 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End United Video Dehazing and Detection
Paper and Code
Sep 12, 2017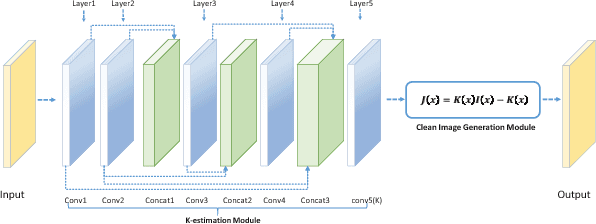
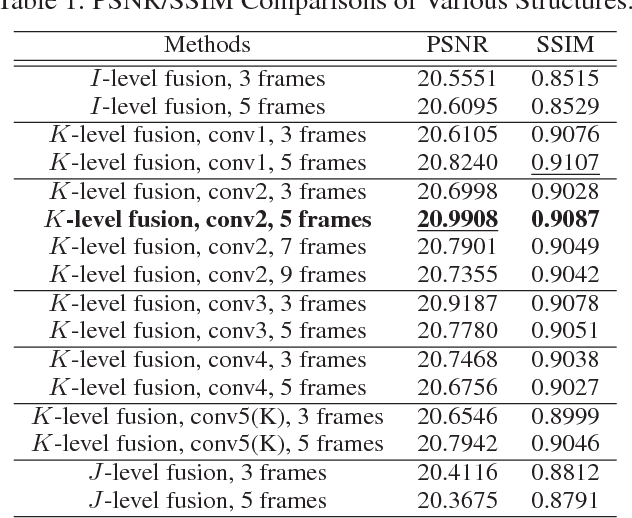
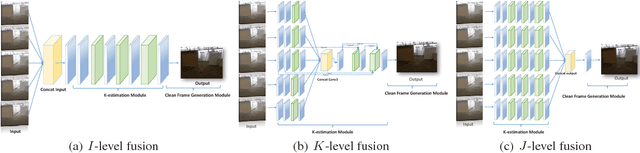
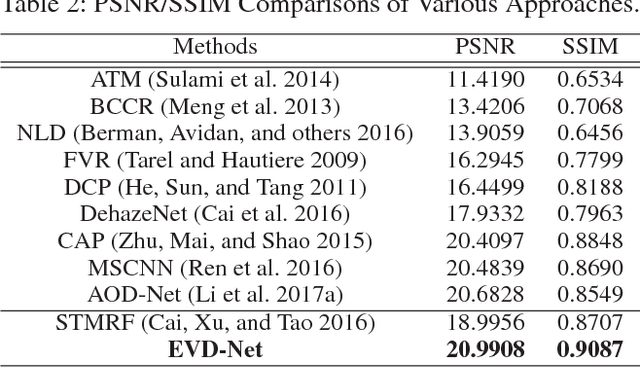
The recent development of CNN-based image dehazing has revealed the effectiveness of end-to-end modeling. However, extending the idea to end-to-end video dehazing has not been explored yet. In this paper, we propose an End-to-End Video Dehazing Network (EVD-Net), to exploit the temporal consistency between consecutive video frames. A thorough study has been conducted over a number of structure options, to identify the best temporal fusion strategy. Furthermore, we build an End-to-End United Video Dehazing and Detection Network(EVDD-Net), which concatenates and jointly trains EVD-Net with a video object detection model. The resulting augmented end-to-end pipeline has demonstrated much more stable and accurate detection results in hazy video.