 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStellar: Systematic Evaluation of Human-Centric Personalized Text-to-Image Methods
Dec 11, 2023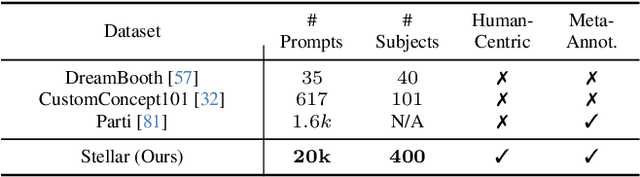



In this work, we systematically study the problem of personalized text-to-image generation, where the output image is expected to portray information about specific human subjects. E.g., generating images of oneself appearing at imaginative places, interacting with various items, or engaging in fictional activities. To this end, we focus on text-to-image systems that input a single image of an individual to ground the generation process along with text describing the desired visual context. Our first contribution is to fill the literature gap by curating high-quality, appropriate data for this task. Namely, we introduce a standardized dataset (Stellar) that contains personalized prompts coupled with images of individuals that is an order of magnitude larger than existing relevant datasets and where rich semantic ground-truth annotations are readily available. Having established Stellar to promote cross-systems fine-grained comparisons further, we introduce a rigorous ensemble of specialized metrics that highlight and disentangle fundamental properties such systems should obey. Besides being intuitive, our new metrics correlate significantly more strongly with human judgment than currently used metrics on this task. Last but not least, drawing inspiration from the recent works of ELITE and SDXL, we derive a simple yet efficient, personalized text-to-image baseline that does not require test-time fine-tuning for each subject and which sets quantitatively and in human trials a new SoTA. For more information, please visit our project's website: https://stellar-gen-ai.github.io/.
Plotting Behind the Scenes: Towards Learnable Game Engines
Mar 23, 2023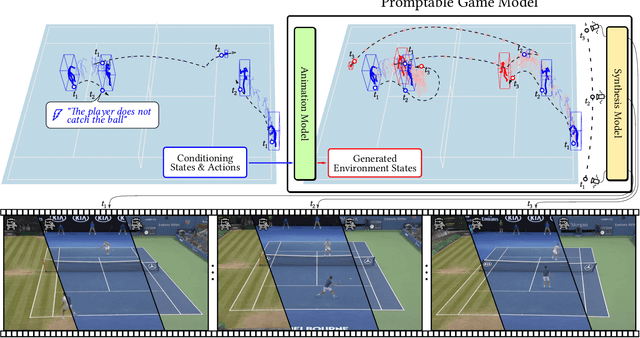
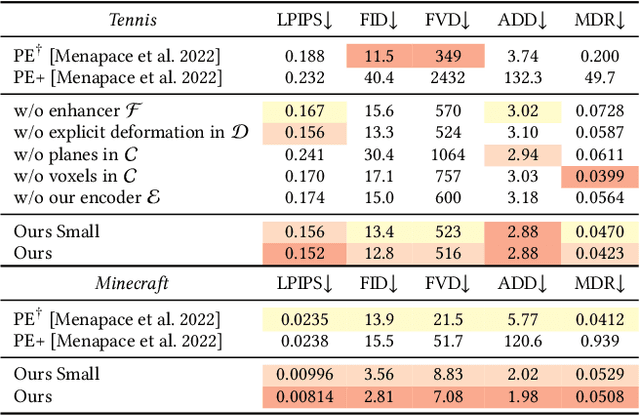
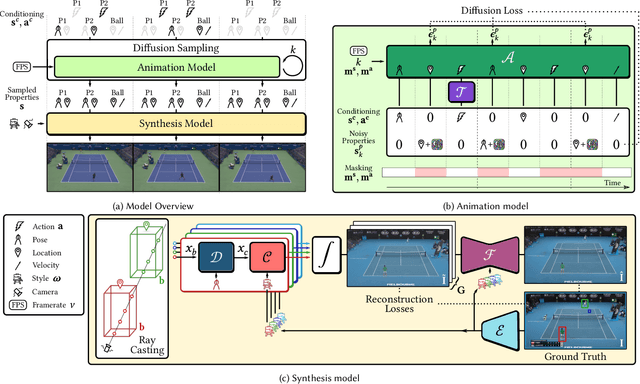
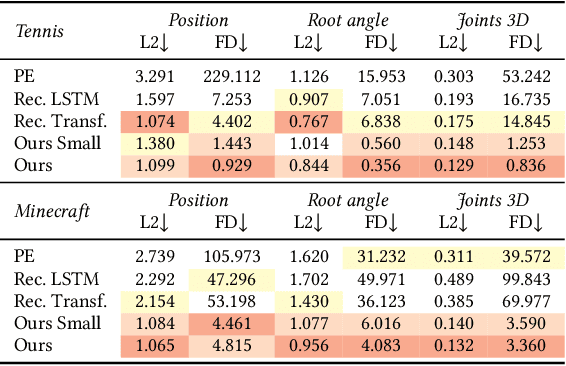
