 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTS-OOD: Evaluating Time-Series Out-of-Distribution Detection and Prospective Directions for Progress
Feb 21, 2025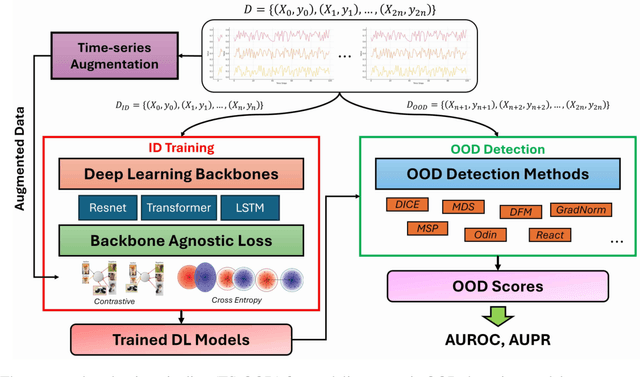
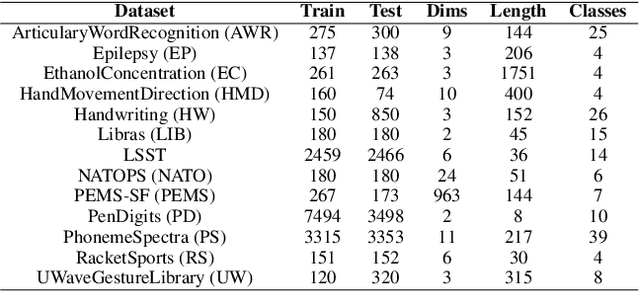
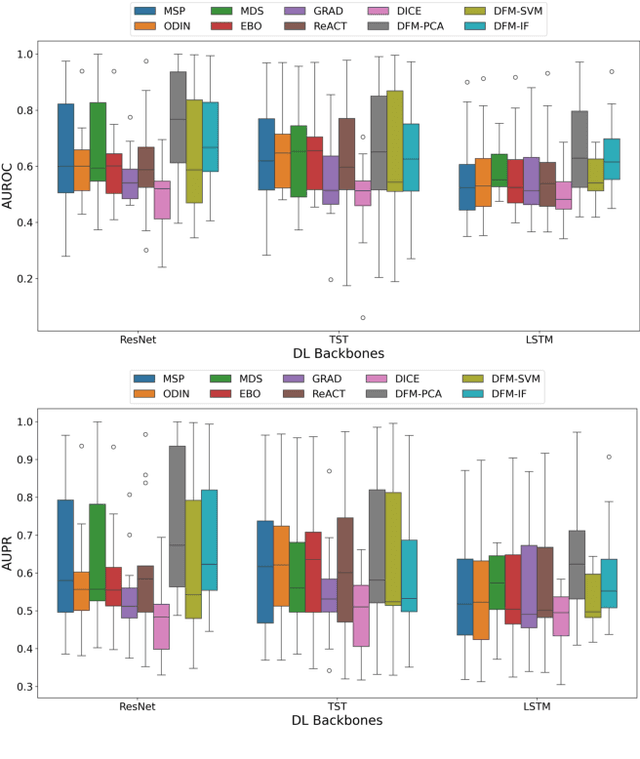
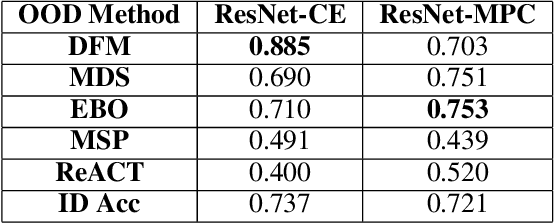
Detecting out-of-distribution (OOD) data is a fundamental challenge in the deployment of machine learning models. From a security standpoint, this is particularly important because OOD test data can result in misleadingly confident yet erroneous predictions, which undermine the reliability of the deployed model. Although numerous models for OOD detection have been developed in computer vision and language, their adaptability to the time-series data domain remains limited and under-explored. Yet, time-series data is ubiquitous across manufacturing and security applications for which OOD is essential. This paper seeks to address this research gap by conducting a comprehensive analysis of modality-agnostic OOD detection algorithms. We evaluate over several multivariate time-series datasets, deep learning architectures, time-series specific data augmentations, and loss functions. Our results demonstrate that: 1) the majority of state-of-the-art OOD methods exhibit limited performance on time-series data, and 2) OOD methods based on deep feature modeling may offer greater advantages for time-series OOD detection, highlighting a promising direction for future time-series OOD detection algorithm development.
