 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStellar: Systematic Evaluation of Human-Centric Personalized Text-to-Image Methods
Dec 11, 2023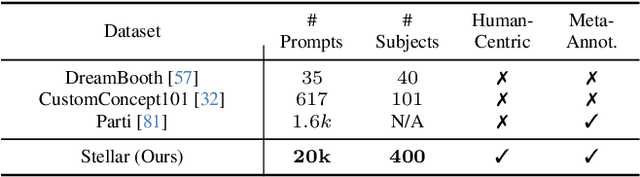



In this work, we systematically study the problem of personalized text-to-image generation, where the output image is expected to portray information about specific human subjects. E.g., generating images of oneself appearing at imaginative places, interacting with various items, or engaging in fictional activities. To this end, we focus on text-to-image systems that input a single image of an individual to ground the generation process along with text describing the desired visual context. Our first contribution is to fill the literature gap by curating high-quality, appropriate data for this task. Namely, we introduce a standardized dataset (Stellar) that contains personalized prompts coupled with images of individuals that is an order of magnitude larger than existing relevant datasets and where rich semantic ground-truth annotations are readily available. Having established Stellar to promote cross-systems fine-grained comparisons further, we introduce a rigorous ensemble of specialized metrics that highlight and disentangle fundamental properties such systems should obey. Besides being intuitive, our new metrics correlate significantly more strongly with human judgment than currently used metrics on this task. Last but not least, drawing inspiration from the recent works of ELITE and SDXL, we derive a simple yet efficient, personalized text-to-image baseline that does not require test-time fine-tuning for each subject and which sets quantitatively and in human trials a new SoTA. For more information, please visit our project's website: https://stellar-gen-ai.github.io/.
Batch Model Consolidation: A Multi-Task Model Consolidation Framework
May 25, 2023



In Continual Learning (CL), a model is required to learn a stream of tasks sequentially without significant performance degradation on previously learned tasks. Current approaches fail for a long sequence of tasks from diverse domains and difficulties. Many of the existing CL approaches are difficult to apply in practice due to excessive memory cost or training time, or are tightly coupled to a single device. With the intuition derived from the widely applied mini-batch training, we propose Batch Model Consolidation ($\textbf{BMC}$) to support more realistic CL under conditions where multiple agents are exposed to a range of tasks. During a $\textit{regularization}$ phase, BMC trains multiple $\textit{expert models}$ in parallel on a set of disjoint tasks. Each expert maintains weight similarity to a $\textit{base model}$ through a $\textit{stability loss}$, and constructs a $\textit{buffer}$ from a fraction of the task's data. During the $\textit{consolidation}$ phase, we combine the learned knowledge on 'batches' of $\textit{expert models}$ using a $\textit{batched consolidation loss}$ in $\textit{memory}$ data that aggregates all buffers. We thoroughly evaluate each component of our method in an ablation study and demonstrate the effectiveness on standardized benchmark datasets Split-CIFAR-100, Tiny-ImageNet, and the Stream dataset composed of 71 image classification tasks from diverse domains and difficulties. Our method outperforms the next best CL approach by 70% and is the only approach that can maintain performance at the end of 71 tasks; Our benchmark can be accessed at https://github.com/fostiropoulos/stream_benchmark
Lightweight Learner for Shared Knowledge Lifelong Learning
May 24, 2023
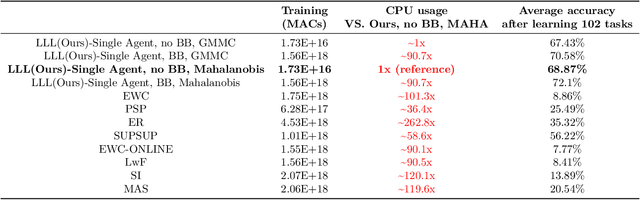

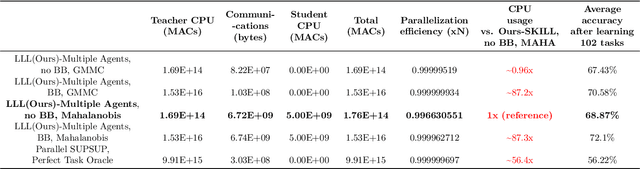