Game engines are powerful tools in computer graphics. Their power comes at the immense cost of their development. In this work, we present a framework to train game-engine-like neural models, solely from monocular annotated videos. The result-a Learnable Game Engine (LGE)-maintains states of the scene, objects and agents in it, and enables rendering the environment from a controllable viewpoint. Similarly to a game engine, it models the logic of the game and the underlying rules of physics, to make it possible for a user to play the game by specifying both high- and low-level action sequences. Most captivatingly, our LGE unlocks the director's mode, where the game is played by plotting behind the scenes, specifying high-level actions and goals for the agents in the form of language and desired states. This requires learning "game AI", encapsulated by our animation model, to navigate the scene using high-level constraints, play against an adversary, devise the strategy to win a point. The key to learning such game AI is the exploitation of a large and diverse text corpus, collected in this work, describing detailed actions in a game and used to train our animation model. To render the resulting state of the environment and its agents, we use a compositional NeRF representation used in our synthesis model. To foster future research, we present newly collected, annotated and calibrated large-scale Tennis and Minecraft datasets. Our method significantly outperforms existing neural video game simulators in terms of rendering quality. Besides, our LGEs unlock applications beyond capabilities of the current state of the art. Our framework, data, and models are available at https://learnable-game-engines.github.io/lge-website.
ScanEnts3D: Exploiting Phrase-to-3D-Object Correspondences for Improved Visio-Linguistic Models in 3D Scenes
Dec 12, 2022

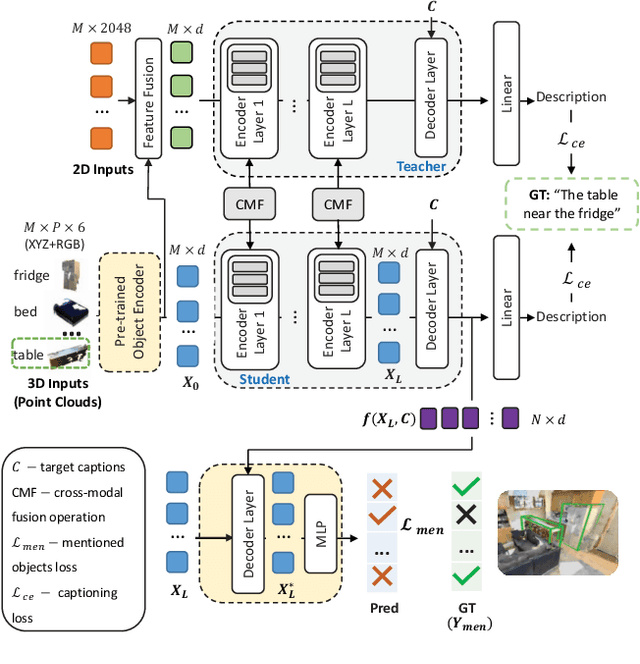
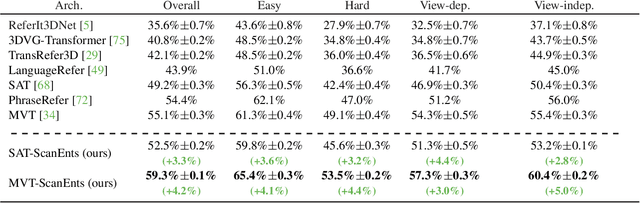
The two popular datasets ScanRefer [16] and ReferIt3D [3] connect natural language to real-world 3D data. In this paper, we curate a large-scale and complementary dataset extending both the aforementioned ones by associating all objects mentioned in a referential sentence to their underlying instances inside a 3D scene. Specifically, our Scan Entities in 3D (ScanEnts3D) dataset provides