 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValue Explicit Pretraining for Goal-Based Transfer Learning
Dec 19, 2023



We propose a method that allows for learning task-agnostic representations based on value function estimates from a sequence of observations where the last frame corresponds to a goal. These representations would learn to relate states across different tasks, based on the temporal distance to the goal state, irrespective of the appearance changes and dynamics. This method could be used to transfer learnt policies/skills to unseen related tasks.
Evaluating Pretrained models for Deployable Lifelong Learning
Nov 22, 2023We create a novel benchmark for evaluating a Deployable Lifelong Learning system for Visual Reinforcement Learning (RL) that is pretrained on a curated dataset, and propose a novel Scalable Lifelong Learning system capable of retaining knowledge from the previously learnt RL tasks. Our benchmark measures the efficacy of a deployable Lifelong Learning system that is evaluated on scalability, performance and resource utilization. Our proposed system, once pretrained on the dataset, can be deployed to perform continual learning on unseen tasks. Our proposed method consists of a Few Shot Class Incremental Learning (FSCIL) based task-mapper and an encoder/backbone trained entirely using the pretrain dataset. The policy parameters corresponding to the recognized task are then loaded to perform the task. We show that this system can be scaled to incorporate a large number of tasks due to the small memory footprint and fewer computational resources. We perform experiments on our DeLL (Deployment for Lifelong Learning) benchmark on the Atari games to determine the efficacy of the system.
World Model Based Sim2Real Transfer for Visual Navigation
Oct 28, 2023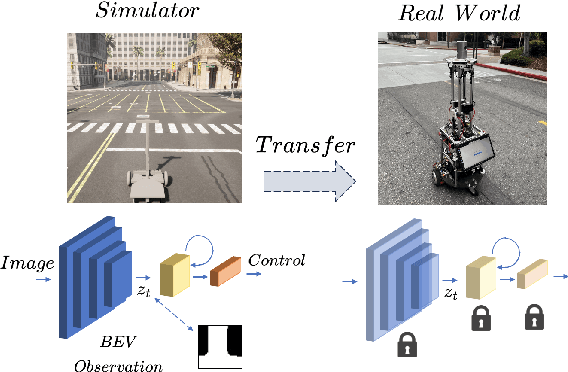
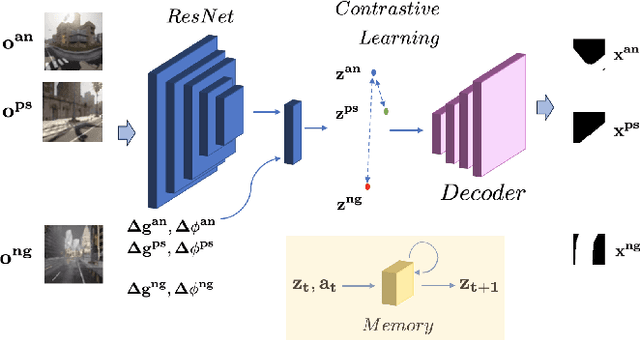
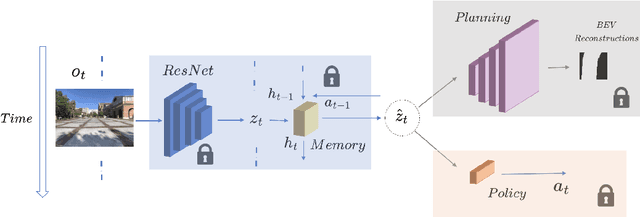
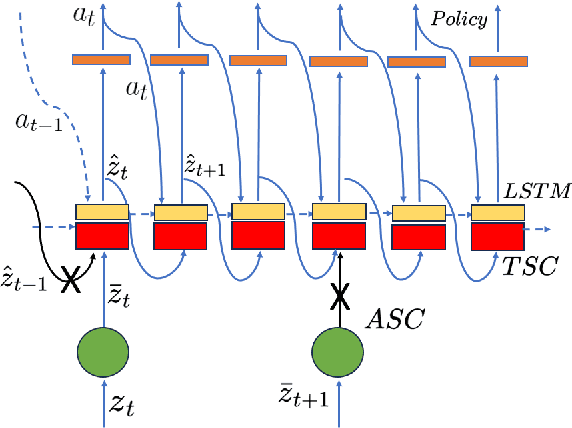
Sim2Real transfer has gained popularity because it helps transfer from inexpensive simulators to real world. This paper presents a novel system that fuses components in a traditional \textit{World Model} into a robust system, trained entirely within a simulator, that \textit{Zero-Shot} transfers to the real world. To facilitate transfer, we use an intermediary representation that are based on \textit{Bird's Eye View (BEV)} images. Thus, our robot learns to navigate in a simulator by first learning to translate from complex \textit{First-Person View (FPV)} based RGB images to BEV representations, then learning to navigate using those representations. Later, when tested in the real world, the robot uses the perception model that translates FPV-based RGB images to embeddings that are used by the downstream policy. The incorporation of state-checking modules using \textit{Anchor images} and \textit{Mixture Density LSTM} not only interpolates uncertain and missing observations but also enhances the robustness of the model when exposed to the real-world environment. We trained the model using data collected using a \textit{Differential drive} robot in the CARLA simulator. Our methodology's effectiveness is shown through the deployment of trained models onto a \textit{Real world Differential drive} robot. Lastly we release a comprehensive codebase, dataset and models for training and deployment that are available to the public.
