 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecGOAT: Graph Optimal Adaptive Transport for LLM-Enhanced Multimodal Recommendation with Dual Semantic Alignment
Jan 31, 2026Multimodal recommendation systems typically integrates user behavior with multimodal data from items, thereby capturing more accurate user preferences. Concurrently, with the rise of large models (LMs), multimodal recommendation is increasingly leveraging their strengths in semantic understanding and contextual reasoning. However, LM representations are inherently optimized for general semantic tasks, while recommendation models rely heavily on sparse user/item unique identity (ID) features. Existing works overlook the fundamental representational divergence between large models and recommendation systems, resulting in incompatible multimodal representations and suboptimal recommendation performance. To bridge this gap, we propose RecGOAT, a novel yet simple dual semantic alignment framework for LLM-enhanced multimodal recommendation, which offers theoretically guaranteed alignment capability. RecGOAT first employs graph attention networks to enrich collaborative semantics by modeling item-item, user-item, and user-user relationships, leveraging user/item LM representations and interaction history. Furthermore, we design a dual-granularity progressive multimodality-ID alignment framework, which achieves instance-level and distribution-level semantic alignment via cross-modal contrastive learning (CMCL) and optimal adaptive transport (OAT), respectively. Theoretically, we demonstrate that the unified representations derived from our alignment framework exhibit superior semantic consistency and comprehensiveness. Extensive experiments on three public benchmarks show that our RecGOAT achieves state-of-the-art performance, empirically validating our theoretical insights. Additionally, the deployment on a large-scale online advertising platform confirms the model's effectiveness and scalability in industrial recommendation scenarios. Code available at https://github.com/6lyc/RecGOAT-LLM4Rec.
PETAH: Parameter Efficient Task Adaptation for Hybrid Transformers in a resource-limited Context
Oct 23, 2024



Following their success in natural language processing (NLP), there has been a shift towards transformer models in computer vision. While transformers perform well and offer promising multi-tasking performance, due to their high compute requirements, many resource-constrained applications still rely on convolutional or hybrid models that combine the benefits of convolution and attention layers and achieve the best results in the sub 100M parameter range. Simultaneously, task adaptation techniques that allow for the use of one shared transformer backbone for multiple downstream tasks, resulting in great storage savings at negligible cost in performance, have not yet been adopted for hybrid transformers. In this work, we investigate how to achieve the best task-adaptation performance and introduce PETAH: Parameter Efficient Task Adaptation for Hybrid Transformers. We further combine PETAH adaptation with pruning to achieve highly performant and storage friendly models for multi-tasking. In our extensive evaluation on classification and other vision tasks, we demonstrate that our PETAH-adapted hybrid models outperform established task-adaptation techniques for ViTs while requiring fewer parameters and being more efficient on mobile hardware.
Clients Collaborate: Flexible Differentially Private Federated Learning with Guaranteed Improvement of Utility-Privacy Trade-off
Feb 10, 2024To defend against privacy leakage of user data, differential privacy is widely used in federated learning, but it is not free. The addition of noise randomly disrupts the semantic integrity of the model and this disturbance accumulates with increased communication rounds. In this paper, we introduce a novel federated learning framework with rigorous privacy guarantees, named FedCEO, designed to strike a trade-off between model utility and user privacy by letting clients ''Collaborate with Each Other''. Specifically, we perform efficient tensor low-rank proximal optimization on stacked local model parameters at the server, demonstrating its capability to flexibly truncate high-frequency components in spectral space. This implies that our FedCEO can effectively recover the disrupted semantic information by smoothing the global semantic space for different privacy settings and continuous training processes. Moreover, we improve the SOTA utility-privacy trade-off bound by an order of $\sqrt{d}$, where $d$ is the input dimension. We illustrate our theoretical results with experiments on representative image datasets. It observes significant performance improvements and strict privacy guarantees under different privacy settings.
