 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntra Encoding Complexity Control with a Time-Cost Model for Versatile Video Coding
Jun 13, 2022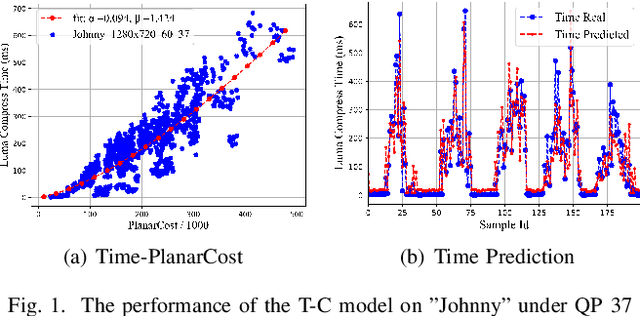
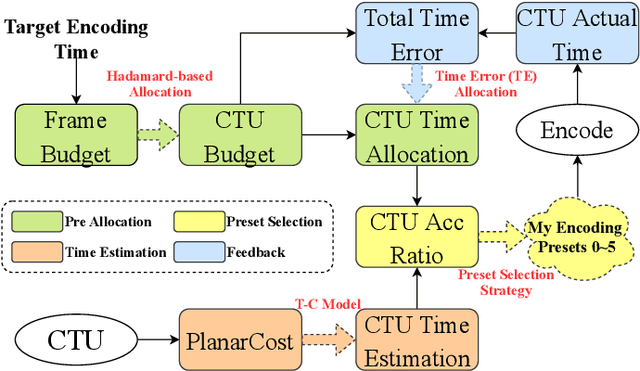
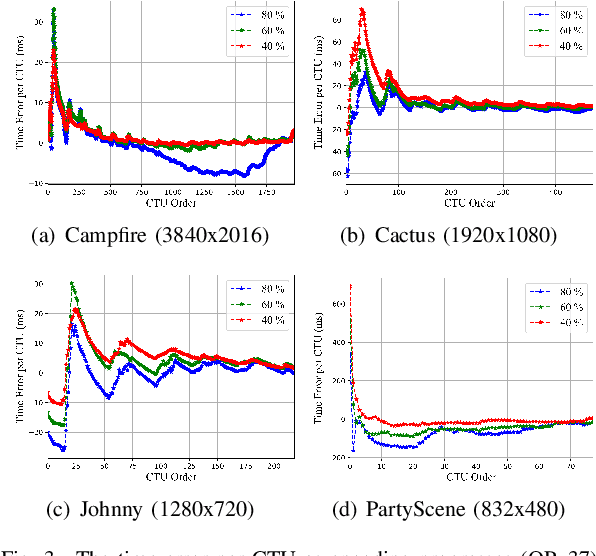
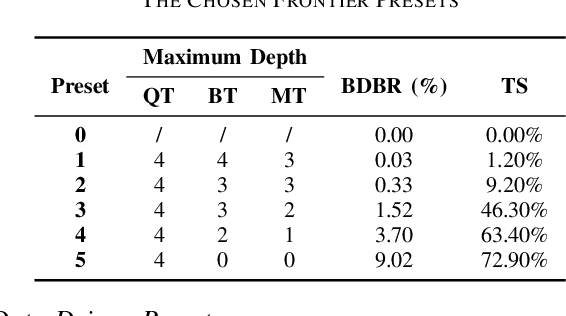
For the latest video coding standard Versatile Video Coding (VVC), the encoding complexity is much higher than previous video coding standards to achieve a better coding efficiency, especially for intra coding. The complexity becomes a major barrier of its deployment and use. Even with many fast encoding algorithms, it is still practically important to control the encoding complexity to a given level. Inspired by rate control algorithms, we propose a scheme to precisely control the intra encoding complexity of VVC. In the proposed scheme, a Time-PlanarCost (viz. Time-Cost, or T-C) model is utilized for CTU encoding time estimation. By combining a set of predefined parameters and the T-C model, CTU-level complexity can be roughly controlled. Then to achieve a precise picture-level complexity control, a framework is constructed including uneven complexity pre-allocation, preset selection and feedback. Experimental results show that, for the challenging intra coding scenario, the complexity error quickly converges to under 3.21%, while keeping a reasonable time saving and rate-distortion (RD) performance. This proves the efficiency of the proposed methods.