Lightweight Learner for Shared Knowledge Lifelong Learning
May 24, 2023
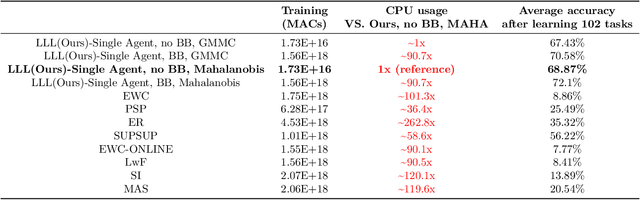

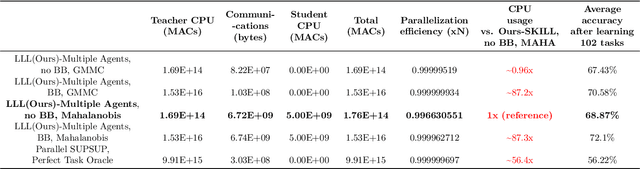
In Lifelong Learning (LL), agents continually learn as they encounter new conditions and tasks. Most current LL is limited to a single agent that learns tasks sequentially. Dedicated LL machinery is then deployed to mitigate the forgetting of old tasks as new tasks are learned. This is inherently slow. We propose a new Shared Knowledge Lifelong Learning (SKILL) challenge, which deploys a decentralized population of LL agents that each sequentially learn different tasks, with all agents operating independently and in parallel. After learning their respective tasks, agents share and consolidate their knowledge over a decentralized communication network, so that, in the end, all agents can master all tasks. We present one solution to SKILL which uses Lightweight Lifelong Learning (LLL) agents, where the goal is to facilitate efficient sharing by minimizing the fraction of the agent that is specialized for any given task. Each LLL agent thus consists of a common task-agnostic immutable part, where most parameters are, and individual task-specific modules that contain fewer parameters but are adapted to each task. Agents share their task-specific modules, plus summary information ("task anchors") representing their tasks in the common task-agnostic latent space of all agents. Receiving agents register each received task-specific module using the corresponding anchor. Thus, every agent improves its ability to solve new tasks each time new task-specific modules and anchors are received. On a new, very challenging SKILL-102 dataset with 102 image classification tasks (5,033 classes in total, 2,041,225 training, 243,464 validation, and 243,464 test images), we achieve much higher (and SOTA) accuracy over 8 LL baselines, while also achieving near perfect parallelization. Code and data can be found at https://github.com/gyhandy/Shared-Knowledge-Lifelong-Learning
What can we learn from misclassified ImageNet images?
