 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBicKD: Bilateral Contrastive Knowledge Distillation
Feb 01, 2026Knowledge distillation (KD) is a machine learning framework that transfers knowledge from a teacher model to a student model. The vanilla KD proposed by Hinton et al. has been the dominant approach in logit-based distillation and demonstrates compelling performance. However, it only performs sample-wise probability alignment between teacher and student's predictions, lacking an mechanism for class-wise comparison. Besides, vanilla KD imposes no structural constraint on the probability space. In this work, we propose a simple yet effective methodology, bilateral contrastive knowledge distillation (BicKD). This approach introduces a novel bilateral contrastive loss, which intensifies the orthogonality among different class generalization spaces while preserving consistency within the same class. The bilateral formulation enables explicit comparison of both sample-wise and class-wise prediction patterns between teacher and student. By emphasizing probabilistic orthogonality, BicKD further regularizes the geometric structure of the predictive distribution. Extensive experiments show that our BicKD method enhances knowledge transfer, and consistently outperforms state-of-the-art knowledge distillation techniques across various model architectures and benchmarks.
Sharpness-Aware Parameter Selection for Machine Unlearning
Apr 08, 2025


It often happens that some sensitive personal information, such as credit card numbers or passwords, are mistakenly incorporated in the training of machine learning models and need to be removed afterwards. The removal of such information from a trained model is a complex task that needs to partially reverse the training process. There have been various machine unlearning techniques proposed in the literature to address this problem. Most of the proposed methods revolve around removing individual data samples from a trained model. Another less explored direction is when features/labels of a group of data samples need to be reverted. While the existing methods for these tasks do the unlearning task by updating the whole set of model parameters or only the last layer of the model, we show that there are a subset of model parameters that have the largest contribution in the unlearning target features. More precisely, the model parameters with the largest corresponding diagonal value in the Hessian matrix (computed at the learned model parameter) have the most contribution in the unlearning task. By selecting these parameters and updating them during the unlearning stage, we can have the most progress in unlearning. We provide theoretical justifications for the proposed strategy by connecting it to sharpness-aware minimization and robust unlearning. We empirically show the effectiveness of the proposed strategy in improving the efficacy of unlearning with a low computational cost.
Node-level Contrastive Unlearning on Graph Neural Networks
Mar 04, 2025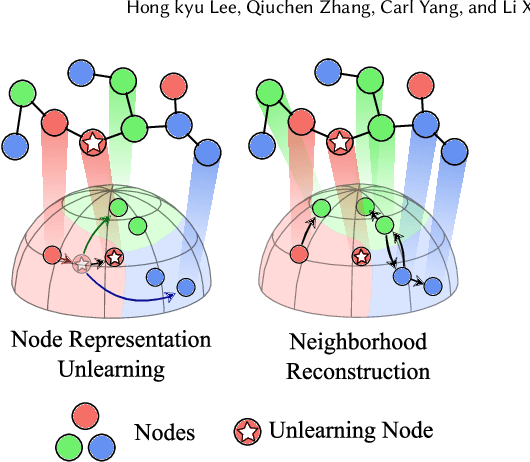