explicit correspondences between 369k objects across 84k natural referential sentences, covering 705 real-world scenes. Crucially, we show that by incorporating intuitive losses that enable learning from this novel dataset, we can significantly improve the performance of several recently introduced neural listening architectures, including improving the SoTA in both the Nr3D and ScanRefer benchmarks by 4.3% and 5.0%, respectively. Moreover, we experiment with competitive baselines and recent methods for the task of language generation and show that, as with neural listeners, 3D neural speakers can also noticeably benefit by training with ScanEnts3D, including improving the SoTA by 13.2 CIDEr points on the Nr3D benchmark. Overall, our carefully conducted experimental studies strongly support the conclusion that, by learning on ScanEnts3D, commonly used visio-linguistic 3D architectures can become more efficient and interpretable in their generalization without needing to provide these newly collected annotations at test time. The project's webpage is https://scanents3d.github.io/ .
LADIS: Language Disentanglement for 3D Shape Editing
Dec 09, 2022
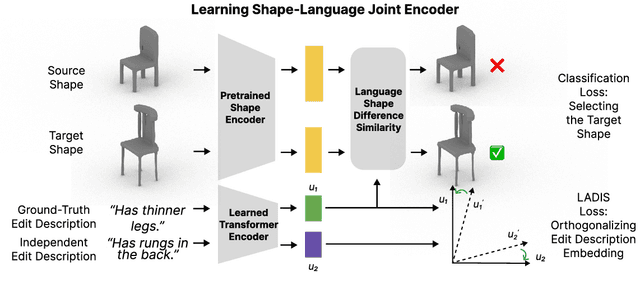
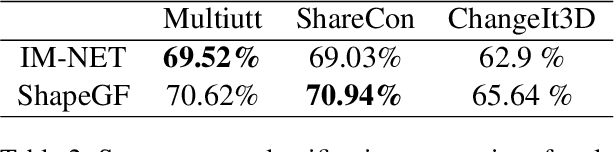
Natural language interaction is a promising direction for democratizing 3D shape design. However, existing methods for text-driven 3D shape editing face challenges in producing decoupled, local edits to 3D shapes. We address this problem by learning disentangled latent representations that ground language in 3D geometry. To this end, we propose a complementary tool set including a novel network architecture, a disentanglement loss, and a new editing procedure. Additionally, to measure edit locality, we define a new metric that we call part-wise edit precision. We show that our method outperforms existing SOTA methods by 20% in terms of edit locality, and up to 6.6% in terms of language reference resolution accuracy. Our work suggests that by solely disentangling language representations, downstream 3D shape editing can become more local to relevant parts, even if the model was never given explicit part-based supervision.