Community-Aware Efficient Graph Contrastive Learning via Personalized Self-Training
Nov 18, 2023


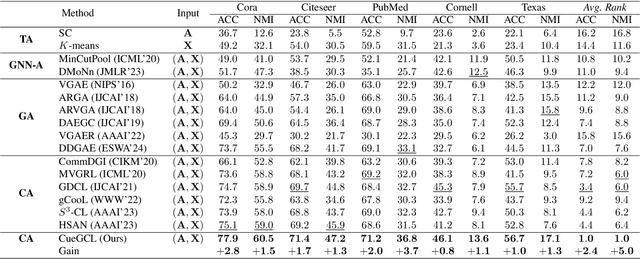
In recent years, graph contrastive learning (GCL) has emerged as one of the optimal solutions for various supervised tasks at the node level. However, for unsupervised and structure-related tasks such as community detection, current GCL algorithms face difficulties in acquiring the necessary community-level information, resulting in poor performance. In addition, general contrastive learning algorithms improve the performance of downstream tasks by increasing the number of negative samples, which leads to severe class collision and unfairness of community detection. To address above issues, we propose a novel Community-aware Efficient Graph Contrastive Learning Framework (CEGCL) to jointly learn community partition and node representations in an end-to-end manner. Specifically, we first design a personalized self-training (PeST) strategy for unsupervised scenarios, which enables our model to capture precise community-level personalized information in a graph. With the benefit of the PeST, we alleviate class collision and unfairness without sacrificing the overall model performance. Furthermore, the aligned graph clustering (AlGC) is employed to obtain the community partition. In this module, we align the clustering space of our downstream task with that in PeST to achieve more consistent node embeddings. Finally, we demonstrate the effectiveness of our model for community detection both theoretically and experimentally. Extensive experimental results also show that our CEGCL exhibits state-of-the-art performance on three benchmark datasets with different scales.
Contrastive Deep Nonnegative Matrix Factorization for Community Detection
Nov 04, 2023Recently, nonnegative matrix factorization (NMF) has been widely adopted for community detection, because of its better interpretability. However, the existing NMF-based methods have the following three problems: 1) they directly transform the original network into community membership space, so it is difficult for them to capture the hierarchical information; 2) they often only pay attention to the topology of the network and ignore its node attributes; 3) it is hard for them to learn the global structure information necessary for community detection. Therefore, we propose a new community detection algorithm, named Contrastive Deep Nonnegative Matrix Factorization (CDNMF). Firstly, we deepen NMF to strengthen its capacity for information extraction. Subsequently, inspired by contrastive learning, our algorithm creatively constructs network topology and node attributes as two contrasting views. Furthermore, we utilize a debiased negative sampling layer and learn node similarity at the community level, thereby enhancing the suitability of our model for community detection. We conduct experiments on three public real graph datasets and the proposed model has achieved better results than state-of-the-art methods. Code available at https://github.com/6lyc/CDNMF.git.
CLR: Channel-wise Lightweight Reprogramming for Continual Learning
Jul 21, 2023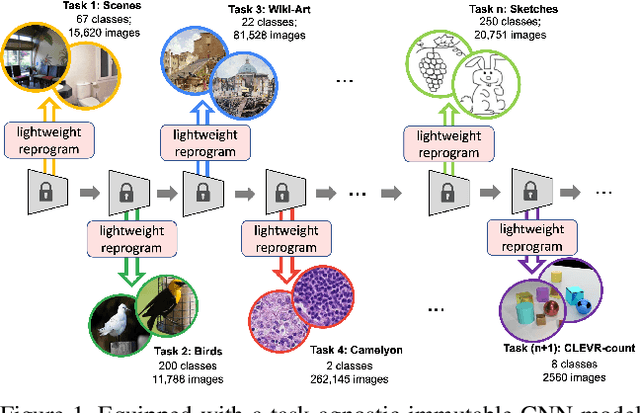

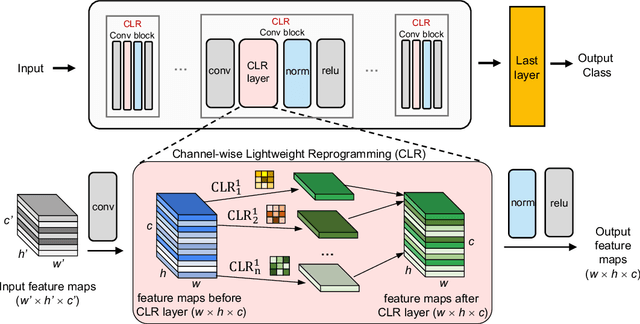
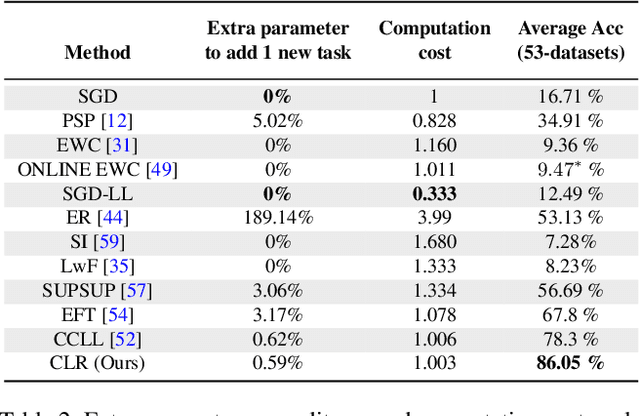
