 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNode-level Contrastive Unlearning on Graph Neural Networks
Mar 04, 2025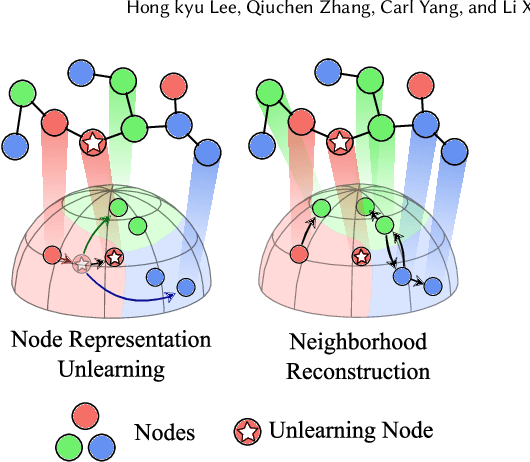
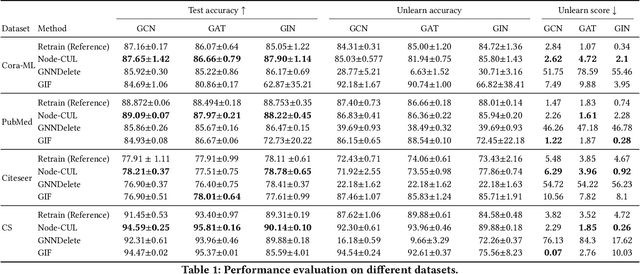
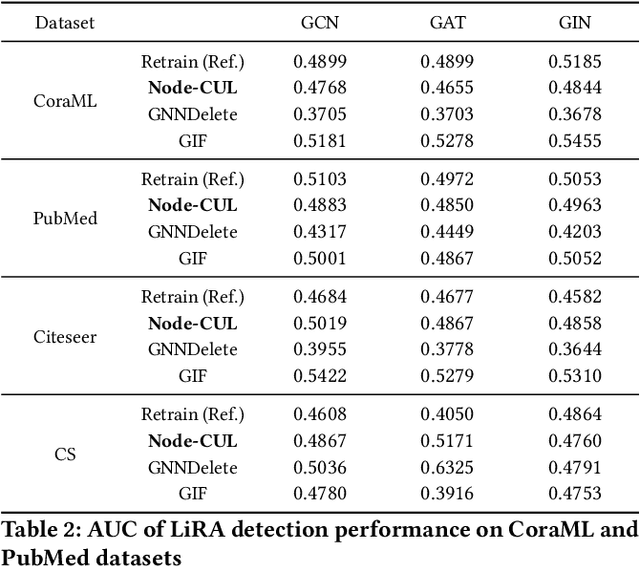
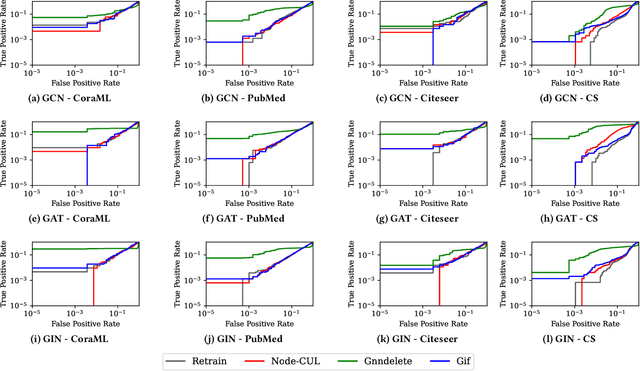
Graph unlearning aims to remove a subset of graph entities (i.e. nodes and edges) from a graph neural network (GNN) trained on the graph. Unlike machine unlearning for models trained on Euclidean-structured data, effectively unlearning a model trained on non-Euclidean-structured data, such as graphs, is challenging because graph entities exhibit mutual dependencies. Existing works utilize graph partitioning, influence function, or additional layers to achieve graph unlearning. However, none of them can achieve high scalability and effectiveness without additional constraints. In this paper, we achieve more effective graph unlearning by utilizing the embedding space. The primary training objective of a GNN is to generate proper embeddings for each node that encapsulates both structural information and node feature representations. Thus, directly optimizing the embedding space can effectively remove the target nodes' information from the model. Based on this intuition, we propose node-level contrastive unlearning (Node-CUL). It removes the influence of the target nodes (unlearning nodes) by contrasting the embeddings of remaining nodes and neighbors of unlearning nodes. Through iterative updates, the embeddings of unlearning nodes gradually become similar to those of unseen nodes, effectively removing the learned information without directly incorporating unseen data. In addition, we introduce a neighborhood reconstruction method that optimizes the embeddings of the neighbors in order to remove influence of unlearning nodes to maintain the utility of the GNN model. Experiments on various graph data and models show that our Node-CUL achieves the best unlearn efficacy and enhanced model utility with requiring comparable computing resources with existing frameworks.
