 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMsFormer: Enabling Robust Predictive Maintenance Services for Industrial Devices
Mar 24, 2026Providing reliable predictive maintenance is a critical industrial AI service essential for ensuring the high availability of manufacturing devices. Existing deep-learning methods present competitive results on such tasks but lack a general service-oriented framework to capture complex dependencies in industrial IoT sensor data. While Transformer-based models show strong sequence modeling capabilities, their direct deployment as robust AI services faces significant bottlenecks. Specifically, streaming sensor data collected in real-world service environments often exhibits multi-scale temporal correlations driven by machine working principles. Besides, the datasets available for training time-to-failure predictive services are typically limited in size. These issues pose significant challenges for directly applying existing models as robust predictive services. To address these challenges, we propose MsFormer, a lightweight Multi-scale Transformer designed as a unified AI service model for reliable industrial predictive maintenance. MsFormer incorporates a Multi-scale Sampling (MS) module and a tailored position encoding mechanism to capture sequential correlations across multi-streaming service data. Additionally, to accommodate data-scarce service environments, MsFormer adopts a lightweight attention mechanism with straightforward pooling operations instead of self-attention. Extensive experiments on real-world datasets demonstrate that the proposed framework achieves significant performance improvements over state-of-the-art methods. Furthermore, MsFormer outperforms across industrial devices and operating conditions, demonstrating strong generalizability while maintaining a highly reliable Quality of Service (QoS).
Time Series Reasoning via Process-Verifiable Thinking Data Synthesis and Scheduling for Tailored LLM Reasoning
Feb 08, 2026Time series is a pervasive data type across various application domains, rendering the reasonable solving of diverse time series tasks a long-standing goal. Recent advances in large language models (LLMs), especially their reasoning abilities unlocked through reinforcement learning (RL), have opened new opportunities for tackling tasks with long Chain-of-Thought (CoT) reasoning. However, leveraging LLM reasoning for time series remains in its infancy, hindered by the absence of carefully curated time series CoT data for training, limited data efficiency caused by underexplored data scheduling, and the lack of RL algorithms tailored for exploiting such time series CoT data. In this paper, we introduce VeriTime, a framework that tailors LLMs for time series reasoning through data synthesis, data scheduling, and RL training. First, we propose a data synthesis pipeline that constructs a TS-text multimodal dataset with process-verifiable annotations. Second, we design a data scheduling mechanism that arranges training samples according to a principled hierarchy of difficulty and task taxonomy. Third, we develop a two-stage reinforcement finetuning featuring fine-grained, multi-objective rewards that leverage verifiable process-level CoT data. Extensive experiments show that VeriTime substantially boosts LLM performance across diverse time series reasoning tasks. Notably, it enables compact 3B, 4B models to achieve reasoning capabilities on par with or exceeding those of larger proprietary LLMs.
Understanding and Preserving Safety in Fine-Tuned LLMs
Jan 15, 2026Fine-tuning is an essential and pervasive functionality for applying large language models (LLMs) to downstream tasks. However, it has the potential to substantially degrade safety alignment, e.g., by greatly increasing susceptibility to jailbreak attacks, even when the fine-tuning data is entirely harmless. Despite garnering growing attention in defense efforts during the fine-tuning stage, existing methods struggle with a persistent safety-utility dilemma: emphasizing safety compromises task performance, whereas prioritizing utility typically requires deep fine-tuning that inevitably leads to steep safety declination. In this work, we address this dilemma by shedding new light on the geometric interaction between safety- and utility-oriented gradients in safety-aligned LLMs. Through systematic empirical analysis, we uncover three key insights: (I) safety gradients lie in a low-rank subspace, while utility gradients span a broader high-dimensional space; (II) these subspaces are often negatively correlated, causing directional conflicts during fine-tuning; and (III) the dominant safety direction can be efficiently estimated from a single sample. Building upon these novel insights, we propose safety-preserving fine-tuning (SPF), a lightweight approach that explicitly removes gradient components conflicting with the low-rank safety subspace. Theoretically, we show that SPF guarantees utility convergence while bounding safety drift. Empirically, SPF consistently maintains downstream task performance and recovers nearly all pre-trained safety alignment, even under adversarial fine-tuning scenarios. Furthermore, SPF exhibits robust resistance to both deep fine-tuning and dynamic jailbreak attacks. Together, our findings provide new mechanistic understanding and practical guidance toward always-aligned LLM fine-tuning.