Affinity Derivation and Graph Merge for Instance Segmentation
Nov 27, 2018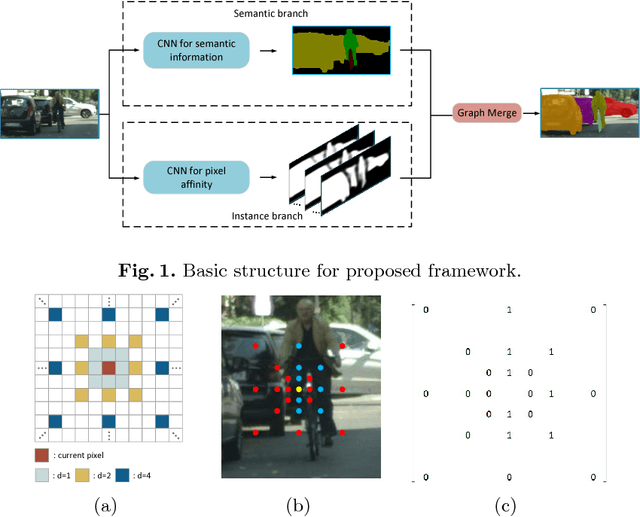
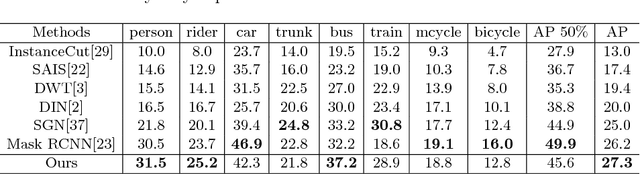
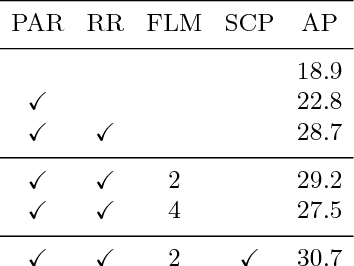
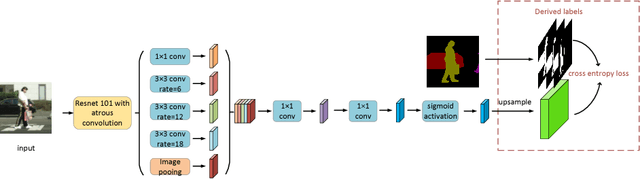
We present an instance segmentation scheme based on pixel affinity information, which is the relationship of two pixels belonging to a same instance. In our scheme, we use two neural networks with similar structure. One is to predict pixel level semantic score and the other is designed to derive pixel affinities. Regarding pixels as the vertexes and affinities as edges, we then propose a simple yet effective graph merge algorithm to cluster pixels into instances. Experimental results show that our scheme can generate fine-grained instance mask. With Cityscapes training data, the proposed scheme achieves 27.3 AP on test set.