Contrastive Unlearning: A Contrastive Approach to Machine Unlearning
Jan 19, 2024



Machine unlearning aims to eliminate the influence of a subset of training samples (i.e., unlearning samples) from a trained model. Effectively and efficiently removing the unlearning samples without negatively impacting the overall model performance is still challenging. In this paper, we propose a contrastive unlearning framework, leveraging the concept of representation learning for more effective unlearning. It removes the influence of unlearning samples by contrasting their embeddings against the remaining samples so that they are pushed away from their original classes and pulled toward other classes. By directly optimizing the representation space, it effectively removes the influence of unlearning samples while maintaining the representations learned from the remaining samples. Experiments on a variety of datasets and models on both class unlearning and sample unlearning showed that contrastive unlearning achieves the best unlearning effects and efficiency with the lowest performance loss compared with the state-of-the-art algorithms.
Private Semi-supervised Knowledge Transfer for Deep Learning from Noisy Labels
Nov 03, 2022Deep learning models trained on large-scale data have achieved encouraging performance in many real-world tasks. Meanwhile, publishing those models trained on sensitive datasets, such as medical records, could pose serious privacy concerns. To counter these issues, one of the current state-of-the-art approaches is the Private Aggregation of Teacher Ensembles, or PATE, which achieved promising results in preserving the utility of the model while providing a strong privacy guarantee. PATE combines an ensemble of "teacher models" trained on sensitive data and transfers the knowledge to a "student" model through the noisy aggregation of teachers' votes for labeling unlabeled public data which the student model will be trained on. However, the knowledge or voted labels learned by the student are noisy due to private aggregation. Learning directly from noisy labels can significantly impact the accuracy of the student model. In this paper, we propose the PATE++ mechanism, which combines the current advanced noisy label training mechanisms with the original PATE framework to enhance its accuracy. A novel structure of Generative Adversarial Nets (GANs) is developed in order to integrate them effectively. In addition, we develop a novel noisy label detection mechanism for semi-supervised model training to further improve student model performance when training with noisy labels. We evaluate our method on Fashion-MNIST and SVHN to show the improvements on the original PATE on all measures.
Towards Training Graph Neural Networks with Node-Level Differential Privacy
Oct 10, 2022
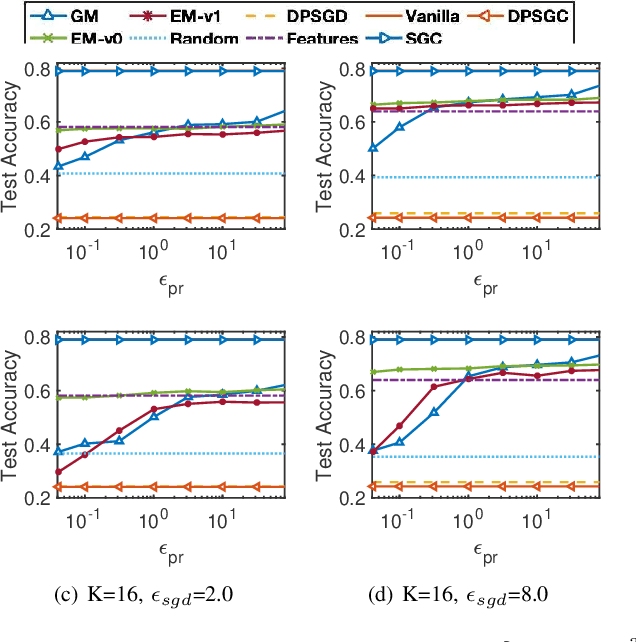


Graph Neural Networks (GNNs) have achieved great success in mining graph-structured data. Despite the superior performance of GNNs in learning graph representations, serious privacy concerns have been raised for the trained models which could expose the sensitive information of graphs. We conduct the first formal study of training GNN models to ensure utility while satisfying the rigorous node-level differential privacy considering the private information of both node features and edges. We adopt the training framework utilizing personalized PageRank to decouple the message-passing process from feature aggregation during training GNN models and propose differentially private PageRank algorithms to protect graph topology information formally. Furthermore, we analyze the privacy degradation caused by the sampling process dependent on the differentially private PageRank results during model training and propose a differentially private GNN (DPGNN) algorithm to further protect node features and achieve rigorous node-level differential privacy. Extensive experiments on real-world graph datasets demonstrate the effectiveness of the proposed algorithms for providing node-level differential privacy while preserving good model utility.