Jan 20, 2022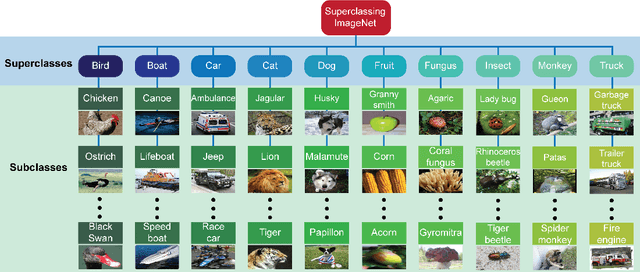
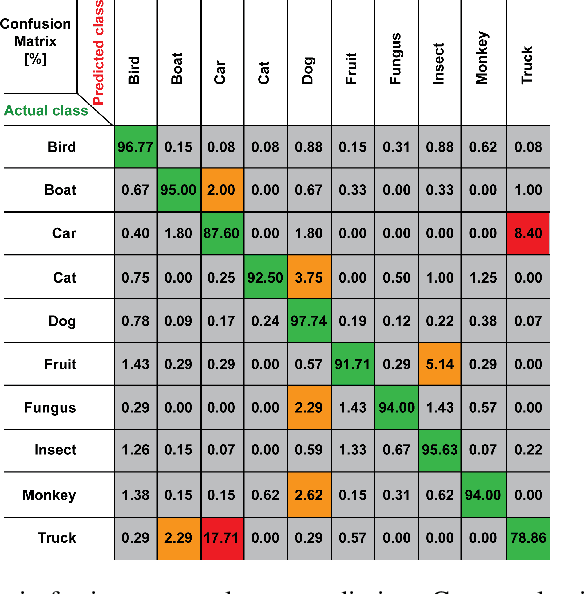
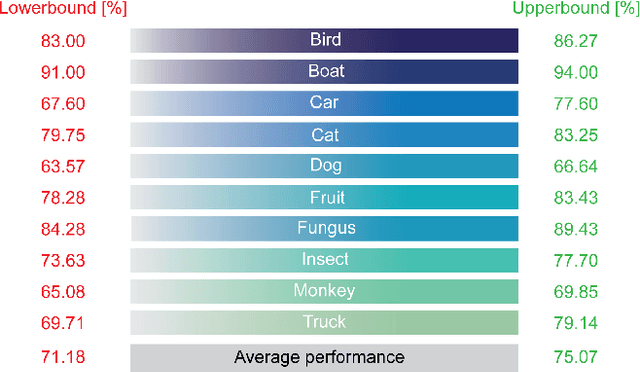
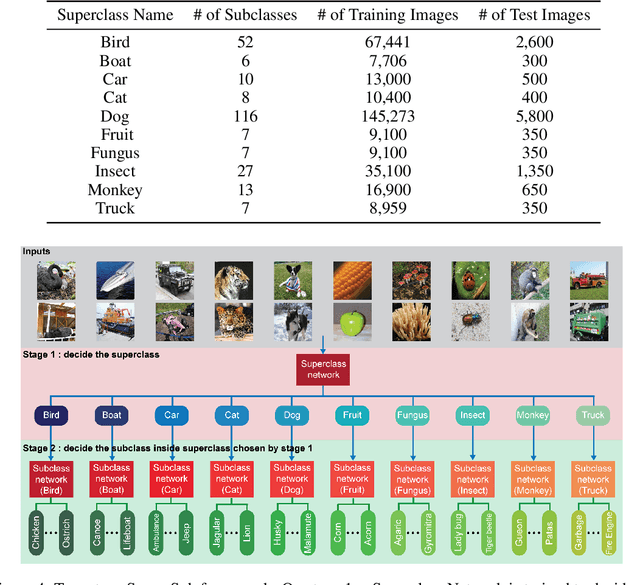
Understanding the patterns of misclassified ImageNet images is particularly important, as it could guide us to design deep neural networks (DNN) that generalize better. However, the richness of ImageNet imposes difficulties for researchers to visually find any useful patterns of misclassification. Here, to help find these patterns, we propose "Superclassing ImageNet dataset". It is a subset of ImageNet which consists of 10 superclasses, each containing 7-116 related subclasses (e.g., 52 bird types, 116 dog types). By training neural networks on this dataset, we found that: (i) Misclassifications are rarely across superclasses, but mainly among subclasses within a superclass. (ii) Ensemble networks trained each only on subclasses of a given superclass perform better than the same network trained on all subclasses of all superclasses. Hence, we propose a two-stage Super-Sub framework, and demonstrate that: (i) The framework improves overall classification performance by 3.3%, by first inferring a superclass using a generalist superclass-level network, and then using a specialized network for final subclass-level classification. (ii) Although the total parameter storage cost increases to a factor N+1 for N superclasses compared to using a single network, with finetuning, delta and quantization aware training techniques this can be reduced to 0.2N+1. Another advantage of this efficient implementation is that the memory cost on the GPU during inference is equivalent to using only one network. The reason is we initiate each subclass-level network through addition of small parameter variations (deltas) to the superclass-level network. (iii) Finally, our framework promises to be more scalable and generalizable than the common alternative of simply scaling up a vanilla network in size, since very large networks often suffer from overfitting and gradient vanishing.