Weakly Supervised Local Attention Network for Fine-Grained Visual Classification
Aug 06, 2018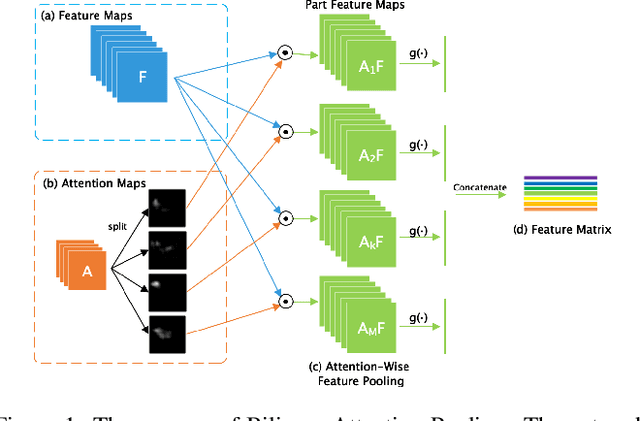
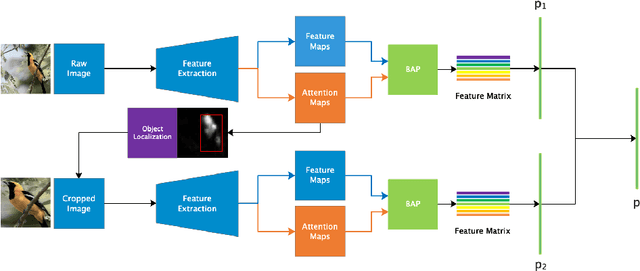

In the fine-grained visual classification task, objects usually share similar geometric structure but present different part distribution and variant local features. Therefore, localizing and extracting discriminative local features play a crucial role in obtaining accurate performance. Existing work that first locates specific several object parts and then extracts further local features either require additional location annotation or needs to train multiple independent networks. In this paper. We propose Weakly Supervised Local Attention Network (WS-LAN) to solve the problem, which jointly generates a great many attention maps (region-of-interest maps) to indicate the location of object parts and extract sequential local features by Local Attention Pooling (LAP). Besides, we adopt attention center loss and attention dropout so that each attention map will focus on a unique object part. WS-LAN can be trained end-to-end and achieves the state-of-the-art performance on multiple fine-grained classification datasets, including CUB-200-2011, Stanford Car and FGVC-Aircraft, which demonstrated its effectiveness.
Facial Landmarks Detection by Self-Iterative Regression based Landmarks-Attention Network
Mar 18, 2018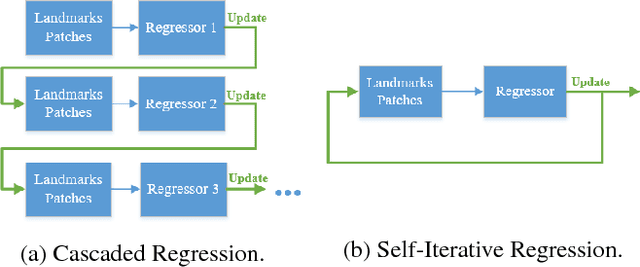
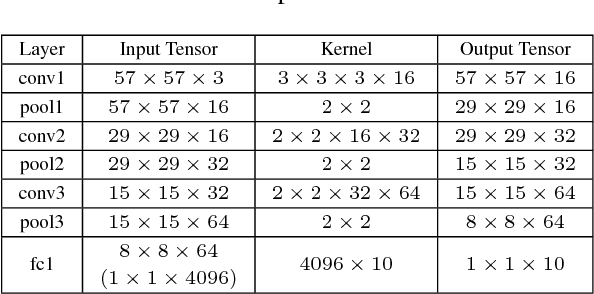
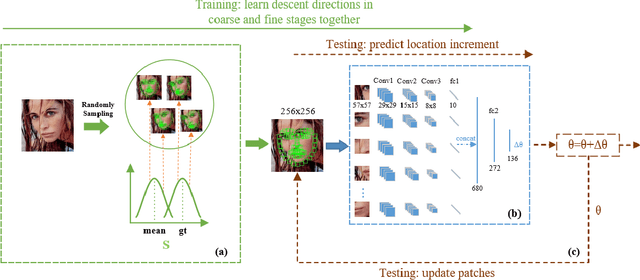
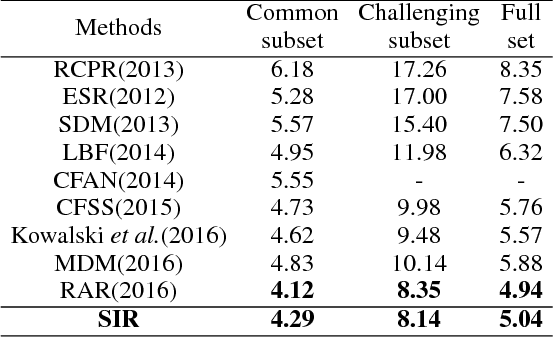
Cascaded Regression (CR) based methods have been proposed to solve facial landmarks detection problem, which learn a series of descent directions by multiple cascaded regressors separately trained in coarse and fine stages. They outperform the traditional gradient descent based methods in both accuracy and running speed. However, cascaded regression is not robust enough because each regressor's training data comes from the output of previous regressor. Moreover, training multiple regressors requires lots of computing resources, especially for deep learning based methods. In this paper, we develop a Self-Iterative Regression (SIR) framework to improve the model efficiency. Only one self-iterative regressor is trained to learn the descent directions for samples from coarse stages to fine stages, and parameters are iteratively updated by the same regressor. Specifically, we proposed Landmarks-Attention Network (LAN) as our regressor, which concurrently learns features around each landmark and obtains the holistic location increment. By doing so, not only the rest of regressors are removed to simplify the training process, but the number of model parameters is significantly decreased. The experiments demonstrate that with only 3.72M model parameters, our proposed method achieves the state-of-the-art performance.