Affection: Learning Affective Explanations for Real-World Visual Data
Oct 04, 2022
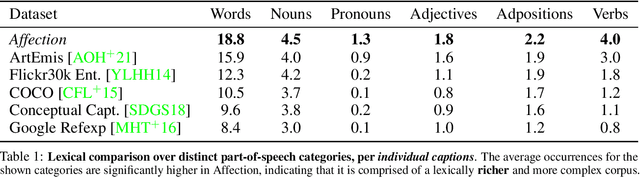
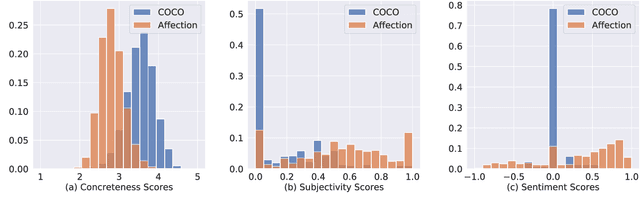
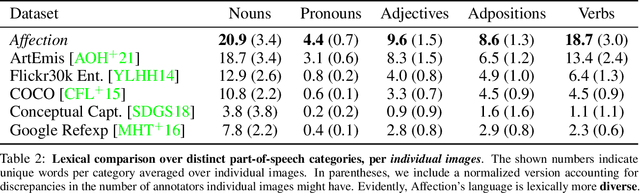
In this work, we explore the emotional reactions that real-world images tend to induce by using natural language as the medium to express the rationale behind an affective response to a given visual stimulus. To embark on this journey, we introduce and share with the research community a large-scale dataset that contains emotional reactions and free-form textual explanations for 85,007 publicly available images, analyzed by 6,283 annotators who were asked to indicate and explain how and why they felt in a particular way when observing a specific image, producing a total of 526,749 responses. Even though emotional reactions are subjective and sensitive to context (personal mood, social status, past experiences) - we show that there is significant common ground to capture potentially plausible emotional responses with a large support in the subject population. In light of this crucial observation, we ask the following questions: i) Can we develop multi-modal neural networks that provide reasonable affective responses to real-world visual data, explained with language? ii) Can we steer such methods towards producing explanations with varying degrees of pragmatic language or justifying different emotional reactions while adapting to the underlying visual stimulus? Finally, iii) How can we evaluate the performance of such methods for this novel task? With this work, we take the first steps in addressing all of these questions, thus paving the way for richer, more human-centric, and emotionally-aware image analysis systems. Our introduced dataset and all developed methods are available on https://affective-explanations.org
Quantized GAN for Complex Music Generation from Dance Videos
Apr 01, 2022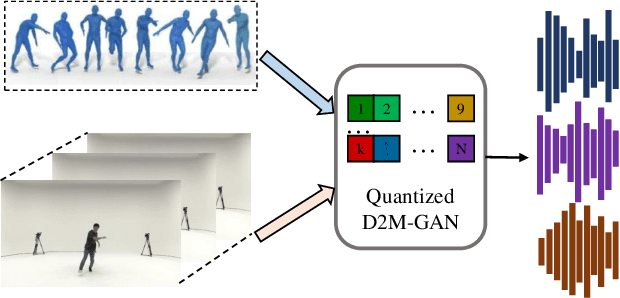
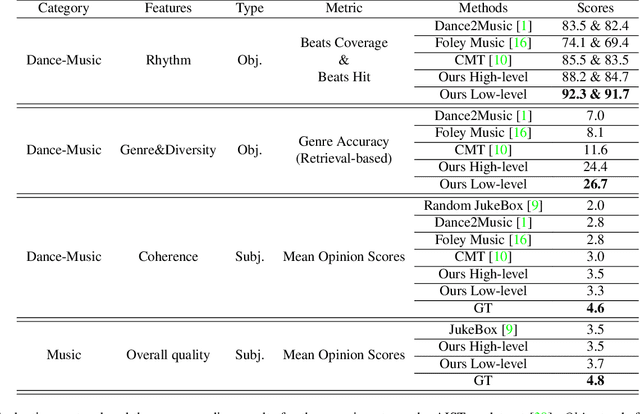
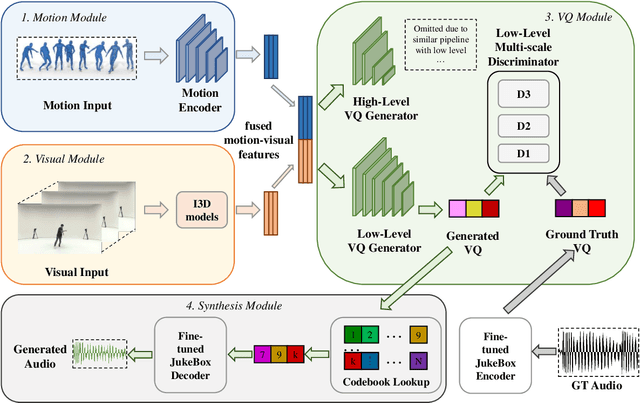
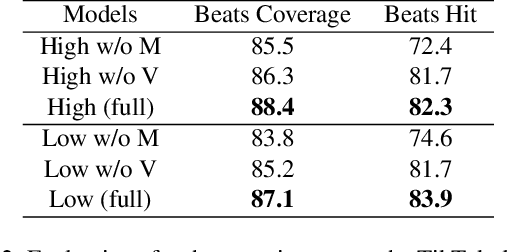
We present Dance2Music-GAN (D2M-GAN), a novel adversarial multi-modal framework that generates complex musical samples conditioned on dance videos. Our proposed framework takes dance video frames and human body motion as input, and learns to generate music samples that plausibly accompany the corresponding input. Unlike most existing conditional music generation works that generate specific types of mono-instrumental