In Lifelong Learning (LL), agents continually learn as they encounter new conditions and tasks. Most current LL is limited to a single agent that learns tasks sequentially. Dedicated LL machinery is then deployed to mitigate the forgetting of old tasks as new tasks are learned. This is inherently slow. We propose a new Shared Knowledge Lifelong Learning (SKILL) challenge, which deploys a decentralized population of LL agents that each sequentially learn different tasks, with all agents operating independently and in parallel. After learning their respective tasks, agents share and consolidate their knowledge over a decentralized communication network, so that, in the end, all agents can master all tasks. We present one solution to SKILL which uses Lightweight Lifelong Learning (LLL) agents, where the goal is to facilitate efficient sharing by minimizing the fraction of the agent that is specialized for any given task. Each LLL agent thus consists of a common task-agnostic immutable part, where most parameters are, and individual task-specific modules that contain fewer parameters but are adapted to each task. Agents share their task-specific modules, plus summary information ("task anchors") representing their tasks in the common task-agnostic latent space of all agents. Receiving agents register each received task-specific module using the corresponding anchor. Thus, every agent improves its ability to solve new tasks each time new task-specific modules and anchors are received. On a new, very challenging SKILL-102 dataset with 102 image classification tasks (5,033 classes in total, 2,041,225 training, 243,464 validation, and 243,464 test images), we achieve much higher (and SOTA) accuracy over 8 LL baselines, while also achieving near perfect parallelization. Code and data can be found at https://github.com/gyhandy/Shared-Knowledge-Lifelong-Learning
Reproducibility Requires Consolidated Artifacts
May 21, 2023Machine learning is facing a 'reproducibility crisis' where a significant number of works report failures when attempting to reproduce previously published results. We evaluate the sources of reproducibility failures using a meta-analysis of 142 replication studies from ReScience C and 204 code repositories. We find that missing experiment details such as hyperparameters are potential causes of unreproducibility. We experimentally show the bias of different hyperparameter selection strategies and conclude that consolidated artifacts with a unified framework can help support reproducibility.
Supervised Contrastive Prototype Learning: Augmentation Free Robust Neural Network
Nov 26, 2022Transformations in the input space of Deep Neural Networks (DNN) lead to unintended changes in the feature space. Almost perceptually identical inputs, such as adversarial examples, can have significantly distant feature representations. On the contrary, Out-of-Distribution (OOD) samples can have highly similar feature representations to training set samples. Our theoretical analysis for DNNs trained with a categorical classification head suggests that the inflexible logit space restricted by the classification problem size is one of the root causes for the lack of $\textit{robustness}$. Our second observation is that DNNs over-fit to the training augmentation technique and do not learn $\textit{nuance invariant}$ representations. Inspired by the recent success of prototypical and contrastive learning frameworks for both improving robustness and learning nuance invariant representations, we propose a training framework, $\textbf{Supervised Contrastive Prototype Learning}$ (SCPL). We use N-pair contrastive loss with prototypes of the same and opposite classes and replace a categorical classification head with a $\textbf{Prototype Classification Head}$ (PCH). Our approach is $\textit{sample efficient}$, does not require $\textit{sample mining}$, can be implemented on any existing DNN without modification to their architecture, and combined with other training augmentation techniques. We empirically evaluate the $\textbf{clean}$ robustness of our method on out-of-distribution and adversarial samples. Our framework outperforms other state-of-the-art contrastive and prototype learning approaches in $\textit{robustness}$.