End-to-End United Video Dehazing and Detection
Sep 12, 2017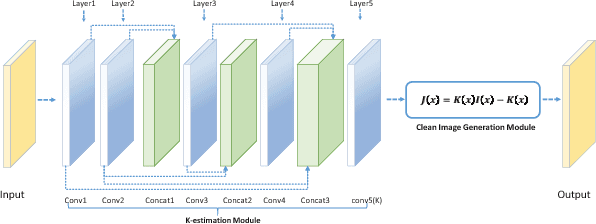
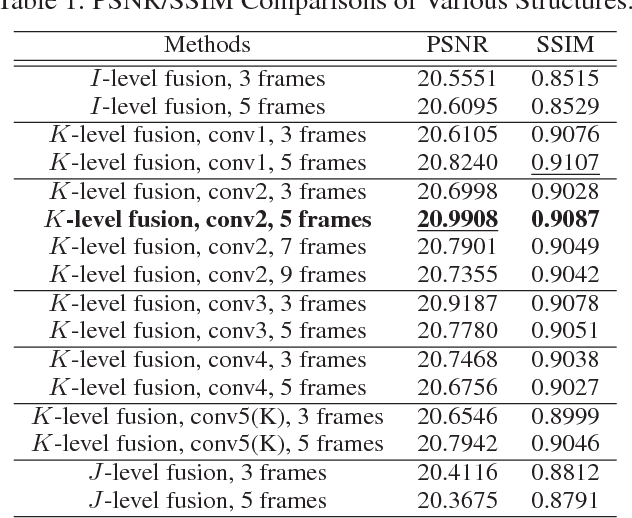
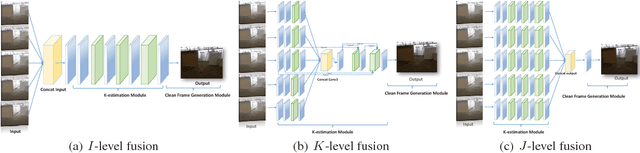
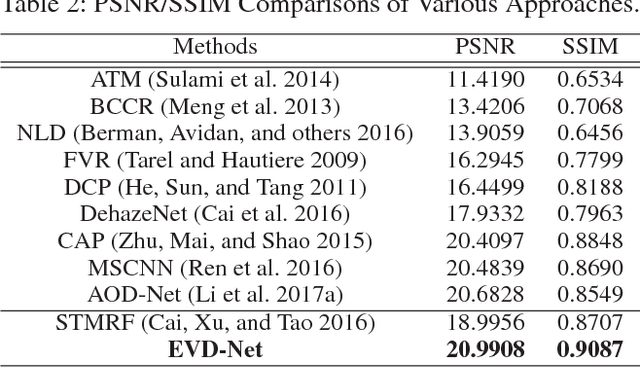
The recent development of CNN-based image dehazing has revealed the effectiveness of end-to-end modeling. However, extending the idea to end-to-end video dehazing has not been explored yet. In this paper, we propose an End-to-End Video Dehazing Network (EVD-Net), to exploit the temporal consistency between consecutive video frames. A thorough study has been conducted over a number of structure options, to identify the best temporal fusion strategy. Furthermore, we build an End-to-End United Video Dehazing and Detection Network(EVDD-Net), which concatenates and jointly trains EVD-Net with a video object detection model. The resulting augmented end-to-end pipeline has demonstrated much more stable and accurate detection results in hazy video.