Continual learning aims to emulate the human ability to continually accumulate knowledge over sequential tasks. The main challenge is to maintain performance on previously learned tasks after learning new tasks, i.e., to avoid catastrophic forgetting. We propose a Channel-wise Lightweight Reprogramming (CLR) approach that helps convolutional neural networks (CNNs) overcome catastrophic forgetting during continual learning. We show that a CNN model trained on an old task (or self-supervised proxy task) could be ``reprogrammed" to solve a new task by using our proposed lightweight (very cheap) reprogramming parameter. With the help of CLR, we have a better stability-plasticity trade-off to solve continual learning problems: To maintain stability and retain previous task ability, we use a common task-agnostic immutable part as the shared ``anchor" parameter set. We then add task-specific lightweight reprogramming parameters to reinterpret the outputs of the immutable parts, to enable plasticity and integrate new knowledge. To learn sequential tasks, we only train the lightweight reprogramming parameters to learn each new task. Reprogramming parameters are task-specific and exclusive to each task, which makes our method immune to catastrophic forgetting. To minimize the parameter requirement of reprogramming to learn new tasks, we make reprogramming lightweight by only adjusting essential kernels and learning channel-wise linear mappings from anchor parameters to task-specific domain knowledge. We show that, for general CNNs, the CLR parameter increase is less than 0.6\% for any new task. Our method outperforms 13 state-of-the-art continual learning baselines on a new challenging sequence of 53 image classification datasets. Code and data are available at https://github.com/gyhandy/Channel-wise-Lightweight-Reprogramming
Lightweight Learner for Shared Knowledge Lifelong Learning
May 24, 2023
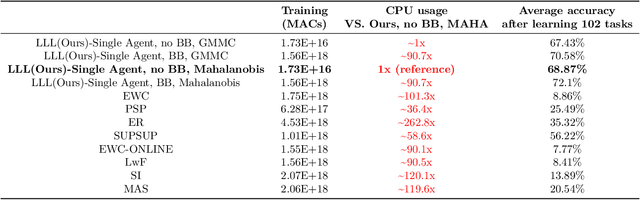

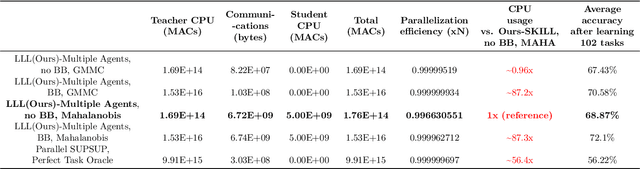
In Lifelong Learning (LL), agents continually learn as they encounter new conditions and tasks. Most current LL is limited to a single agent that learns tasks sequentially. Dedicated LL machinery is then deployed to mitigate the forgetting of old tasks as new tasks are learned. This is inherently slow. We propose a new Shared Knowledge Lifelong Learning (SKILL) challenge, which deploys a decentralized population of LL agents that each sequentially learn different tasks, with all agents operating independently and in parallel. After learning their respective tasks, agents share and consolidate their knowledge over a decentralized communication network, so that, in the end, all agents can master all tasks. We present one solution to SKILL which uses Lightweight Lifelong Learning (LLL) agents, where the goal is to facilitate efficient sharing by minimizing the fraction of the agent that is specialized for any given task. Each LLL agent thus consists of a common task-agnostic immutable part, where most parameters are, and individual task-specific modules that contain fewer parameters but are adapted to each task. Agents share their task-specific modules, plus summary information ("task anchors") representing their tasks in the common task-agnostic latent space of all agents. Receiving agents register each received task-specific module using the corresponding anchor. Thus, every agent improves its ability to solve new tasks each time new task-specific modules and anchors are received. On a new, very challenging SKILL-102 dataset with 102 image classification tasks (5,033 classes in total, 2,041,225 training, 243,464 validation, and 243,464 test images), we achieve much higher (and SOTA) accuracy over 8 LL baselines, while also achieving near perfect parallelization. Code and data can be found at https://github.com/gyhandy/Shared-Knowledge-Lifelong-Learning
