 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePowerYOLO: Mixed Precision Model for Hardware Efficient Object Detection with Event Data
Jul 11, 2024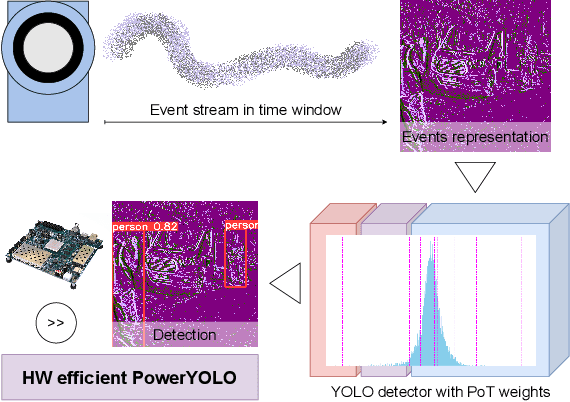

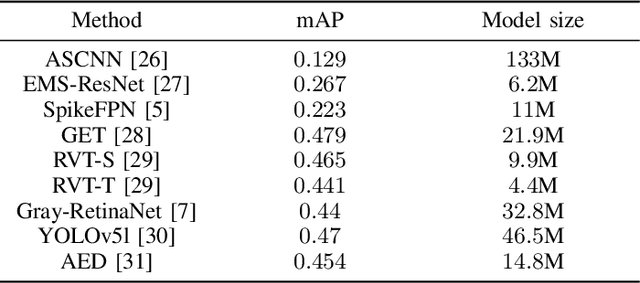
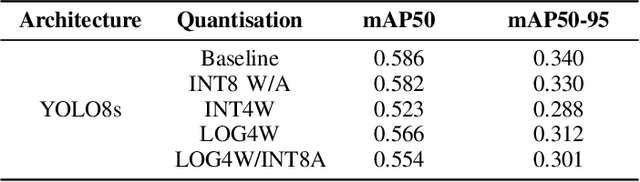
The performance of object detection systems in automotive solutions must be as high as possible, with minimal response time and, due to the often battery-powered operation, low energy consumption. When designing such solutions, we therefore face challenges typical for embedded vision systems: the problem of fitting algorithms of high memory and computational complexity into small low-power devices. In this paper we propose PowerYOLO - a mixed precision solution, which targets three essential elements of such application. First, we propose a system based on a Dynamic Vision Sensor (DVS), a novel sensor, that offers low power requirements and operates well in conditions with variable illumination. It is these features that may make event cameras a preferential choice over frame cameras in some applications. Second, to ensure high accuracy and low memory and computational complexity, we propose to use 4-bit width Powers-of-Two (PoT) quantisation for convolution weights of the YOLO detector, with all other parameters quantised linearly. Finally, we embrace from PoT scheme and replace multiplication with bit-shifting to increase the efficiency of hardware acceleration of such solution, with a special convolution-batch normalisation fusion scheme. The use of specific sensor with PoT quantisation and special batch normalisation fusion leads to a unique system with almost 8x reduction in memory complexity and vast computational simplifications, with relation to a standard approach. This efficient system achieves high accuracy of mAP 0.301 on the GEN1 DVS dataset, marking the new state-of-the-art for such compressed model.
Energy Efficient Hardware Acceleration of Neural Networks with Power-of-Two Quantisation
Sep 30, 2022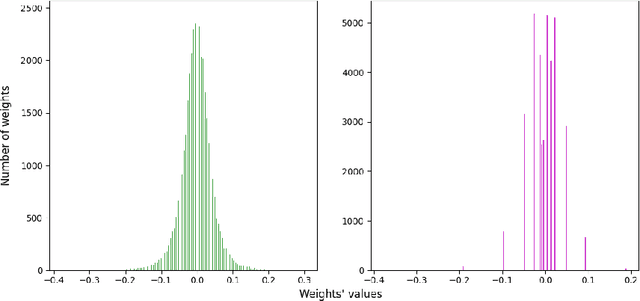