Communication Efficient Tensor Factorization for Decentralized Healthcare Networks
Sep 03, 2021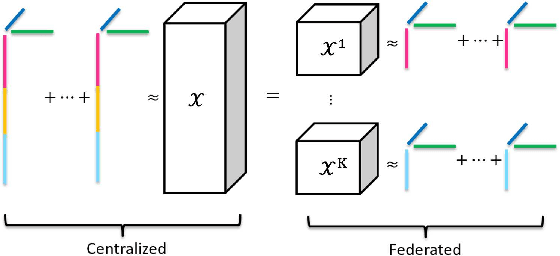
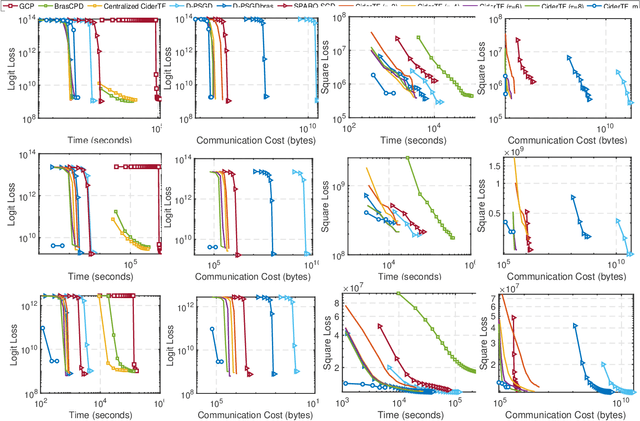
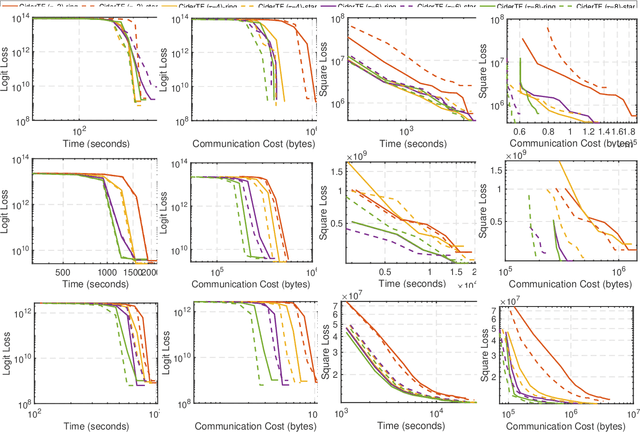
Tensor factorization has been proved as an efficient unsupervised learning approach for health data analysis, especially for computational phenotyping, where the high-dimensional Electronic Health Records (EHRs) with patients history of medical procedures, medications, diagnosis, lab tests, etc., are converted to meaningful and interpretable medical concepts. Federated tensor factorization distributes the tensor computation to multiple workers under the coordination of a central server, which enables jointly learning the phenotypes across multiple hospitals while preserving the privacy of the patient information. However, existing federated tensor factorization algorithms encounter the single-point-failure issue with the involvement of the central server, which is not only easily exposed to external attacks, but also limits the number of clients sharing information with the server under restricted uplink bandwidth. In this paper, we propose CiderTF, a communication-efficient decentralized generalized tensor factorization, which reduces the uplink communication cost by leveraging a four-level communication reduction strategy designed for a generalized tensor factorization, which has the flexibility of modeling different tensor distribution with multiple kinds of loss functions. Experiments on two real-world EHR datasets demonstrate that CiderTF achieves comparable convergence with the communication reduction up to 99.99%.
Temporal Network Embedding via Tensor Factorization
Aug 22, 2021


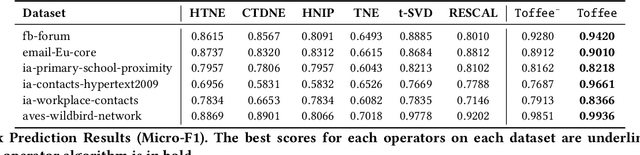
Representation learning on static graph-structured data has shown a significant impact on many real-world applications. However, less attention has been paid to the evolving nature of temporal networks, in which the edges are often changing over time. The embeddings of such temporal networks should encode both graph-structured information and the temporally evolving pattern. Existing approaches in learning temporally evolving network representations fail to capture the temporal interdependence. In this paper, we propose Toffee, a novel approach for temporal network representation learning based on tensor decomposition. Our method exploits the tensor-tensor product operator to encode the cross-time information, so that the periodic changes in the evolving networks can be captured. Experimental results demonstrate that Toffee outperforms existing methods on multiple real-world temporal networks in generating effective embeddings for the link prediction tasks.