Lightweight Learner for Shared Knowledge Lifelong Learning
May 24, 2023
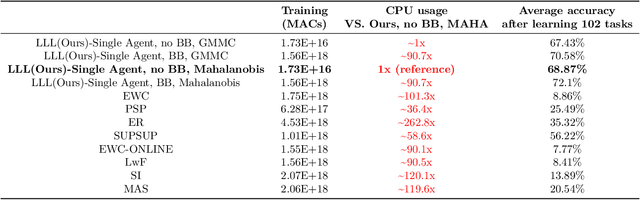

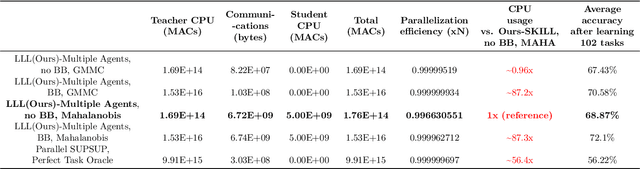
In Lifelong Learning (LL), agents continually learn as they encounter new conditions and tasks. Most current LL is limited to a single agent that learns tasks sequentially. Dedicated LL machinery is then deployed to mitigate the forgetting of old tasks as new tasks are learned. This is inherently slow. We propose a new Shared Knowledge Lifelong Learning (SKILL) challenge, which deploys a decentralized population of LL agents that each sequentially learn different tasks, with all agents operating independently and in parallel. After learning their respective tasks, agents share and consolidate their knowledge over a decentralized communication network, so that, in the end, all agents can master all tasks. We present one solution to SKILL which uses Lightweight Lifelong Learning (LLL) agents, where the goal is to facilitate efficient sharing by minimizing the fraction of the agent that is specialized for any given task. Each LLL agent thus consists of a common task-agnostic immutable part, where most parameters are, and individual task-specific modules that contain fewer parameters but are adapted to each task. Agents share their task-specific modules, plus summary information ("task anchors") representing their tasks in the common task-agnostic latent space of all agents. Receiving agents register each received task-specific module using the corresponding anchor. Thus, every agent improves its ability to solve new tasks each time new task-specific modules and anchors are received. On a new, very challenging SKILL-102 dataset with 102 image classification tasks (5,033 classes in total, 2,041,225 training, 243,464 validation, and 243,464 test images), we achieve much higher (and SOTA) accuracy over 8 LL baselines, while also achieving near perfect parallelization. Code and data can be found at https://github.com/gyhandy/Shared-Knowledge-Lifelong-Learning
What can we learn from misclassified ImageNet images?
