 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoT-RAG: Integrating Chain of Thought and Retrieval-Augmented Generation to Enhance Reasoning in Large Language Models
Apr 18, 2025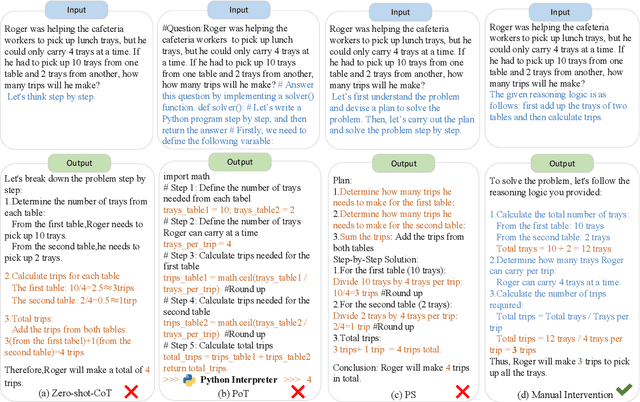

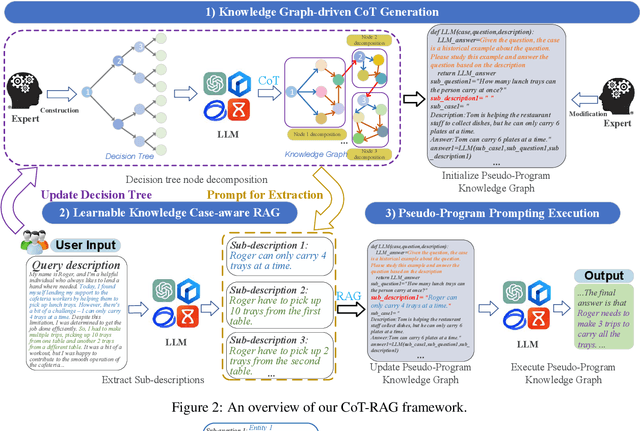

While chain-of-thought (CoT) reasoning improves the performance of large language models (LLMs) in complex tasks, it still has two main challenges: the low reliability of relying solely on LLMs to generate reasoning chains and the interference of natural language reasoning chains on the inference logic of LLMs. To address these issues, we propose CoT-RAG, a novel reasoning framework with three key designs: (i) Knowledge Graph-driven CoT Generation, featuring knowledge graphs to modulate reasoning chain generation of LLMs, thereby enhancing reasoning credibility; (ii) Learnable Knowledge Case-aware RAG, which incorporates retrieval-augmented generation (RAG) into knowledge graphs to retrieve relevant sub-cases and sub-descriptions, providing LLMs with learnable information; (iii) Pseudo-Program Prompting Execution, which encourages LLMs to execute reasoning tasks in pseudo-programs with greater logical rigor. We conduct a comprehensive evaluation on nine public datasets, covering three reasoning problems. Compared with the-state-of-the-art methods, CoT-RAG exhibits a significant accuracy improvement, ranging from 4.0% to 23.0%. Furthermore, testing on four domain-specific datasets, CoT-RAG shows remarkable accuracy and efficient execution, highlighting its strong practical applicability and scalability.
Physical Backdoor: Towards Temperature-based Backdoor Attacks in the Physical World
Apr 30, 2024



Backdoor attacks have been well-studied in visible light object detection (VLOD) in recent years. However, VLOD can not effectively work in dark and temperature-sensitive scenarios. Instead, thermal infrared object detection (TIOD) is the most accessible and practical in such environments. In this paper, our team is the first to investigate the security vulnerabilities associated with TIOD in the context of backdoor attacks, spanning both the digital and physical realms. We introduce two novel types of backdoor attacks on TIOD, each offering unique capabilities: Object-affecting Attack and Range-affecting Attack. We conduct a comprehensive analysis of key factors influencing trigger design, which include temperature, size, material, and concealment. These factors, especially temperature, significantly impact the efficacy of backdoor attacks on TIOD. A thorough understanding of these factors will serve as a foundation for designing physical triggers and temperature controlling experiments. Our study includes extensive experiments conducted in both digital and physical environments. In the digital realm, we evaluate our approach using benchmark datasets for TIOD, achieving an Attack Success Rate (ASR) of up to 98.21%. In the physical realm, we test our approach in two real-world settings: a traffic intersection and a parking lot, using a thermal infrared camera. Here, we attain an ASR of up to 98.38%.