Auto-CARD: Efficient and Robust Codec Avatar Driving for Real-time Mobile Telepresence
Apr 24, 2023



Real-time and robust photorealistic avatars for telepresence in AR/VR have been highly desired for enabling immersive photorealistic telepresence. However, there still exists one key bottleneck: the considerable computational expense needed to accurately infer facial expressions captured from headset-mounted cameras with a quality level that can match the realism of the avatar's human appearance. To this end, we propose a framework called Auto-CARD, which for the first time enables real-time and robust driving of Codec Avatars when exclusively using merely on-device computing resources. This is achieved by minimizing two sources of redundancy. First, we develop a dedicated neural architecture search technique called AVE-NAS for avatar encoding in AR/VR, which explicitly boosts both the searched architectures' robustness in the presence of extreme facial expressions and hardware friendliness on fast evolving AR/VR headsets. Second, we leverage the temporal redundancy in consecutively captured images during continuous rendering and develop a mechanism dubbed LATEX to skip the computation of redundant frames. Specifically, we first identify an opportunity from the linearity of the latent space derived by the avatar decoder and then propose to perform adaptive latent extrapolation for redundant frames. For evaluation, we demonstrate the efficacy of our Auto-CARD framework in real-time Codec Avatar driving settings, where we achieve a 5.05x speed-up on Meta Quest 2 while maintaining a comparable or even better animation quality than state-of-the-art avatar encoder designs.
DRESS: Dynamic REal-time Sparse Subnets
Jul 01, 2022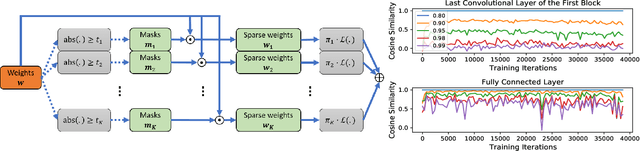
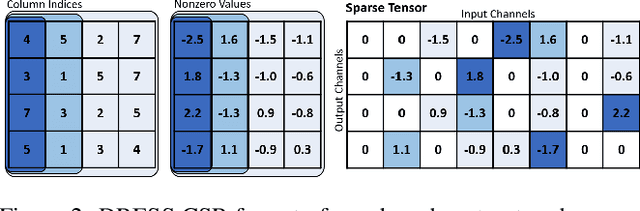
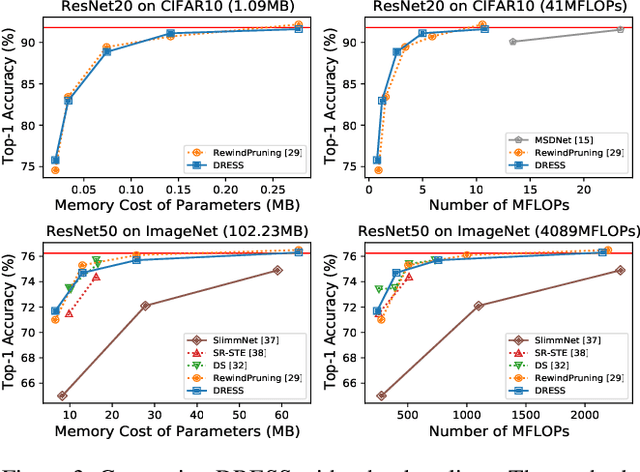
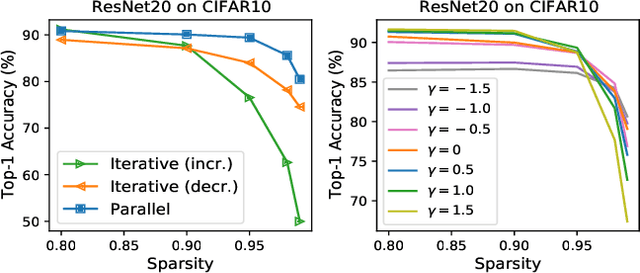
The limited and dynamically varied resources on edge devices motivate us to deploy an optimized deep neural network that can adapt its sub-networks to fit in different resource constraints. However, existing works often build sub-networks through searching different network architectures in a hand-crafted sampling space, which not only can result in a subpar performance but also may cause on-device re-configuration overhead. In this paper, we propose a novel training algorithm, Dynamic REal-time Sparse Subnets (DRESS). DRESS samples multiple sub-networks from the same backbone network through row-based unstructured sparsity, and jointly trains these sub-networks in parallel with weighted loss. DRESS also exploits strategies including parameter reusing and row-based fine-grained sampling for efficient storage consumption and efficient on-device adaptation. Extensive experiments on public vision datasets show that DRESS yields significantly higher accuracy than state-of-the-art sub-networks.