Safety at One Shot: Patching Fine-Tuned LLMs with A Single Instance
Jan 06, 2026Fine-tuning safety-aligned large language models (LLMs) can substantially compromise their safety. Previous approaches require many safety samples or calibration sets, which not only incur significant computational overhead during realignment but also lead to noticeable degradation in model utility. Contrary to this belief, we show that safety alignment can be fully recovered with only a single safety example, without sacrificing utility and at minimal cost. Remarkably, this recovery is effective regardless of the number of harmful examples used in fine-tuning or the size of the underlying model, and convergence is achieved within just a few epochs. Furthermore, we uncover the low-rank structure of the safety gradient, which explains why such efficient correction is possible. We validate our findings across five safety-aligned LLMs and multiple datasets, demonstrating the generality of our approach.
Lightweight Time Series Data Valuation on Time Series Foundation Models via In-Context Finetuning
Nov 10, 2025Time series foundation models (TSFMs) have demonstrated increasing capabilities due to their extensive pretraining on large volumes of diverse time series data. Consequently, the quality of time series data is crucial to TSFM performance, rendering an accurate and efficient data valuation of time series for TSFMs indispensable. However, traditional data valuation methods, such as influence functions, face severe computational bottlenecks due to their poor scalability with growing TSFM model sizes and often fail to preserve temporal dependencies. In this paper, we propose LTSV, a Lightweight Time Series Valuation on TSFMS via in-context finetuning. Grounded in the theoretical evidence that in-context finetuning approximates the influence function, LTSV estimates a sample's contribution by measuring the change in context loss after in-context finetuning, leveraging the strong generalization capabilities of TSFMs to produce robust and transferable data valuations. To capture temporal dependencies, we introduce temporal block aggregation, which integrates per-block influence scores across overlapping time windows. Experiments across multiple time series datasets and models demonstrate that LTSV consistently provides reliable and strong valuation performance, while maintaining manageable computational requirements. Our results suggest that in-context finetuning on time series foundation models provides a practical and effective bridge between data attribution and model generalization in time series learning.
Module-Aware Parameter-Efficient Machine Unlearning on Transformers
Aug 24, 2025Transformer has become fundamental to a vast series of pre-trained large models that have achieved remarkable success across diverse applications. Machine unlearning, which focuses on efficiently removing specific data influences to comply with privacy regulations, shows promise in restricting updates to influence-critical parameters. However, existing parameter-efficient unlearning methods are largely devised in a module-oblivious manner, which tends to inaccurately identify these parameters and leads to inferior unlearning performance for Transformers. In this paper, we propose {\tt MAPE-Unlearn}, a module-aware parameter-efficient machine unlearning approach that uses a learnable pair of masks to pinpoint influence-critical parameters in the heads and filters of Transformers. The learning objective of these masks is derived by desiderata of unlearning and optimized through an efficient algorithm featured by a greedy search with a warm start. Extensive experiments on various Transformer models and datasets demonstrate the effectiveness and robustness of {\tt MAPE-Unlearn} for unlearning.
Safeguarding Multimodal Knowledge Copyright in the RAG-as-a-Service Environment
Jun 10, 2025
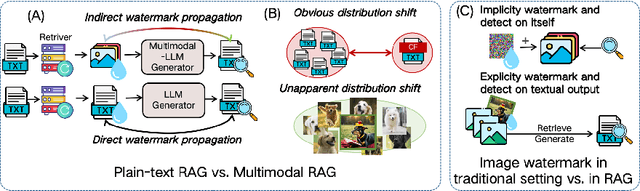


As Retrieval-Augmented Generation (RAG) evolves into service-oriented platforms (Rag-as-a-Service) with shared knowledge bases, protecting the copyright of contributed data becomes essential. Existing watermarking methods in RAG focus solely on textual knowledge, leaving image knowledge unprotected. In this work, we propose AQUA, the first watermark framework for image knowledge protection in Multimodal RAG systems. AQUA embeds semantic signals into synthetic images using two complementary methods: acronym-based triggers and spatial relationship cues. These techniques ensure watermark signals survive indirect watermark propagation from image retriever to textual generator, being efficient, effective and imperceptible. Experiments across diverse models and datasets show that AQUA enables robust, stealthy, and reliable copyright tracing, filling a key gap in multimodal RAG protection.