sounds using symbolic audio representations (e.g., MIDI), and that heavily rely on pre-defined musical synthesizers, in this work we generate dance music in complex styles (e.g., pop, breakdancing, etc.) by employing a Vector Quantized (VQ) audio representation, and leverage both its generality and the high abstraction capacity of its symbolic and continuous counterparts. By performing an extensive set of experiments on multiple datasets, and following a comprehensive evaluation protocol, we assess the generative quality of our approach against several alternatives. The quantitative results, which measure the music consistency, beats correspondence, and music diversity, clearly demonstrate the effectiveness of our proposed method. Last but not least, we curate a challenging dance-music dataset of in-the-wild TikTok videos, which we use to further demonstrate the efficacy of our approach in real-world applications - and which we hope to serve as a starting point for relevant future research.
NeROIC: Neural Rendering of Objects from Online Image Collections
Jan 07, 2022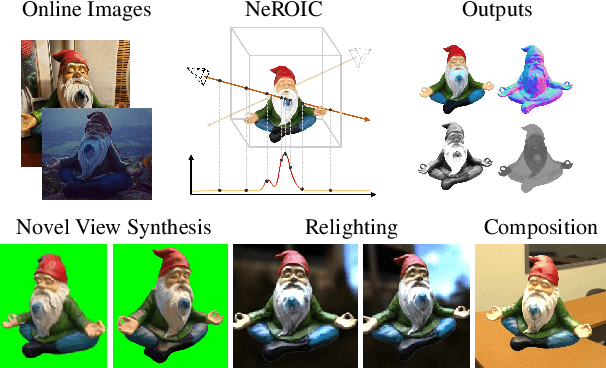
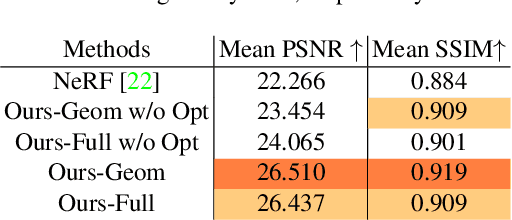
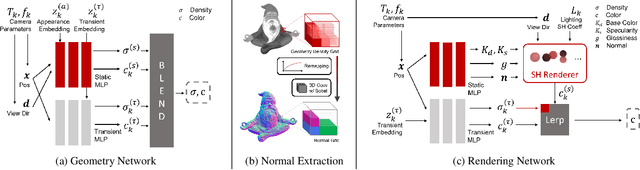
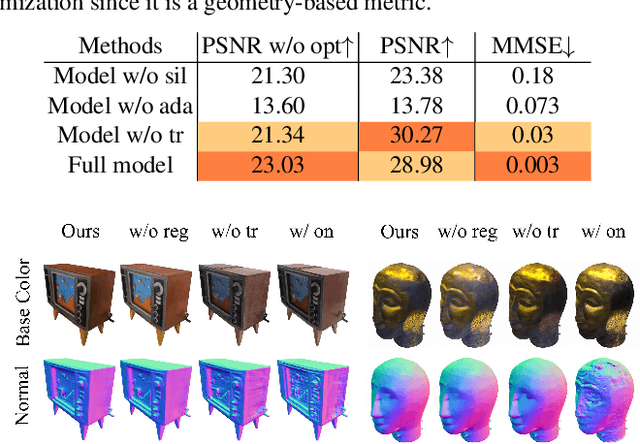
We present a novel method to acquire object representations from online image collections, capturing high-quality geometry and material properties of arbitrary objects from photographs with varying cameras, illumination, and backgrounds. This enables various object-centric rendering applications such as novel-view synthesis, relighting, and harmonized background composition from challenging in-the-wild input. Using a multi-stage approach extending neural radiance fields, we first infer the surface geometry and refine the coarsely estimated initial camera parameters, while leveraging coarse foreground object masks to improve the training efficiency and geometry quality. We also introduce a robust normal estimation technique which eliminates the effect of geometric noise while retaining crucial details. Lastly, we extract surface material properties and ambient illumination, represented in spherical harmonics with extensions that handle transient elements, e.g. sharp shadows. The union of these components results in a highly modular and efficient object acquisition framework. Extensive evaluations and comparisons demonstrate the advantages of our approach in capturing high-quality geometry and appearance properties useful for rendering applications.