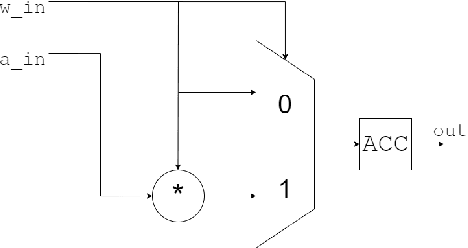

Deep neural networks virtually dominate the domain of most modern vision systems, providing high performance at a cost of increased computational complexity.Since for those systems it is often required to operate both in real-time and with minimal energy consumption (e.g., for wearable devices or autonomous vehicles, edge Internet of Things (IoT), sensor networks), various network optimisation techniques are used, e.g., quantisation, pruning, or dedicated lightweight architectures. Due to the logarithmic distribution of weights in neural network layers, a method providing high performance with significant reduction in computational precision (for 4-bit weights and less) is the Power-of-Two (PoT) quantisation (and therefore also with a logarithmic distribution). This method introduces additional possibilities of replacing the typical for neural networks Multiply and ACcumulate (MAC -- performing, e.g., convolution operations) units, with more energy-efficient Bitshift and ACcumulate (BAC). In this paper, we show that a hardware neural network accelerator with PoT weights implemented on the Zynq UltraScale + MPSoC ZCU104 SoC FPGA can be at least $1.4x$ more energy efficient than the uniform quantisation version. To further reduce the actual power requirement by omitting part of the computation for zero weights, we also propose a new pruning method adapted to logarithmic quantisation.
Towards real-time and energy efficient Siamese tracking -- a hardware-software approach
May 21, 2022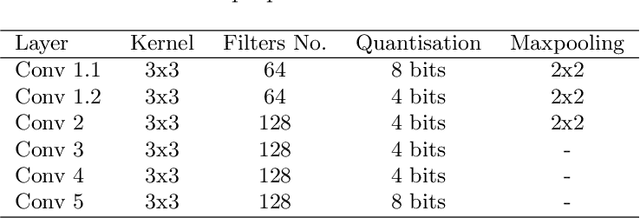
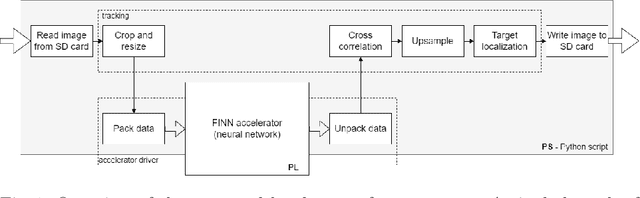


