 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Conditioned Sparse-Attention for Improved Source Code Understanding
Paper and Code

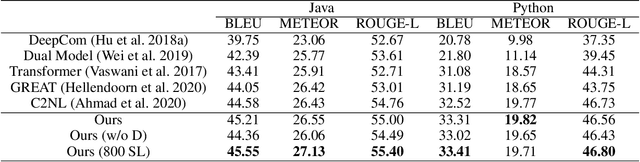

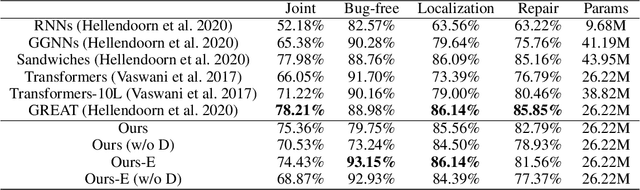
Transformer architectures have been successfully used in learning source code representations. The fusion between a graph representation like Abstract Syntax Tree (AST) and a source code sequence makes the use of current approaches computationally intractable for large input sequence lengths. Source code can have long-range dependencies that require larger sequence lengths to model effectively. Current approaches have a quadratic growth in computational and memory costs with respect to the sequence length. Using such models in practical scenarios is difficult. In this work, we propose the conditioning of a source code snippet with its graph modality by using the graph adjacency matrix as an attention mask for a sparse self-attention mechanism and the use of a graph diffusion mechanism to model longer-range token dependencies. Our model reaches state-of-the-art results in BLEU, METEOR, and ROUGE-L metrics for the code summarization task and near state-of-the-art accuracy in the variable misuse task. The memory use and inference time of our model have linear growth with respect to the input sequence length as compared to the quadratic growth of previous works.