Jan 20, 2022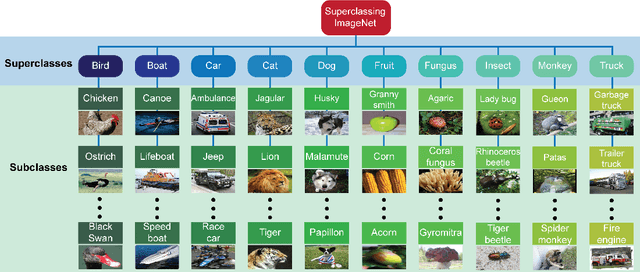
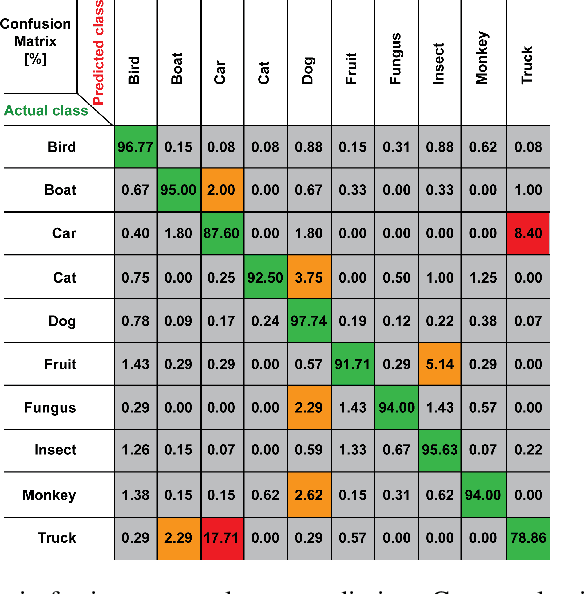
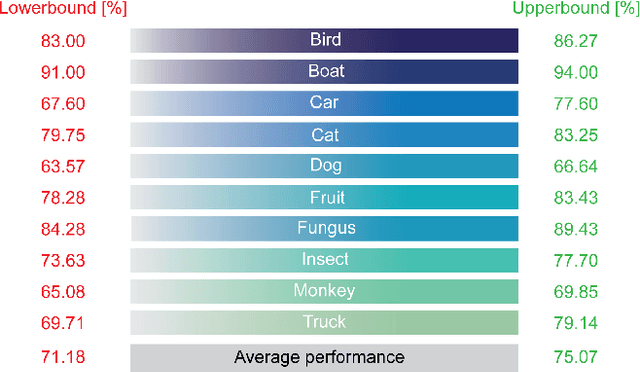
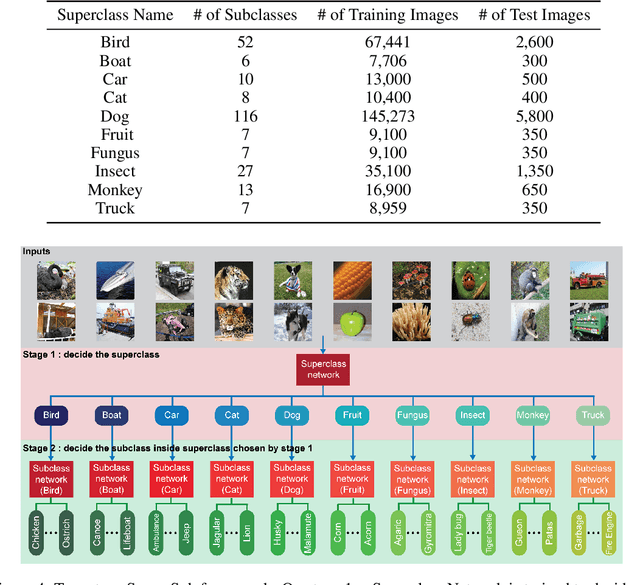
Understanding the patterns of misclassified ImageNet images is particularly important, as it could guide us to design deep neural networks (DNN) that generalize better. However, the richness of ImageNet imposes difficulties for researchers to visually find any useful patterns of misclassification. Here, to help find these patterns, we propose "Superclassing ImageNet dataset". It is a subset of ImageNet which consists of 10 superclasses, each containing 7-116 related subclasses (e.g., 52 bird types, 116 dog types). By training neural networks on this dataset, we found that: (i) Misclassifications are rarely across superclasses, but mainly among subclasses within a superclass. (ii) Ensemble networks trained each only on subclasses of a given superclass perform better than the same network trained on all subclasses of all superclasses. Hence, we propose a two-stage Super-Sub framework, and demonstrate that: (i) The framework improves overall classification performance by 3.3%, by first inferring a superclass using a generalist superclass-level network, and then using a specialized network for final subclass-level classification. (ii) Although the total parameter storage cost increases to a factor N+1 for N superclasses compared to using a single network, with finetuning, delta and quantization aware training techniques this can be reduced to 0.2N+1. Another advantage of this efficient implementation is that the memory cost on the GPU during inference is equivalent to using only one network. The reason is we initiate each subclass-level network through addition of small parameter variations (deltas) to the superclass-level network. (iii) Finally, our framework promises to be more scalable and generalizable than the common alternative of simply scaling up a vanilla network in size, since very large networks often suffer from overfitting and gradient vanishing.