PartGlot: Learning Shape Part Segmentation from Language Reference Games
Dec 13, 2021
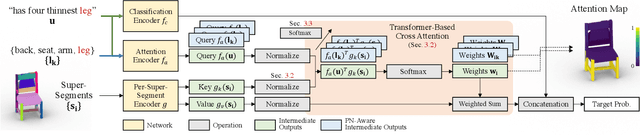


We introduce PartGlot, a neural framework and associated architectures for learning semantic part segmentation of 3D shape geometry, based solely on part referential language. We exploit the fact that linguistic descriptions of a shape can provide priors on the shape's parts -- as natural language has evolved to reflect human perception of the compositional structure of objects, essential to their recognition and use. For training, we use the paired geometry / language data collected in the ShapeGlot work for their reference game, where a speaker creates an utterance to differentiate a target shape from two distractors and the listener has to find the target based on this utterance. Our network is designed to solve this target discrimination problem, carefully incorporating a Transformer-based attention module so that the output attention can precisely highlight the semantic part or parts described in the language. Furthermore, the network operates without any direct supervision on the 3D geometry itself. Surprisingly, we further demonstrate that the learned part information is generalizable to shape classes unseen during training. Our approach opens the possibility of learning 3D shape parts from language alone, without the need for large-scale part geometry annotations, thus facilitating annotation acquisition.
ArtEmis: Affective Language for Visual Art
Jan 19, 2021


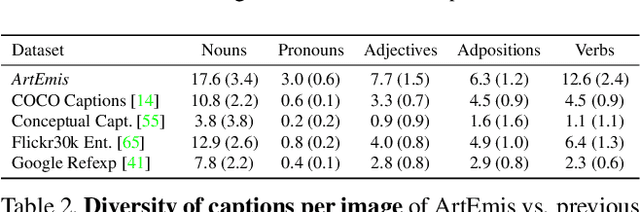
We present a novel large-scale dataset and accompanying machine learning models aimed at providing a detailed understanding of the interplay between visual content, its emotional effect, and explanations for the latter in language. In contrast to most existing annotation datasets in computer vision, we focus on the affective experience triggered by visual artworks and ask the annotators to indicate the dominant emotion they feel for a given image and, crucially, to also provide a grounded verbal explanation for their emotion choice. As we demonstrate below, this leads to a rich set of signals for both the objective content and the affective impact of an image, creating associations with abstract concepts (e.g., "freedom" or "love"), or references that go beyond what is directly visible, including visual similes and metaphors, or subjective references to personal experiences. We focus on visual art (e.g., paintings, artistic photographs) as it is a prime example of imagery created to elicit emotional responses from its viewers. Our dataset, termed ArtEmis, contains 439K emotion attributions and explanations from humans, on 81K artworks from WikiArt. Building on this data, we train and demonstrate a series of captioning systems capable of expressing and explaining emotions from visual stimuli. Remarkably, the captions produced by these systems often succeed in reflecting the semantic and abstract content of the image, going well beyond systems trained on existing datasets. The collected dataset and developed methods are available at https://artemisdataset.org.
