 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Feature Decoupling with Depthwise Quantization
Mar 29, 2022

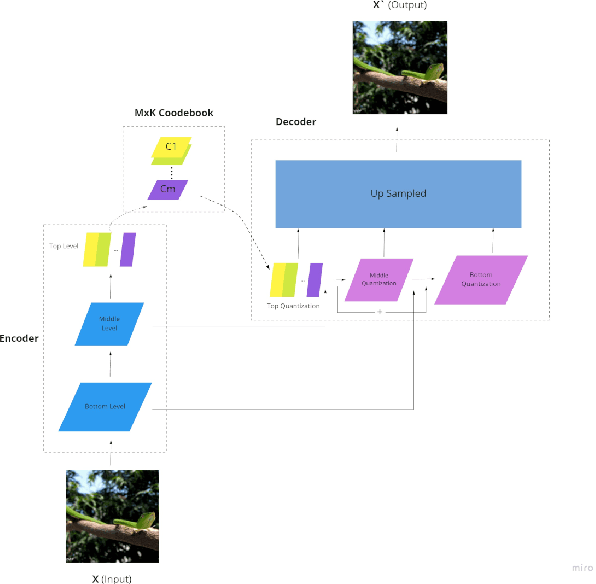
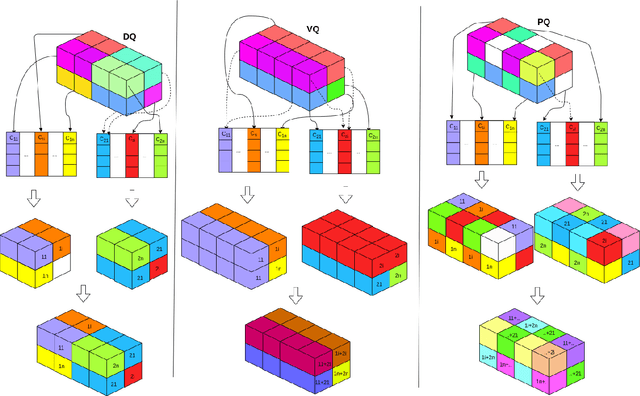
Quantization has been applied to multiple domains in Deep Neural Networks (DNNs). We propose Depthwise Quantization (DQ) where $\textit{quantization}$ is applied to a decomposed sub-tensor along the $\textit{feature axis}$ of weak statistical dependence. The feature decomposition leads to an exponential increase in $\textit{representation capacity}$ with a linear increase in memory and parameter cost. In addition, DQ can be directly applied to existing encoder-decoder frameworks without modification of the DNN architecture. We use DQ in the context of Hierarchical Auto-Encoder and train end-to-end on an image feature representation. We provide an analysis on cross-correlation between spatial and channel features and we propose a decomposition of the image feature representation along the channel axis. The improved performance of the depthwise operator is due to the increased representation capacity from implicit feature decoupling. We evaluate DQ on the likelihood estimation task, where it outperforms the previous state-of-the-art on CIFAR-10, ImageNet-32 and ImageNet-64. We progressively train with increasing image size a single hierarchical model that uses 69% less parameters and has a faster convergence than the previous works.
Graph Conditioned Sparse-Attention for Improved Source Code Understanding
Dec 03, 2021
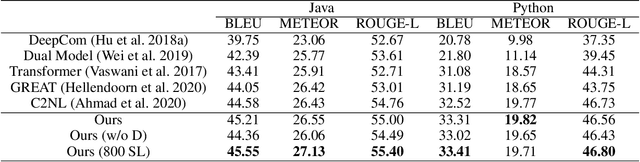

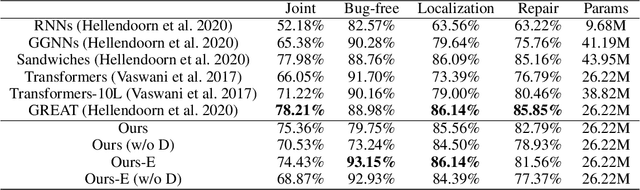
Transformer architectures have been successfully used in learning source code representations. The fusion between a graph representation like Abstract Syntax Tree (AST) and a source code sequence makes the use of current approaches computationally intractable for large input sequence lengths. Source code can have long-range dependencies that require larger sequence lengths to model effectively. Current approaches have a quadratic growth in computational and memory costs with respect to the sequence length. Using such models in practical scenarios is difficult. In this work, we propose the conditioning of a source code snippet with its graph modality by using the graph adjacency matrix as an attention mask for a sparse self-attention mechanism and the use of a graph diffusion mechanism to model longer-range token dependencies. Our model reaches state-of-the-art results in BLEU, METEOR, and ROUGE-L metrics for the code summarization task and near state-of-the-art accuracy in the variable misuse task. The memory use and inference time of our model have linear growth with respect to the input sequence length as compared to the quadratic growth of previous works.
GN-Transformer: Fusing Sequence and Graph Representation for Improved Code Summarization
Nov 17, 2021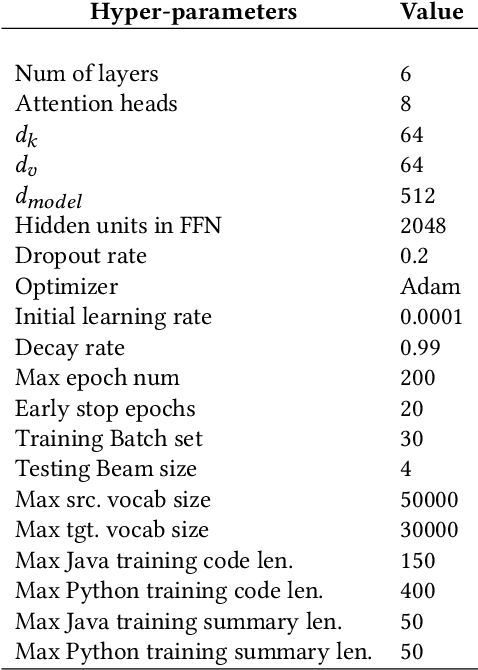

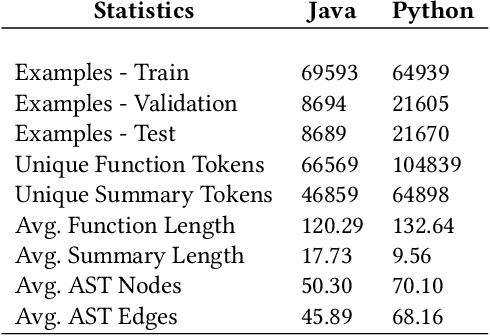

As opposed to natural languages, source code understanding is influenced by grammatical relationships between tokens regardless of their identifier name. Graph representations of source code such as Abstract Syntax Tree (AST) can capture relationships between tokens that are not obvious from the source code. We propose a novel method, GN-Transformer to learn end-to-end on a fused sequence and graph modality we call Syntax-Code-Graph (SCG). GN-Transformer expands on Graph Networks (GN) framework using a self-attention mechanism. SCG is the result of the early fusion between a source code snippet and the AST representation. We perform experiments on the structure of SCG, an ablation study on the model design, and the hyper-parameters to conclude that the performance advantage is from the fused representation. The proposed methods achieve state-of-the-art performance in two code summarization datasets and across three automatic code summarization metrics (BLEU, METEOR, ROUGE-L). We further evaluate the human perceived quality of our model and previous work with an expert-user study. Our model outperforms the state-of-the-art in human perceived quality and accuracy.