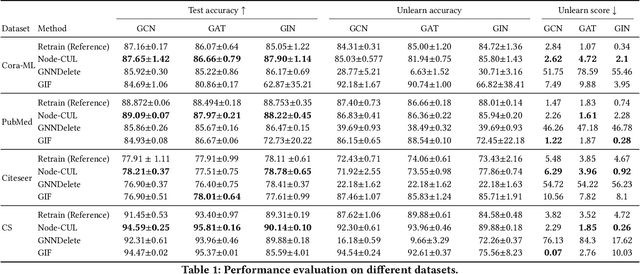
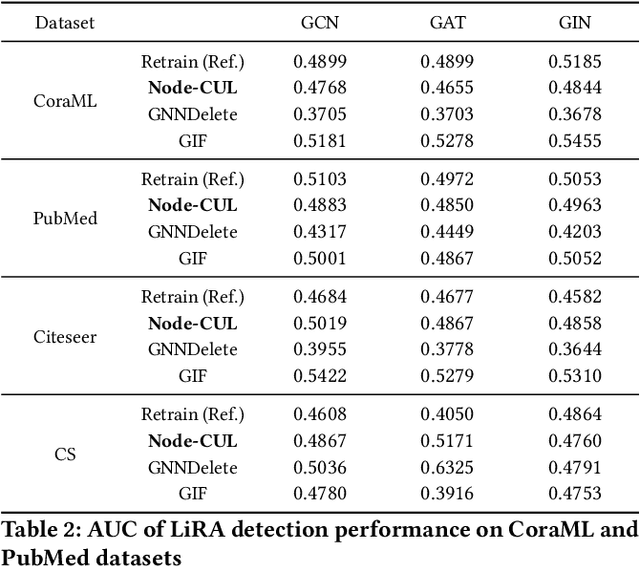
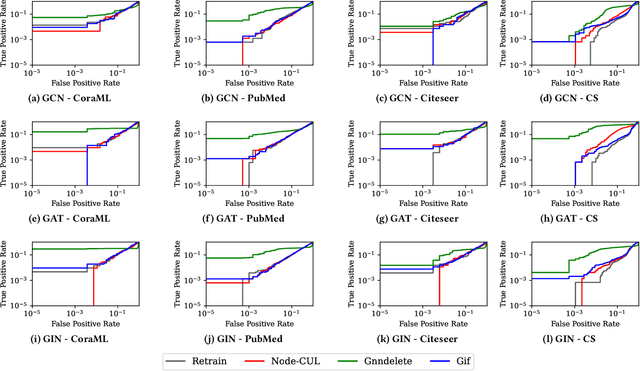
Graph unlearning aims to remove a subset of graph entities (i.e. nodes and edges) from a graph neural network (GNN) trained on the graph. Unlike machine unlearning for models trained on Euclidean-structured data, effectively unlearning a model trained on non-Euclidean-structured data, such as graphs, is challenging because graph entities exhibit mutual dependencies. Existing works utilize graph partitioning, influence function, or additional layers to achieve graph unlearning. However, none of them can achieve high scalability and effectiveness without additional constraints. In this paper, we achieve more effective graph unlearning by utilizing the embedding space. The primary training objective of a GNN is to generate proper embeddings for each node that encapsulates both structural information and node feature representations. Thus, directly optimizing the embedding space can effectively remove the target nodes' information from the model. Based on this intuition, we propose node-level contrastive unlearning (Node-CUL). It removes the influence of the target nodes (unlearning nodes) by contrasting the embeddings of remaining nodes and neighbors of unlearning nodes. Through iterative updates, the embeddings of unlearning nodes gradually become similar to those of unseen nodes, effectively removing the learned information without directly incorporating unseen data. In addition, we introduce a neighborhood reconstruction method that optimizes the embeddings of the neighbors in order to remove influence of unlearning nodes to maintain the utility of the GNN model. Experiments on various graph data and models show that our Node-CUL achieves the best unlearn efficacy and enhanced model utility with requiring comparable computing resources with existing frameworks.
Contrastive Unlearning: A Contrastive Approach to Machine Unlearning
Jan 19, 2024



Machine unlearning aims to eliminate the influence of a subset of training samples (i.e., unlearning samples) from a trained model. Effectively and efficiently removing the unlearning samples without negatively impacting the overall model performance is still challenging. In this paper, we propose a contrastive unlearning framework, leveraging the concept of representation learning for more effective unlearning. It removes the influence of unlearning samples by contrasting their embeddings against the remaining samples so that they are pushed away from their original classes and pulled toward other classes. By directly optimizing the representation space, it effectively removes the influence of unlearning samples while maintaining the representations learned from the remaining samples. Experiments on a variety of datasets and models on both class unlearning and sample unlearning showed that contrastive unlearning achieves the best unlearning effects and efficiency with the lowest performance loss compared with the state-of-the-art algorithms.