Shaped Policy Search for Evolutionary Strategies using Waypoints
May 30, 2021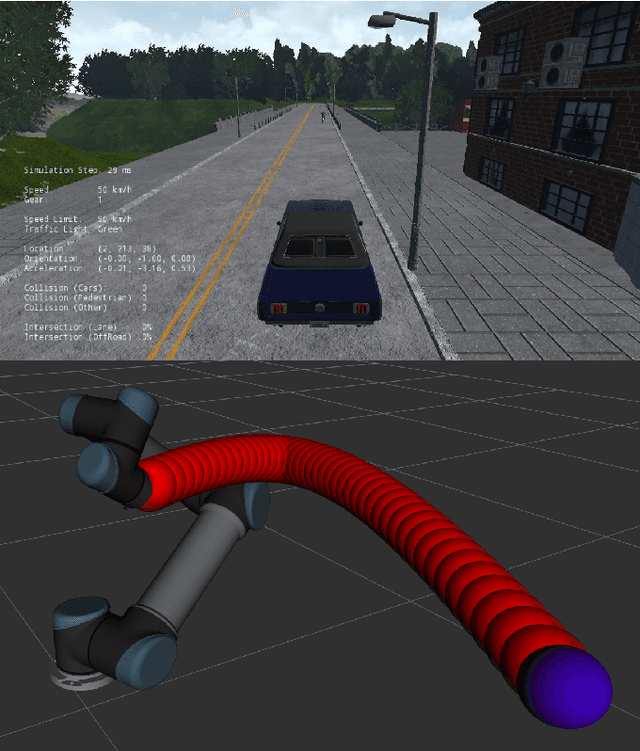


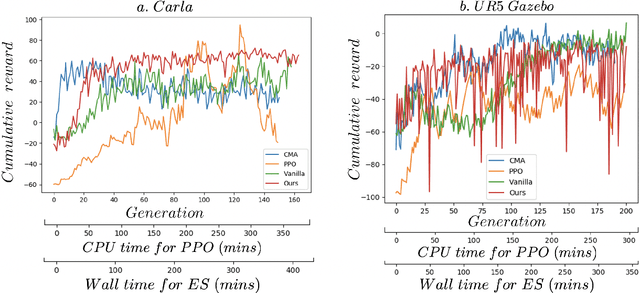
In this paper, we try to improve exploration in Blackbox methods, particularly Evolution strategies (ES), when applied to Reinforcement Learning (RL) problems where intermediate waypoints/subgoals are available. Since Evolutionary strategies are highly parallelizable, instead of extracting just a scalar cumulative reward, we use the state-action pairs from the trajectories obtained during rollouts/evaluations, to learn the dynamics of the agent. The learnt dynamics are then used in the optimization procedure to speed-up training. Lastly, we show how our proposed approach is universally applicable by presenting results from experiments conducted on Carla driving and UR5 robotic arm simulators.