Implicit Feature Decoupling with Depthwise Quantization
Mar 29, 2022

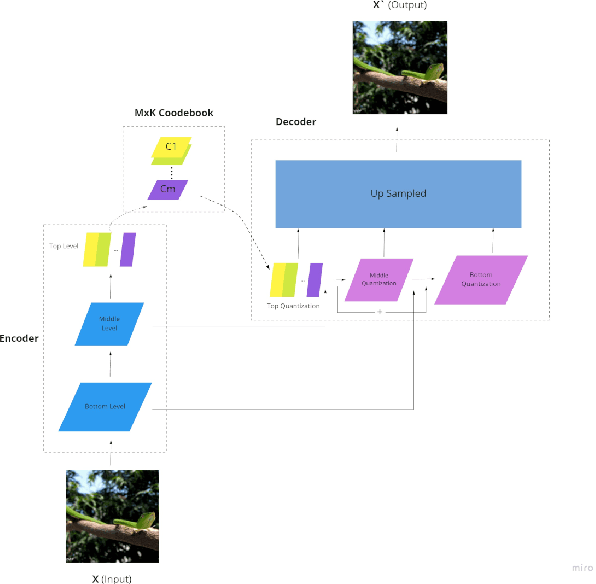
Quantization has been applied to multiple domains in Deep Neural Networks (DNNs). We propose Depthwise Quantization (DQ) where $\textit{quantization}$ is applied to a decomposed sub-tensor along the $\textit{feature axis}$ of weak statistical dependence. The feature decomposition leads to an exponential increase in $\textit{representation capacity}$ with a linear increase in memory and parameter cost. In addition, DQ can be directly applied to existing encoder-decoder frameworks without modification of the DNN architecture. We use DQ in the context of Hierarchical Auto-Encoder and train end-to-end on an image feature representation. We provide an analysis on cross-correlation between spatial and channel features and we propose a decomposition of the image feature representation along the channel axis. The improved performance of the depthwise operator is due to the increased representation capacity from implicit feature decoupling. We evaluate DQ on the likelihood estimation task, where it outperforms the previous state-of-the-art on CIFAR-10, ImageNet-32 and ImageNet-64. We progressively train with increasing image size a single hierarchical model that uses 69% less parameters and has a faster convergence than the previous works.
Graph Conditioned Sparse-Attention for Improved Source Code Understanding
Dec 03, 2021
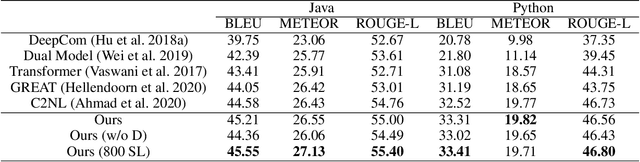

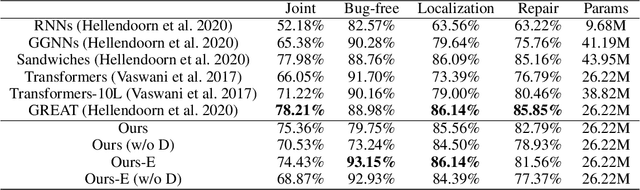
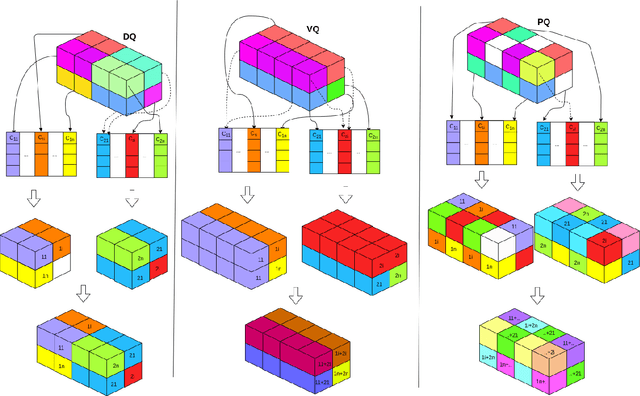
Transformer architectures have been successfully used in learning source code representations. The fusion between a graph representation like Abstract Syntax Tree (AST) and a source code sequence makes the use of current approaches computationally intractable for large input sequence lengths. Source code can have long-range dependencies that require larger sequence lengths to model effectively. Current approaches have a quadratic growth in computational and memory costs with respect to the sequence length. Using such models in practical scenarios is difficult. In this work, we propose the conditioning of a source code snippet with its graph modality by using the graph adjacency matrix as an attention mask for a sparse self-attention mechanism and the use of a graph diffusion mechanism to model longer-range token dependencies. Our model reaches state-of-the-art results in BLEU, METEOR, and ROUGE-L metrics for the code summarization task and near state-of-the-art accuracy in the variable misuse task. The memory use and inference time of our model have linear growth with respect to the input sequence length as compared to the quadratic growth of previous works.