Power-of-Two Quantization for Low Bitwidth and Hardware Compliant Neural Networks
Mar 09, 2022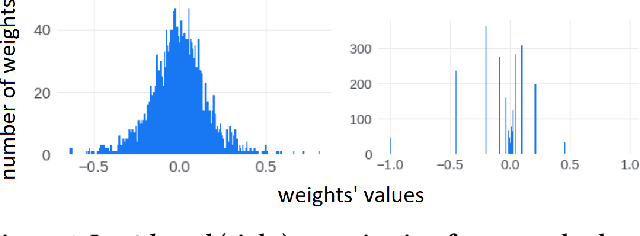
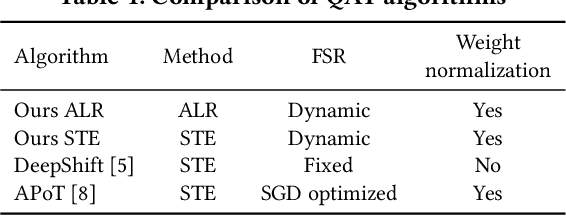
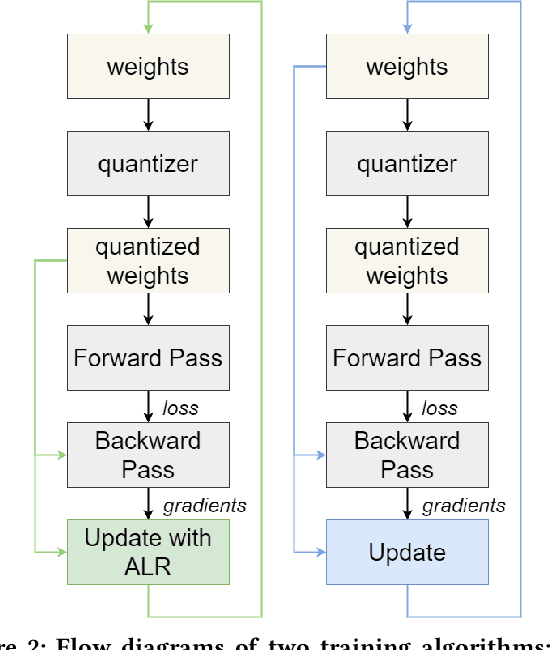
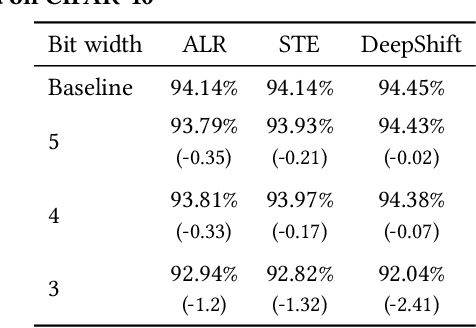
Deploying Deep Neural Networks in low-power embedded devices for real time-constrained applications requires optimization of memory and computational complexity of the networks, usually by quantizing the weights. Most of the existing works employ linear quantization which causes considerable degradation in accuracy for weight bit widths lower than 8. Since the distribution of weights is usually non-uniform (with most weights concentrated around zero), other methods, such as logarithmic quantization, are more suitable as they are able to preserve the shape of the weight distribution more precise. Moreover, using base-2 logarithmic representation allows optimizing the multiplication by replacing it with bit shifting. In this paper, we explore non-linear quantization techniques for exploiting lower bit precision and identify favorable hardware implementation options. We developed the Quantization Aware Training (QAT) algorithm that allowed training of low bit width Power-of-Two (PoT) networks and achieved accuracies on par with state-of-the-art floating point models for different tasks. We explored PoT weight encoding techniques and investigated hardware designs of MAC units for three different quantization schemes - uniform, PoT and Additive-PoT (APoT) - to show the increased efficiency when using the proposed approach. Eventually, the experiments showed that for low bit width precision, non-uniform quantization performs better than uniform, and at the same time, PoT quantization vastly reduces the computational complexity of the neural network.