 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalytica: Soft Propositional Reasoning for Robust and Scalable LLM-Driven Analysis
Apr 24, 2026Large language model (LLM) agents are increasingly tasked with complex real-world analysis (e.g., in financial forecasting, scientific discovery), yet their reasoning suffers from stochastic instability and lacks a verifiable, compositional structure. To address this, we introduce Analytica, a novel agent architecture built on the principle of Soft Propositional Reasoning (SPR). SPR reframes complex analysis as a structured process of estimating the soft truth values of different outcome propositions, allowing us to formally model and minimize the estimation error in terms of its bias and variance. Analytica operationalizes this through a parallel, divide-and-conquer framework that systematically reduces both sources of error. To reduce bias, problems are first decomposed into a tree of subpropositions, and tool-equipped LLM grounder agents are employed, including a novel Jupyter Notebook agent for data-driven analysis, that help to validate and score facts. To reduce variance, Analytica recursively synthesizes these grounded leaves using robust linear models that average out stochastic noise with superior efficiency, scalability, and enable interactive "what-if" scenario analysis. Our theoretical and empirical results on economic, financial, and political forecasting tasks show that Analytica improves 15.84% accuracy on average over diverse base models, achieving 71.06% accuracy with the lowest variance of 6.02% when working with a Deep Research grounder. Our Jupyter Notebook grounder shows strong cost-effectiveness that achieves a close 70.11% accuracy with 90.35% less cost and 52.85% less time. Analytica also exhibits highly noise-resilient and stable performance growth as the analysis depth increases, with a near-linear time complexity, as well as good adaptivity to open-weight LLMs and scientific domains.
AAPM: Large Language Model Agent-based Asset Pricing Models
Sep 25, 2024



In this study, we propose a novel asset pricing approach, LLM Agent-based Asset Pricing Models (AAPM), which fuses qualitative discretionary investment analysis from LLM agents and quantitative manual financial economic factors to predict excess asset returns. The experimental results show that our approach outperforms machine learning-based asset pricing baselines in portfolio optimization and asset pricing errors. Specifically, the Sharpe ratio and average $|\alpha|$ for anomaly portfolios improved significantly by 9.6\% and 10.8\% respectively. In addition, we conducted extensive ablation studies on our model and analysis of the data to reveal further insights into the proposed method.
On the Transition from Neural Representation to Symbolic Knowledge
Aug 03, 2023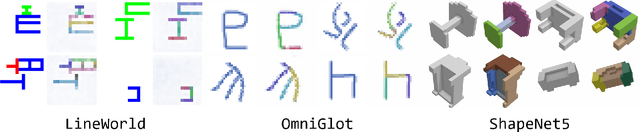
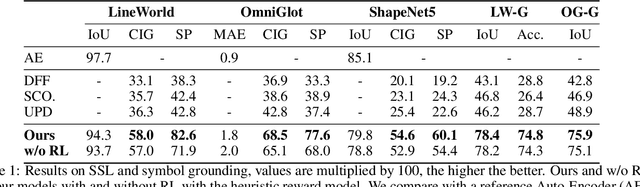
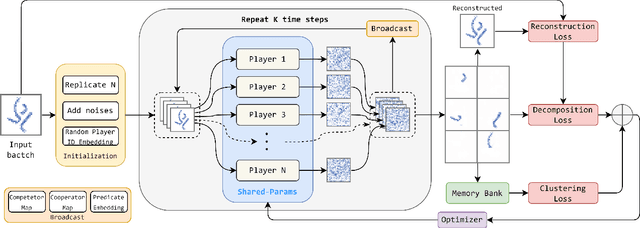

Bridging the huge disparity between neural and symbolic representation can potentially enable the incorporation of symbolic thinking into neural networks from essence. Motivated by how human gradually builds complex symbolic representation from the prototype symbols that are learned through perception and environmental interactions. We propose a Neural-Symbolic Transitional Dictionary Learning (TDL) framework that employs an EM algorithm to learn a transitional representation of data that compresses high-dimension information of visual parts of an input into a set of tensors as neural variables and discover the implicit predicate structure in a self-supervised way. We implement the framework with a diffusion model by regarding the decomposition of input as a cooperative game, then learn predicates by prototype clustering. We additionally use RL enabled by the Markovian of diffusion models to further tune the learned prototypes by incorporating subjective factors. Extensive experiments on 3 abstract compositional visual objects datasets that require the model to segment parts without any visual features like texture, color, or shadows apart from shape and 3 neural/symbolic downstream tasks demonstrate the learned representation enables interpretable decomposition of visual input and smooth adaption to downstream tasks which are not available by existing methods.
Graph Conditioned Sparse-Attention for Improved Source Code Understanding
Dec 03, 2021
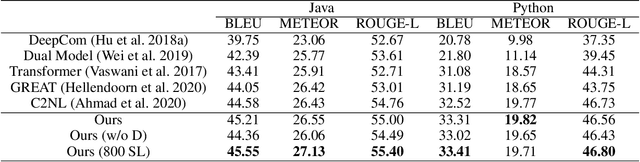

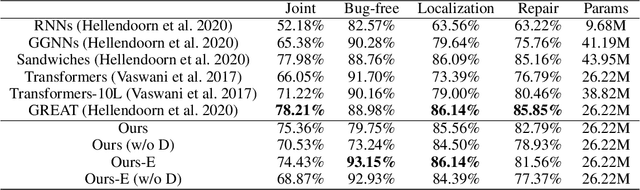
Transformer architectures have been successfully used in learning source code representations. The fusion between a graph representation like Abstract Syntax Tree (AST) and a source code sequence makes the use of current approaches computationally intractable for large input sequence lengths. Source code can have long-range dependencies that require larger sequence lengths to model effectively. Current approaches have a quadratic growth in computational and memory costs with respect to the sequence length. Using such models in practical scenarios is difficult. In this work, we propose the conditioning of a source code snippet with its graph modality by using the graph adjacency matrix as an attention mask for a sparse self-attention mechanism and the use of a graph diffusion mechanism to model longer-range token dependencies. Our model reaches state-of-the-art results in BLEU, METEOR, and ROUGE-L metrics for the code summarization task and near state-of-the-art accuracy in the variable misuse task. The memory use and inference time of our model have linear growth with respect to the input sequence length as compared to the quadratic growth of previous works.
GN-Transformer: Fusing Sequence and Graph Representation for Improved Code Summarization
Nov 17, 2021


As opposed to natural languages, source code understanding is influenced by grammatical relationships between tokens regardless of their identifier name. Graph representations of source code such as Abstract Syntax Tree (AST) can capture relationships between tokens that are not obvious from the source code. We propose a novel method, GN-Transformer to learn end-to-end on a fused sequence and graph modality we call Syntax-Code-Graph (SCG). GN-Transformer expands on Graph Networks (GN) framework using a self-attention mechanism. SCG is the result of the early fusion between a source code snippet and the AST representation. We perform experiments on the structure of SCG, an ablation study on the model design, and the hyper-parameters to conclude that the performance advantage is from the fused representation. The proposed methods achieve state-of-the-art performance in two code summarization datasets and across three automatic code summarization metrics (BLEU, METEOR, ROUGE-L). We further evaluate the human perceived quality of our model and previous work with an expert-user study. Our model outperforms the state-of-the-art in human perceived quality and accuracy.