Distributed Graph Embedding with Information-Oriented Random Walks
Mar 28, 2023
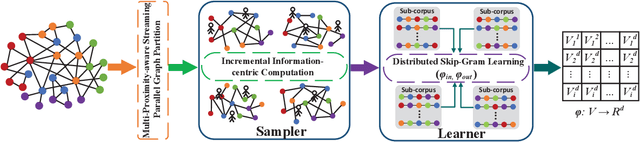
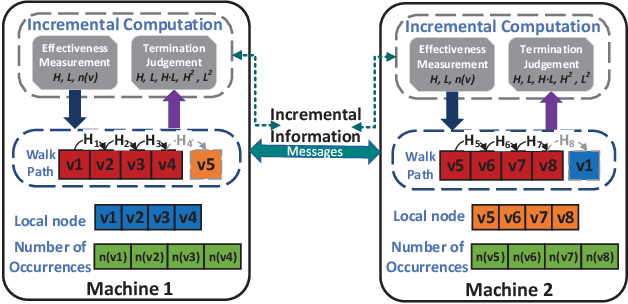
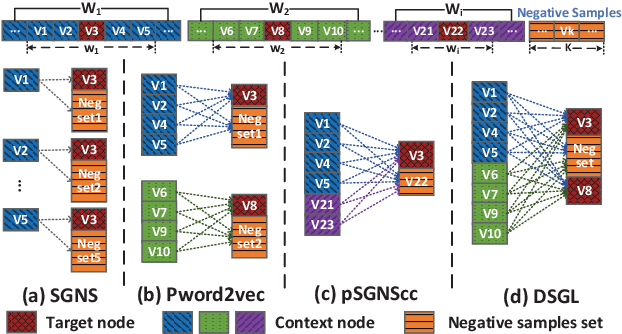
Graph embedding maps graph nodes to low-dimensional vectors, and is widely adopted in machine learning tasks. The increasing availability of billion-edge graphs underscores the importance of learning efficient and effective embeddings on large graphs, such as link prediction on Twitter with over one billion edges. Most existing graph embedding methods fall short of reaching high data scalability. In this paper, we present a general-purpose, distributed, information-centric random walk-based graph embedding framework, DistGER, which can scale to embed billion-edge graphs. DistGER incrementally computes information-centric random walks. It further leverages a multi-proximity-aware, streaming, parallel graph partitioning strategy, simultaneously achieving high local partition quality and excellent workload balancing across machines. DistGER also improves the distributed Skip-Gram learning model to generate node embeddings by optimizing the access locality, CPU throughput, and synchronization efficiency. Experiments on real-world graphs demonstrate that compared to state-of-the-art distributed graph embedding frameworks, including KnightKing, DistDGL, and Pytorch-BigGraph, DistGER exhibits 2.33x-129x acceleration, 45% reduction in cross-machines communication, and > 10% effectiveness improvement in downstream tasks.
Denial-of-Service Attacks on Learned Image Compression
May 26, 2022
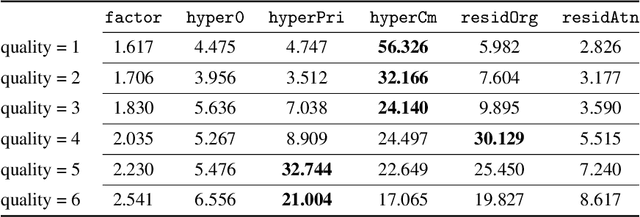
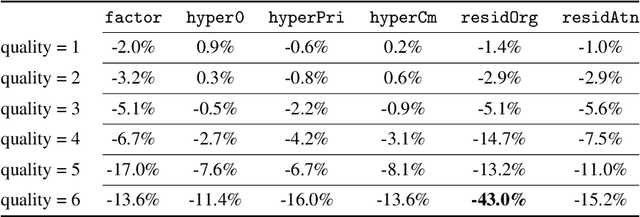

Deep learning techniques have shown promising results in image compression, with competitive bitrate and image reconstruction quality from compressed latent. However, while image compression has progressed towards higher peak signal-to-noise ratio (PSNR) and fewer bits per pixel (bpp), their robustness to corner-case images has never received deliberation. In this work, we, for the first time, investigate the robustness of image compression systems where imperceptible perturbation of input images can precipitate a significant increase in the bitrate of their compressed latent. To characterize the robustness of state-of-the-art learned image compression, we mount white and black-box attacks. Our results on several image compression models with various bitrate qualities show that they are surprisingly fragile, where the white-box attack achieves up to 56.326x and black-box 1.947x bpp change. To improve robustness, we propose a novel model which incorporates attention modules and a basic factorized entropy model, resulting in a promising trade-off between the PSNR/bpp ratio and robustness to adversarial attacks that surpasses existing learned image compressors.