Siamese trackers have been among the state-of-the-art solutions in each Visual Object Tracking (VOT) challenge over the past few years. However, with great accuracy comes great computational complexity: to achieve real-time processing, these trackers have to be massively parallelised and are usually run on high-end GPUs. Easy to implement, this approach is energy consuming, and thus cannot be used in many low-power applications. To overcome this, one can use energy-efficient embedded devices, such as heterogeneous platforms joining the ARM processor system with programmable logic (FPGA). In this work, we propose a hardware-software implementation of the well-known fully connected Siamese tracker (SiamFC). We have developed a quantised Siamese network for the FINN accelerator, using algorithm-accelerator co-design, and performed design space exploration to achieve the best efficiency-to-energy ratio (determined by FPS and used resources). For our network, running in the programmable logic part of the Zynq UltraScale+ MPSoC ZCU104, we achieved the processing of almost 50 frames-per-second with tracker accuracy on par with its floating point counterpart, as well as the original SiamFC network. The complete tracking system, implemented in ARM with the network accelerated on FPGA, achieves up to 17 fps. These results bring us towards bridging the gap between the highly accurate but energy-demanding algorithms and energy-efficient solutions ready to be used in low-power, edge systems.
Power-of-Two Quantization for Low Bitwidth and Hardware Compliant Neural Networks
Mar 09, 2022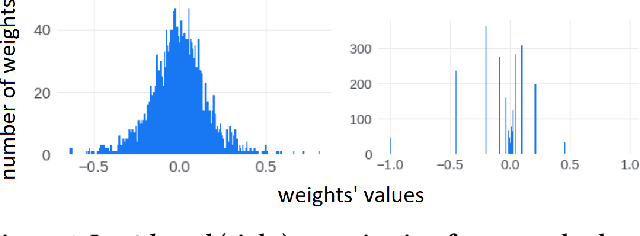
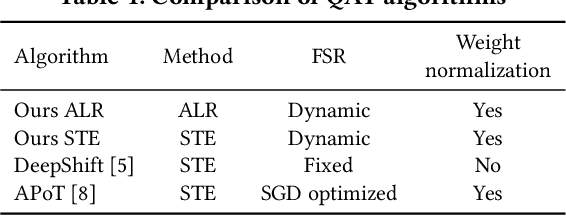
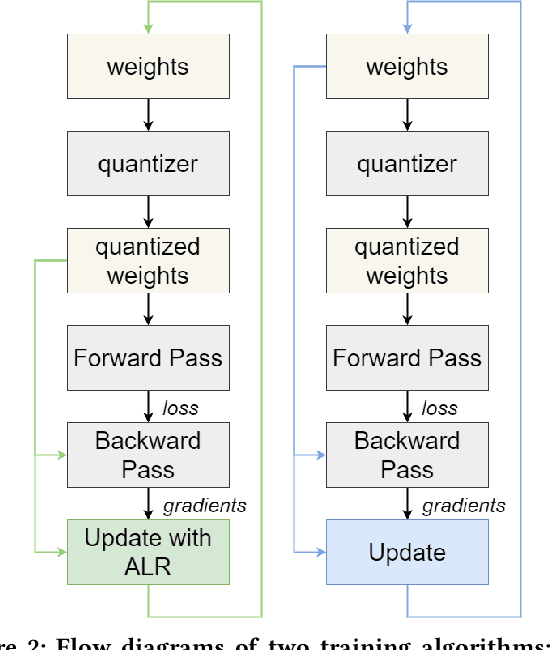
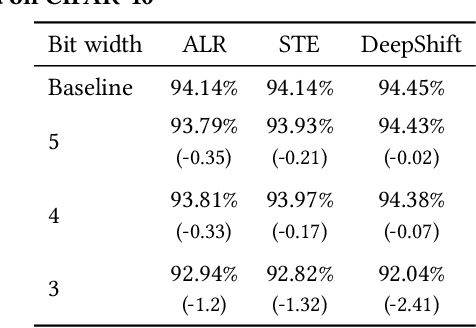
Deploying Deep Neural Networks in low-power embedded devices for real time-constrained applications requires optimization of memory and computational complexity of the networks, usually by quantizing the weights. Most of the existing works employ linear quantization which causes considerable degradation in accuracy for weight bit widths lower than 8. Since the distribution of weights is usually non-uniform (with most weights concentrated around zero), other methods, such as logarithmic quantization, are more suitable as they are able to preserve the shape of the weight distribution more precise. Moreover, using base-2 logarithmic representation allows optimizing the multiplication by replacing it with bit shifting. In this paper, we explore non-linear quantization techniques for exploiting lower bit precision and identify favorable hardware implementation options. We developed the Quantization Aware Training (QAT) algorithm that allowed training of low bit width Power-of-Two (PoT) networks and achieved accuracies on par with state-of-the-art floating point models for different tasks. We explored PoT weight encoding techniques and investigated hardware designs of MAC units for three different quantization schemes - uniform, PoT and Additive-PoT (APoT) - to show the increased efficiency when using the proposed approach. Eventually, the experiments showed that for low bit width precision, non-uniform quantization performs better than uniform, and at the same time, PoT quantization vastly reduces the computational complexity of the neural network.
Exploration of Hardware Acceleration Methods for an XNOR Traffic Signs Classifier
Apr 06, 2021



Deep learning algorithms are a key component of many state-of-the-art vision systems, especially as Convolutional Neural Networks (CNN) outperform most solutions in the sense of accuracy. To apply such algorithms in real-time applications, one has to address the challenges of memory and computational complexity. To deal with the first issue, we use networks with reduced precision, specifically a binary neural network (also known as XNOR). To satisfy the computational requirements, we propose to use highly parallel and low-power FPGA devices. In this work, we explore the possibility of accelerating XNOR networks for traffic sign classification. The trained binary networks are implemented on the ZCU 104 development board, equipped with a Zynq UltraScale+ MPSoC device using two different approaches. Firstly, we propose a custom HDL accelerator for XNOR networks, which enables the inference with almost 450 fps. Even better results are obtained with the second method - the Xilinx FINN accelerator - enabling to process input images with around 550 frame rate. Both approaches provide over 96% accuracy on the test set.