GN-Transformer: Fusing Sequence and Graph Representation for Improved Code Summarization
Nov 17, 2021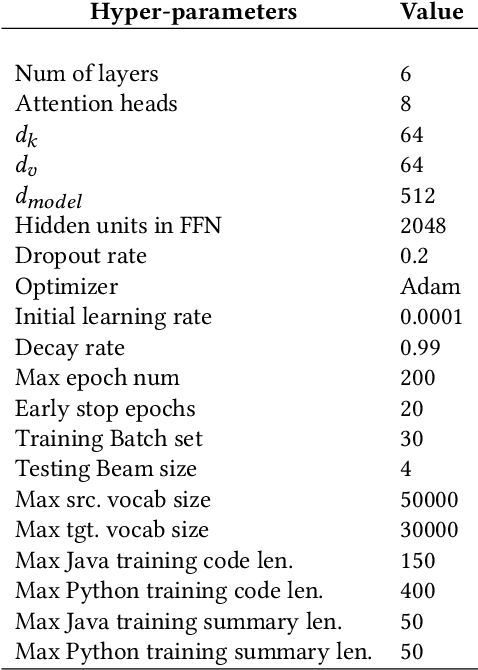

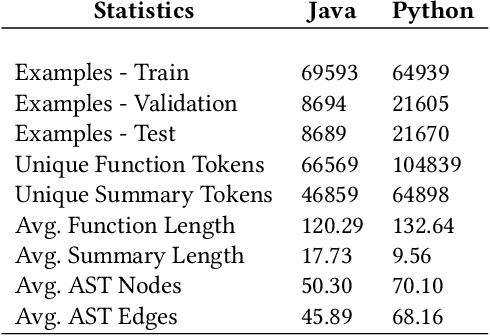

As opposed to natural languages, source code understanding is influenced by grammatical relationships between tokens regardless of their identifier name. Graph representations of source code such as Abstract Syntax Tree (AST) can capture relationships between tokens that are not obvious from the source code. We propose a novel method, GN-Transformer to learn end-to-end on a fused sequence and graph modality we call Syntax-Code-Graph (SCG). GN-Transformer expands on Graph Networks (GN) framework using a self-attention mechanism. SCG is the result of the early fusion between a source code snippet and the AST representation. We perform experiments on the structure of SCG, an ablation study on the model design, and the hyper-parameters to conclude that the performance advantage is from the fused representation. The proposed methods achieve state-of-the-art performance in two code summarization datasets and across three automatic code summarization metrics (BLEU, METEOR, ROUGE-L). We further evaluate the human perceived quality of our model and previous work with an expert-user study. Our model outperforms the state-of-the-art in human perceived quality and accuracy.
Learning Hyperbolic Representations of Topological Features
Mar 16, 2021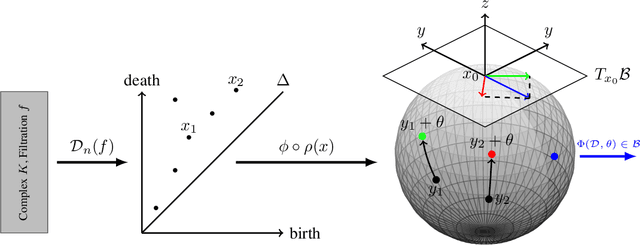
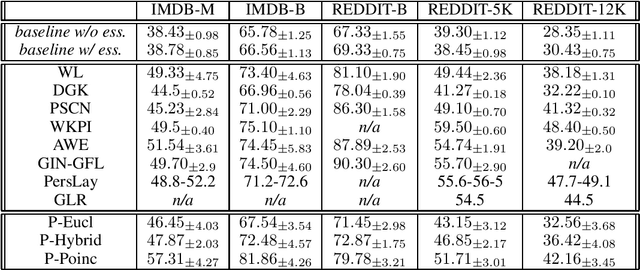
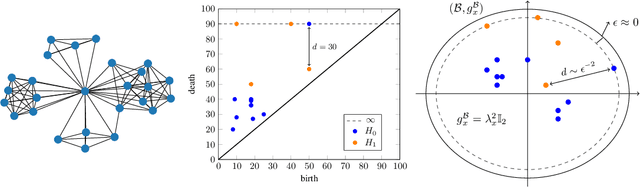
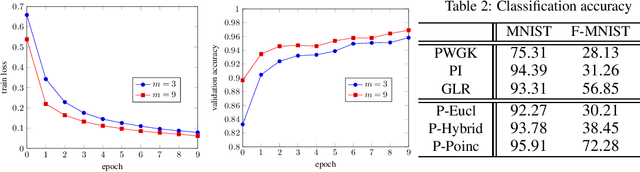
Learning task-specific representations of persistence diagrams is an important problem in topological data analysis and machine learning. However, current state of the art methods are restricted in terms of their expressivity as they are focused on Euclidean representations. Persistence diagrams often contain features of infinite persistence (i.e., essential features) and Euclidean spaces shrink their importance relative to non-essential features because they cannot assign infinite distance to finite points. To deal with this issue, we propose a method to learn representations of persistence diagrams on hyperbolic spaces, more specifically on the Poincare ball. By representing features of infinite persistence infinitesimally close to the boundary of the ball, their distance to non-essential features approaches infinity, thereby their relative importance is preserved. This is achieved without utilizing extremely high values for the learnable parameters, thus the representation can be fed into downstream optimization methods and trained efficiently in an end-to-end fashion. We present experimental results on graph and image classification tasks and show that the performance of our method is on par with or exceeds the performance of other state of the art methods.