Benchmarking Single Image Dehazing and Beyond
Aug 27, 2018
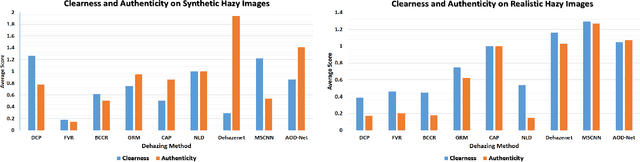


We present a comprehensive study and evaluation of existing single image dehazing algorithms, using a new large-scale benchmark consisting of both synthetic and real-world hazy images, called REalistic Single Image DEhazing (RESIDE). RESIDE highlights diverse data sources and image contents, and is divided into five subsets, each serving different training or evaluation purposes. We further provide a rich variety of criteria for dehazing algorithm evaluation, ranging from full-reference metrics, to no-reference metrics, to subjective evaluation and the novel task-driven evaluation. Experiments on RESIDE shed light on the comparisons and limitations of state-of-the-art dehazing algorithms, and suggest promising future directions.
End-to-End United Video Dehazing and Detection
Sep 12, 2017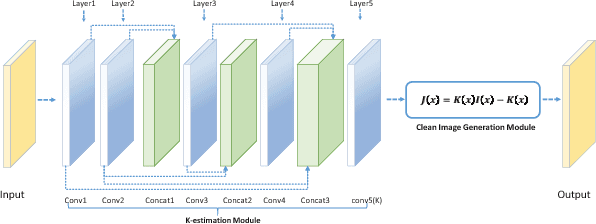
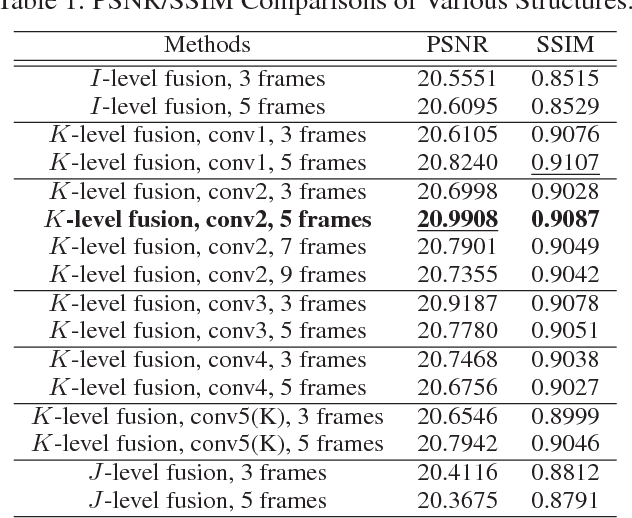
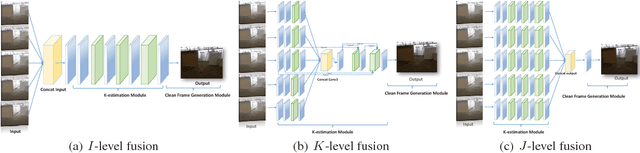
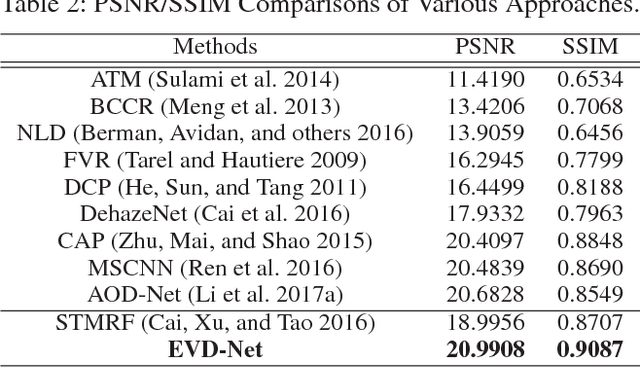
The recent development of CNN-based image dehazing has revealed the effectiveness of end-to-end modeling. However, extending the idea to end-to-end video dehazing has not been explored yet. In this paper, we propose an End-to-End Video Dehazing Network (EVD-Net), to exploit the temporal consistency between consecutive video frames. A thorough study has been conducted over a number of structure options, to identify the best temporal fusion strategy. Furthermore, we build an End-to-End United Video Dehazing and Detection Network(EVDD-Net), which concatenates and jointly trains EVD-Net with a video object detection model. The resulting augmented end-to-end pipeline has demonstrated much more stable and accurate detection results in hazy video.