SHAPE : Self-Improved Visual Preference Alignment by Iteratively Generating Holistic Winner
Mar 06, 2025



Large Visual Language Models (LVLMs) increasingly rely on preference alignment to ensure reliability, which steers the model behavior via preference fine-tuning on preference data structured as ``image - winner text - loser text'' triplets. However, existing approaches often suffer from limited diversity and high costs associated with human-annotated preference data, hindering LVLMs from fully achieving their intended alignment capabilities. We present \projectname, a self-supervised framework capable of transforming the already abundant supervised text-image pairs into holistic preference triplets for more effective and cheaper LVLM alignment, eliminating the need for human preference annotations. Our approach facilitates LVLMs in progressively enhancing alignment capabilities through iterative self-improvement. The key design rationale is to devise preference triplets where the winner text consistently improves in holisticness and outperforms the loser response in quality, thereby pushing the model to ``strive to the utmost'' of alignment performance through preference fine-tuning. For each given text-image pair, SHAPE introduces multiple visual augmentations and pairs them with a summarized text to serve as the winner response, while designating the original text as the loser response. Experiments across \textbf{12} benchmarks on various model architectures and sizes, including LLaVA and DeepSeek-VL, show that SHAPE achieves significant gains, for example, achieving +11.3\% on MMVet (comprehensive evaluation), +1.4\% on MMBench (general VQA), and +8.0\% on POPE (hallucination robustness) over baselines in 7B models. Notably, qualitative analyses confirm enhanced attention to visual details and better alignment with human preferences for holistic descriptions.
SecPE: Secure Prompt Ensembling for Private and Robust Large Language Models
Feb 02, 2025



With the growing popularity of LLMs among the general public users, privacy-preserving and adversarial robustness have become two pressing demands for LLM-based services, which have largely been pursued separately but rarely jointly. In this paper, to the best of our knowledge, we are among the first attempts towards robust and private LLM inference by tightly integrating two disconnected fields: private inference and prompt ensembling. The former protects users' privacy by encrypting inference data transmitted and processed by LLMs, while the latter enhances adversarial robustness by yielding an aggregated output from multiple prompted LLM responses. Although widely recognized as effective individually, private inference for prompt ensembling together entails new challenges that render the naive combination of existing techniques inefficient. To overcome the hurdles, we propose SecPE, which designs efficient fully homomorphic encryption (FHE) counterparts for the core algorithmic building blocks of prompt ensembling. We conduct extensive experiments on 8 tasks to evaluate the accuracy, robustness, and efficiency of SecPE. The results show that SecPE maintains high clean accuracy and offers better robustness at the expense of merely $2.5\%$ efficiency overhead compared to baseline private inference methods, indicating a satisfactory ``accuracy-robustness-efficiency'' tradeoff. For the efficiency of the encrypted Argmax operation that incurs major slowdown for prompt ensembling, SecPE is 35.4x faster than the state-of-the-art peers, which can be of independent interest beyond this work.
Activation Approximations Can Incur Safety Vulnerabilities Even in Aligned LLMs: Comprehensive Analysis and Defense
Feb 02, 2025



Large Language Models (LLMs) have showcased remarkable capabilities across various domains. Accompanying the evolving capabilities and expanding deployment scenarios of LLMs, their deployment challenges escalate due to their sheer scale and the advanced yet complex activation designs prevalent in notable model series, such as Llama, Gemma, and Mistral. These challenges have become particularly pronounced in resource-constrained deployment scenarios, where mitigating inference efficiency bottlenecks is imperative. Among various recent efforts, activation approximation has emerged as a promising avenue for pursuing inference efficiency, sometimes considered indispensable in applications such as private inference. Despite achieving substantial speedups with minimal impact on utility, even appearing sound and practical for real-world deployment, the safety implications of activation approximations remain unclear. In this work, we fill this critical gap in LLM safety by conducting the first systematic safety evaluation of activation approximations. Our safety vetting spans seven sota techniques across three popular categories, revealing consistent safety degradation across ten safety-aligned LLMs.