An All-in-One Network for Dehazing and Beyond
Jul 20, 2017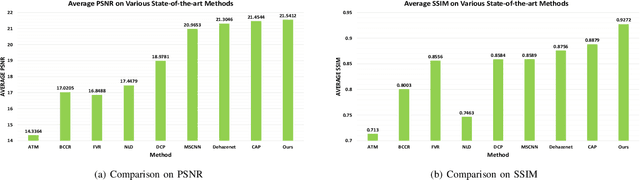
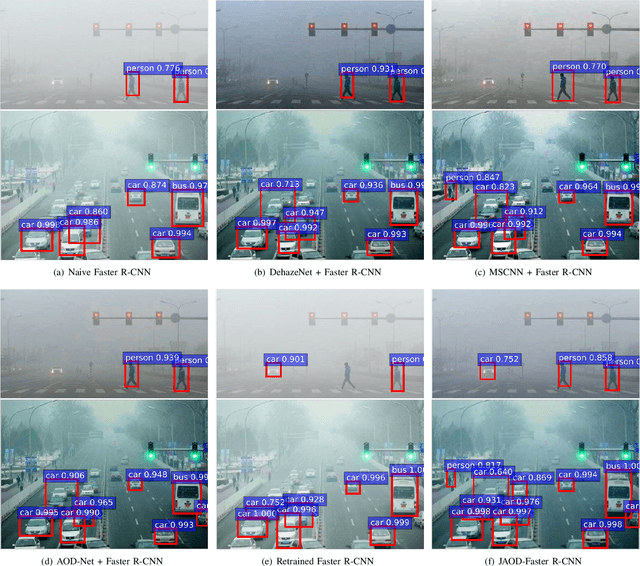
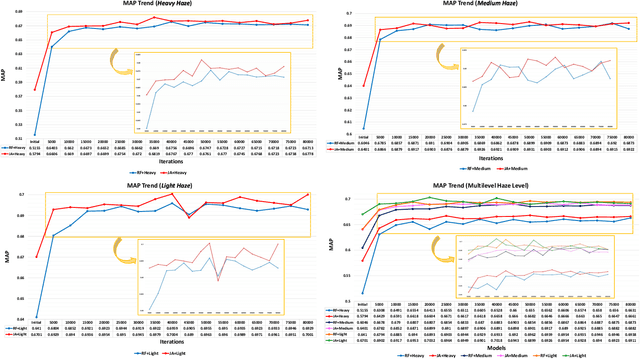
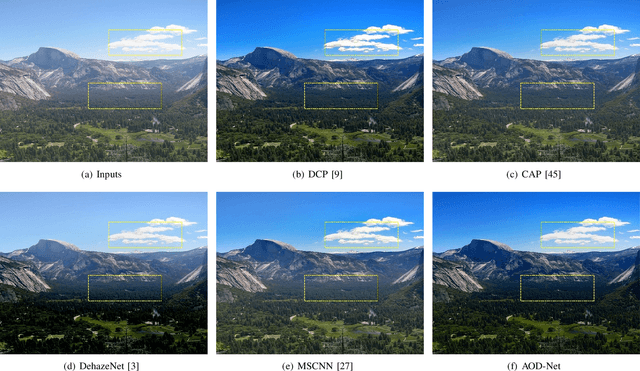
This paper proposes an image dehazing model built with a convolutional neural network (CNN), called All-in-One Dehazing Network (AOD-Net). It is designed based on a re-formulated atmospheric scattering model. Instead of estimating the transmission matrix and the atmospheric light separately as most previous models did, AOD-Net directly generates the clean image through a light-weight CNN. Such a novel end-to-end design makes it easy to embed AOD-Net into other deep models, e.g., Faster R-CNN, for improving high-level task performance on hazy images. Experimental results on both synthesized and natural hazy image datasets demonstrate our superior performance than the state-of-the-art in terms of PSNR, SSIM and the subjective visual quality. Furthermore, when concatenating AOD-Net with Faster R-CNN and training the joint pipeline from end to end, we witness a large improvement of the object detection performance on hazy images.