Spatio-Temporal Tensor Sketching via Adaptive Sampling
Jun 21, 2020

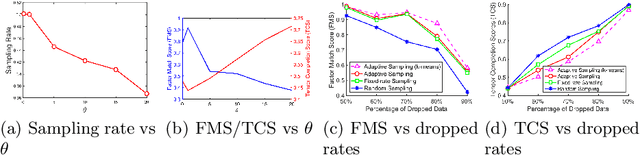
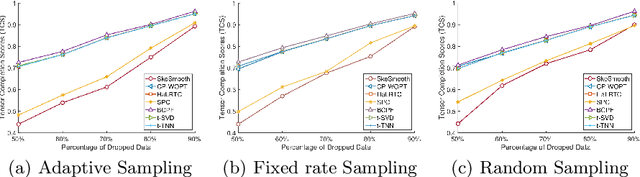
Mining massive spatio-temporal data can help a variety of real-world applications such as city capacity planning, event management, and social network analysis. The tensor representation can be used to capture the correlation between space and time and simultaneously exploit the latent structure of the spatial and temporal patterns in an unsupervised fashion. However, the increasing volume of spatio-temporal data has made it prohibitively expensive to store and analyze using tensor factorization. In this paper, we propose SkeTenSmooth, a novel tensor factorization framework that uses adaptive sampling to compress the tensor in a temporally streaming fashion and preserves the underlying global structure. SkeTenSmooth adaptively samples incoming tensor slices according to the detected data dynamics. Thus, the sketches are more representative and informative of the tensor dynamic patterns. In addition, we propose a robust tensor factorization method that can deal with the sketched tensor and recover the original patterns. Experiments on the New York City Yellow Taxi data show that SkeTenSmooth greatly reduces the memory cost and outperforms random sampling and fixed rate sampling method in terms of retaining the underlying patterns.
Privacy-Preserving Tensor Factorization for Collaborative Health Data Analysis
Aug 26, 2019
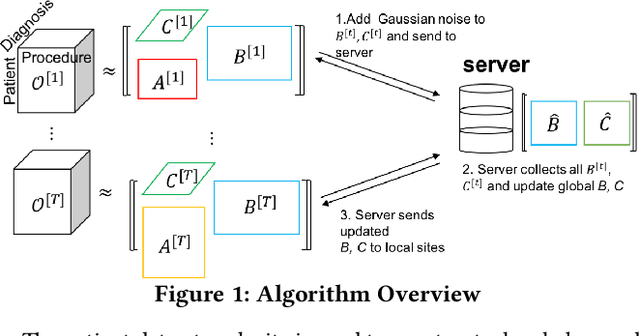
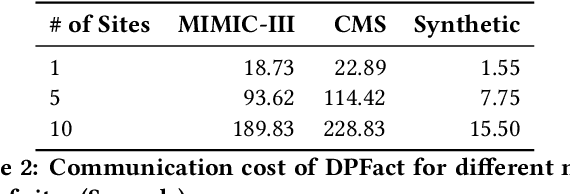
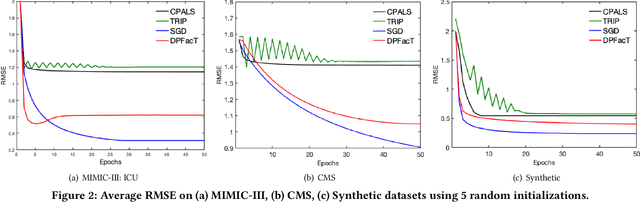
Tensor factorization has been demonstrated as an efficient approach for computational phenotyping, where massive electronic health records (EHRs) are converted to concise and meaningful clinical concepts. While distributing the tensor factorization tasks to local sites can avoid direct data sharing, it still requires the exchange of intermediary results which could reveal sensitive patient information. Therefore, the challenge is how to jointly decompose the tensor under rigorous and principled privacy constraints, while still support the model's interpretability. We propose DPFact, a privacy-preserving collaborative tensor factorization method for computational phenotyping using EHR. It embeds advanced privacy-preserving mechanisms with collaborative learning. Hospitals can keep their EHR database private but also collaboratively learn meaningful clinical concepts by sharing differentially private intermediary results. Moreover, DPFact solves the heterogeneous patient population using a structured sparsity term. In our framework, each hospital decomposes its local tensors, and sends the updated intermediary results with output perturbation every several iterations to a semi-trusted server which generates the phenotypes. The evaluation on both real-world and synthetic datasets demonstrated that under strict privacy constraints, our method is more accurate and communication-efficient than state-of-the-art baseline methods.