Attentive Feature Reuse for Multi Task Meta learning
Jun 12, 2020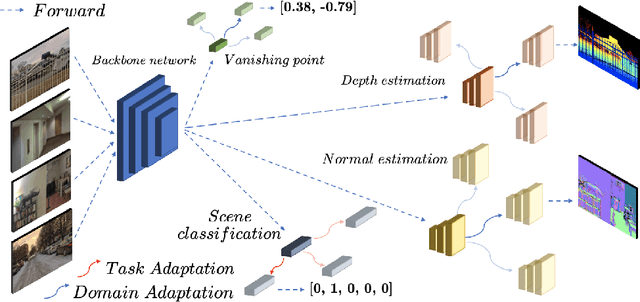
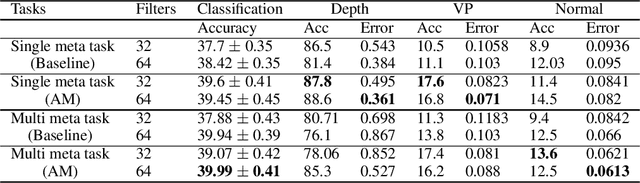
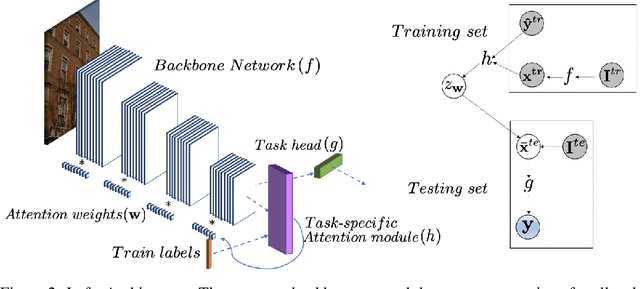

We develop new algorithms for simultaneous learning of multiple tasks (e.g., image classification, depth estimation), and for adapting to unseen task/domain distributions within those high-level tasks (e.g., different environments). First, we learn common representations underlying all tasks. We then propose an attention mechanism to dynamically specialize the network, at runtime, for each task. Our approach is based on weighting each feature map of the backbone network, based on its relevance to a particular task. To achieve this, we enable the attention module to learn task representations during training, which are used to obtain attention weights. Our method improves performance on new, previously unseen environments, and is 1.5x faster than standard existing meta learning methods using similar architectures. We highlight performance improvements for Multi-Task Meta Learning of 4 tasks (image classification, depth, vanishing point, and surface normal estimation), each over 10 to 25 test domains/environments, a result that could not be achieved with standard meta learning techniques like MAML.
Meta Adaptation using Importance Weighted Demonstrations
Nov 23, 2019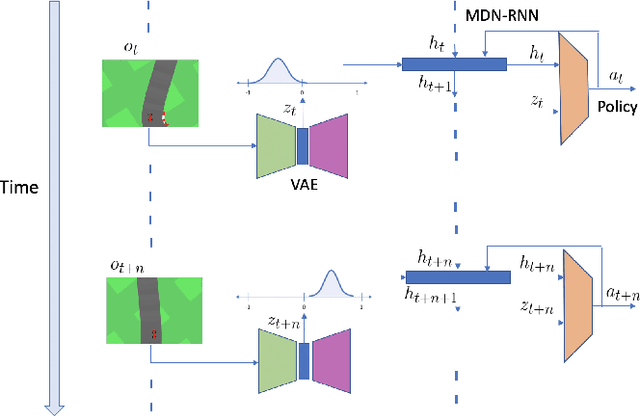


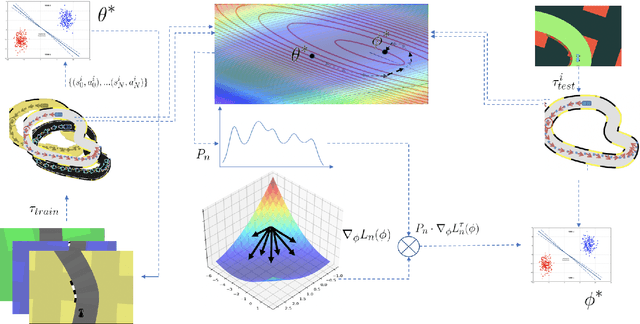
Imitation learning has gained immense popularity because of its high sample-efficiency. However, in real-world scenarios, where the trajectory distribution of most of the tasks dynamically shifts, model fitting on continuously aggregated data alone would be futile. In some cases, the distribution shifts, so much, that it is difficult for an agent to infer the new task. We propose a novel algorithm to generalize on any related task by leveraging prior knowledge on a set of specific tasks, which involves assigning importance weights to each past demonstration. We show experiments where the robot is trained from a diversity of environmental tasks and is also able to adapt to an unseen environment, using few-shot learning. We also developed a prototype robot system to test our approach on the task of visual navigation, and experimental results obtained were able to confirm these suppositions.