Long-tail Visual Relationship Recognition with a Visiolinguistic Hubless Loss
Apr 20, 2020
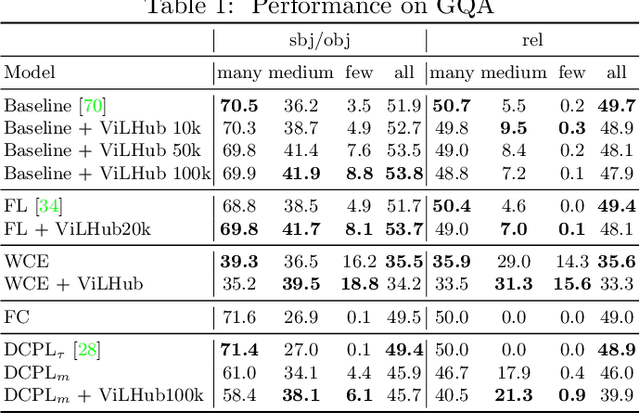
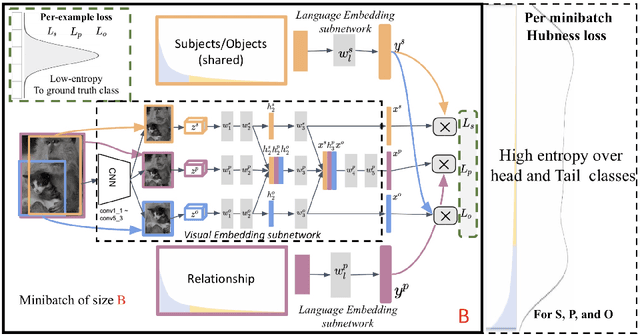
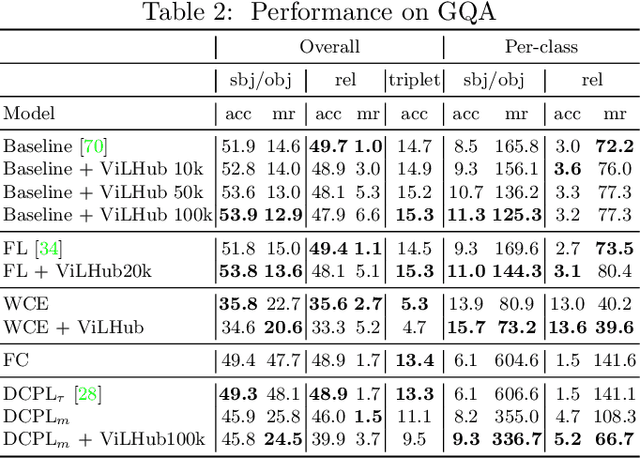
Scaling up the vocabulary and complexity of current visual understanding systems is necessary in order to bridge the gap between human and machine visual intelligence. However, a crucial impediment to this end lies in the difficulty of generalizing to data distributions that come from real-world scenarios. Typically such distributions follow Zipf's law which states that only a small portion of the collected object classes will have abundant examples (head); while most classes will contain just a few (tail). In this paper, we propose to study a novel task concerning the generalization of visual relationships that are on the distribution's tail, i.e. we investigate how to help AI systems to better recognize rare relationships like <S:dog, P:riding, O:horse>, where the subject S, predicate P, and/or the object O come from the tail of the corresponding distributions. To achieve this goal, we first introduce two large-scale visual-relationship detection benchmarks built upon the widely used Visual Genome and GQA datasets. We also propose an intuitive evaluation protocol that gives credit to classifiers who prefer concepts that are semantically close to the ground truth class according to wordNet- or word2vec-induced metrics. Finally, we introduce a visiolinguistic version of a Hubless loss which we show experimentally that it consistently encourages classifiers to be more predictive of the tail classes while still being accurate on head classes. Our code and models are available on http://bit.ly/LTVRR.