Depthwise Discrete Representation Learning
Apr 11, 2020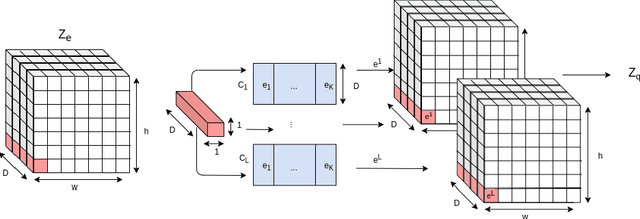
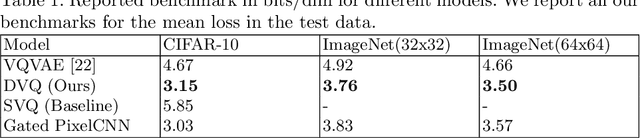
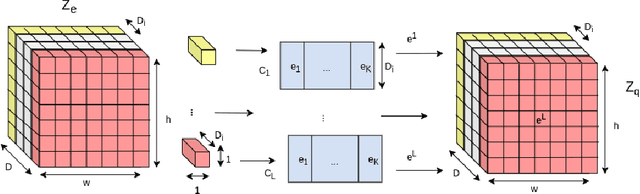
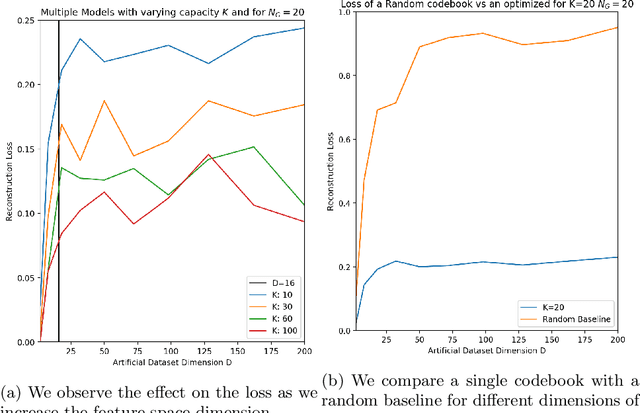
Recent advancements in learning Discrete Representations as opposed to continuous ones have led to state of art results in tasks that involve Language, Audio and Vision. Some latent factors such as words, phonemes and shapes are better represented by discrete latent variables as opposed to continuous. Vector Quantized Variational Autoencoders (VQVAE) have produced remarkable results in multiple domains. VQVAE learns a prior distribution $z_e$ along with its mapping to a discrete number of $K$ vectors (Vector Quantization). We propose applying VQ along the feature axis. We hypothesize that by doing so, we are learning a mapping between the codebook vectors and the marginal distribution of the prior feature space. Our approach leads to 33\% improvement as compared to prevous discrete models and has similar performance to state of the art auto-regressive models (e.g. PixelSNAIL). We evaluate our approach on a static prior using an artificial toy dataset (blobs). We further evaluate our approach on benchmarks for CIFAR-10 and ImageNet.