k-LT. Extensive experiments demonstrate that our RelTransformer could improve over the state-of-the-art baselines on all the datasets. In addition, our model significantly improves the accuracy of GQA-LT by 27.4% upon the best baselines on tail-relationship prediction. Our code is available in https://github.com/Vision-CAIR/RelTransformer.