 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Graph Embedding with Information-Oriented Random Walks
Paper and Code

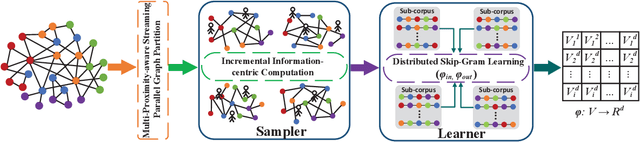
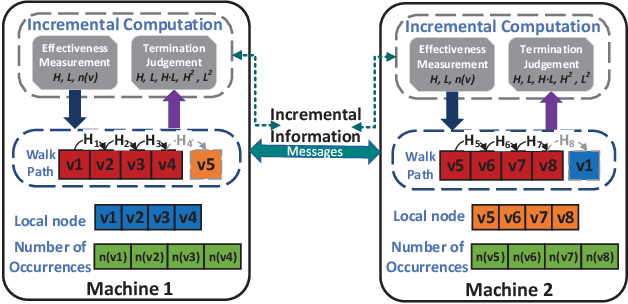
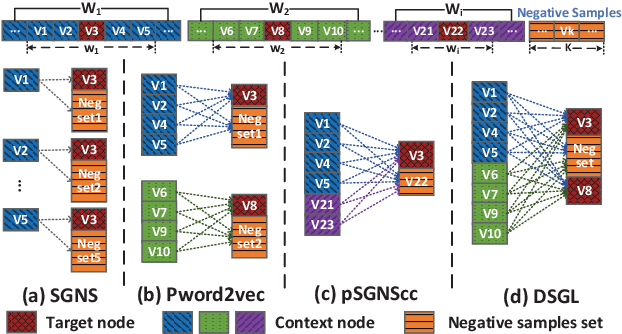
Graph embedding maps graph nodes to low-dimensional vectors, and is widely adopted in machine learning tasks. The increasing availability of billion-edge graphs underscores the importance of learning efficient and effective embeddings on large graphs, such as link prediction on Twitter with over one billion edges. Most existing graph embedding methods fall short of reaching high data scalability. In this paper, we present a general-purpose, distributed, information-centric random walk-based graph embedding framework, DistGER, which can scale to embed billion-edge graphs. DistGER incrementally computes information-centric random walks. It further leverages a multi-proximity-aware, streaming, parallel graph partitioning strategy, simultaneously achieving high local partition quality and excellent workload balancing across machines. DistGER also improves the distributed Skip-Gram learning model to generate node embeddings by optimizing the access locality, CPU throughput, and synchronization efficiency. Experiments on real-world graphs demonstrate that compared to state-of-the-art distributed graph embedding frameworks, including KnightKing, DistDGL, and Pytorch-BigGraph, DistGER exhibits 2.33x-129x acceleration, 45% reduction in cross-machines communication, and > 10% effectiveness improvement in downstream tasks.