An All-in-One Network for Dehazing and Beyond
Jul 20, 2017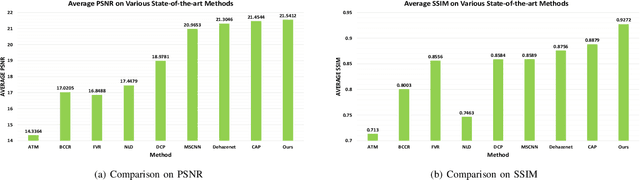
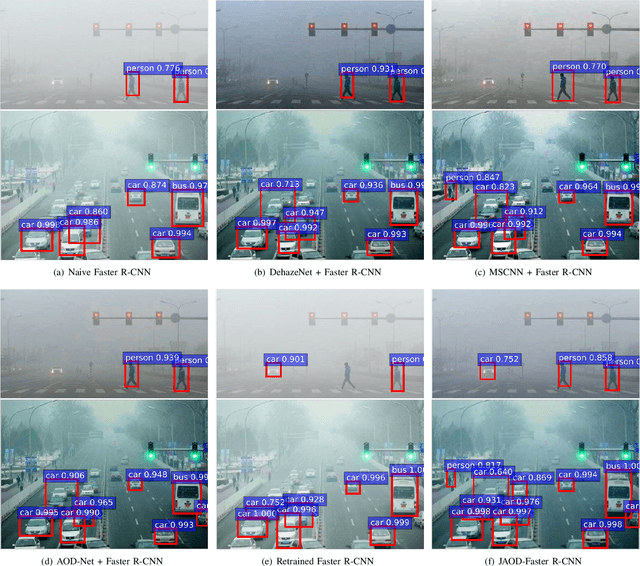
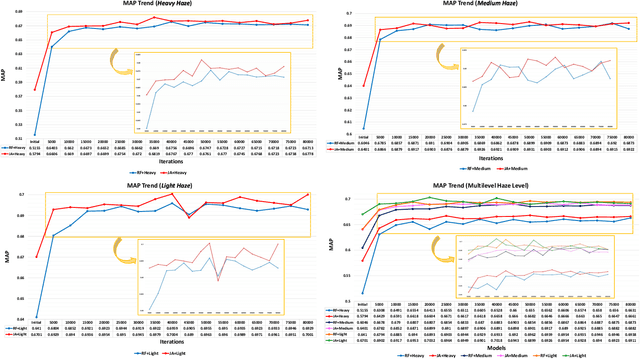
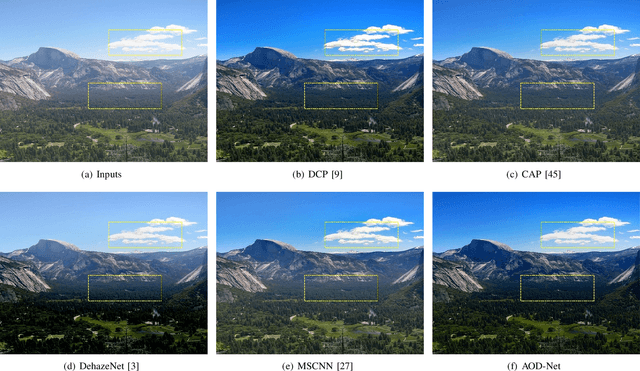
This paper proposes an image dehazing model built with a convolutional neural network (CNN), called All-in-One Dehazing Network (AOD-Net). It is designed based on a re-formulated atmospheric scattering model. Instead of estimating the transmission matrix and the atmospheric light separately as most previous models did, AOD-Net directly generates the clean image through a light-weight CNN. Such a novel end-to-end design makes it easy to embed AOD-Net into other deep models, e.g., Faster R-CNN, for improving high-level task performance on hazy images. Experimental results on both synthesized and natural hazy image datasets demonstrate our superior performance than the state-of-the-art in terms of PSNR, SSIM and the subjective visual quality. Furthermore, when concatenating AOD-Net with Faster R-CNN and training the joint pipeline from end to end, we witness a large improvement of the object detection performance on hazy images.