 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModality-free Graph In-context Alignment
Mar 13, 2026In-context learning (ICL) converts static encoders into task-conditioned reasoners, enabling adaptation to new data from just a few examples without updating pretrained parameters. This capability is essential for graph foundation models (GFMs) to approach LLM-level generality. Yet current GFMs struggle with cross-domain alignment, typically relying on modality-specific encoders that fail when graphs are pre-vectorized or raw data is inaccessible. In this paper, we introduce Modality-Free Graph In-context Alignment (MF-GIA), a framework that makes a pretrained graph encoder promptable for few-shot prediction across heterogeneous domains without modality assumptions. MF-GIA captures domain characteristics through gradient fingerprints, which parameterize lightweight transformations that align pre-encoded features and indexed labels into unified semantic spaces. During pretraining, a dual prompt-aware attention mechanism with episodic objective learns to match queries against aligned support examples to establish prompt-based reasoning capabilities. At inference, MF-GIA performs parameter-update-free adaptation using only a few-shot support set to trigger cross-domain alignment and enable immediate prediction on unseen domains. Experiments demonstrate that MF-GIA achieves superior few-shot performance across diverse graph domains and strong generalization to unseen domains.
Coden: Efficient Temporal Graph Neural Networks for Continuous Prediction
Feb 13, 2026Temporal Graph Neural Networks (TGNNs) are pivotal in processing dynamic graphs. However, existing TGNNs primarily target one-time predictions for a given temporal span, whereas many practical applications require continuous predictions, that predictions are issued frequently over time. Directly adapting existing TGNNs to continuous-prediction scenarios introduces either significant computational overhead or prediction quality issues especially for large graphs. This paper revisits the challenge of { continuous predictions} in TGNNs, and introduces {\sc Coden}, a TGNN model designed for efficient and effective learning on dynamic graphs. {\sc Coden} innovatively overcomes the key complexity bottleneck in existing TGNNs while preserving comparable predictive accuracy. Moreover, we further provide theoretical analyses that substantiate the effectiveness and efficiency of {\sc Coden}, and clarify its duality relationship with both RNN-based and attention-based models. Our evaluations across five dynamic datasets show that {\sc Coden} surpasses existing performance benchmarks in both efficiency and effectiveness, establishing it as a superior solution for continuous prediction in evolving graph environments.
MoSE: Unveiling Structural Patterns in Graphs via Mixture of Subgraph Experts
Sep 11, 2025While graph neural networks (GNNs) have achieved great success in learning from graph-structured data, their reliance on local, pairwise message passing restricts their ability to capture complex, high-order subgraph patterns. leading to insufficient structural expressiveness. Recent efforts have attempted to enhance structural expressiveness by integrating random walk kernels into GNNs. However, these methods are inherently designed for graph-level tasks, which limits their applicability to other downstream tasks such as node classification. Moreover, their fixed kernel configurations hinder the model's flexibility in capturing diverse subgraph structures. To address these limitations, this paper proposes a novel Mixture of Subgraph Experts (MoSE) framework for flexible and expressive subgraph-based representation learning across diverse graph tasks. Specifically, MoSE extracts informative subgraphs via anonymous walks and dynamically routes them to specialized experts based on structural semantics, enabling the model to capture diverse subgraph patterns with improved flexibility and interpretability. We further provide a theoretical analysis of MoSE's expressivity within the Subgraph Weisfeiler-Lehman (SWL) Test, proving that it is more powerful than SWL. Extensive experiments, together with visualizations of learned subgraph experts, demonstrate that MoSE not only outperforms competitive baselines but also provides interpretable insights into structural patterns learned by the model.
When Deepfake Detection Meets Graph Neural Network:a Unified and Lightweight Learning Framework
Aug 07, 2025The proliferation of generative video models has made detecting AI-generated and manipulated videos an urgent challenge. Existing detection approaches often fail to generalize across diverse manipulation types due to their reliance on isolated spatial, temporal, or spectral information, and typically require large models to perform well. This paper introduces SSTGNN, a lightweight Spatial-Spectral-Temporal Graph Neural Network framework that represents videos as structured graphs, enabling joint reasoning over spatial inconsistencies, temporal artifacts, and spectral distortions. SSTGNN incorporates learnable spectral filters and temporal differential modeling into a graph-based architecture, capturing subtle manipulation traces more effectively. Extensive experiments on diverse benchmark datasets demonstrate that SSTGNN not only achieves superior performance in both in-domain and cross-domain settings, but also offers strong robustness against unseen manipulations. Remarkably, SSTGNN accomplishes these results with up to 42.4$\times$ fewer parameters than state-of-the-art models, making it highly lightweight and scalable for real-world deployment.
DHIL-GT: Scalable Graph Transformer with Decoupled Hierarchy Labeling
Dec 06, 2024



Graph Transformer (GT) has recently emerged as a promising neural network architecture for learning graph-structured data. However, its global attention mechanism with quadratic complexity concerning the graph scale prevents wider application to large graphs. While current methods attempt to enhance GT scalability by altering model architecture or encoding hierarchical graph data, our analysis reveals that these models still suffer from the computational bottleneck related to graph-scale operations. In this work, we target the GT scalability issue and propose DHIL-GT, a scalable Graph Transformer that simplifies network learning by fully decoupling the graph computation to a separate stage in advance. DHIL-GT effectively retrieves hierarchical information by exploiting the graph labeling technique, as we show that the graph label hierarchy is more informative than plain adjacency by offering global connections while promoting locality, and is particularly suitable for handling complex graph patterns such as heterophily. We further design subgraph sampling and positional encoding schemes for precomputing model input on top of graph labels in an end-to-end manner. The training stage thus favorably removes graph-related computations, leading to ideal mini-batch capability and GPU utilization. Notably, the precomputation and training processes of DHIL-GT achieve complexities linear to the number of graph edges and nodes, respectively. Extensive experiments demonstrate that DHIL-GT is efficient in terms of computational boost and mini-batch capability over existing scalable Graph Transformer designs on large-scale benchmarks, while achieving top-tier effectiveness on both homophilous and heterophilous graphs.
Towards Graph Foundation Models: The Perspective of Zero-shot Reasoning on Knowledge Graphs
Oct 16, 2024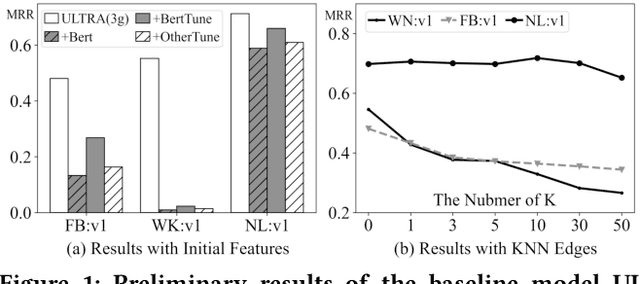
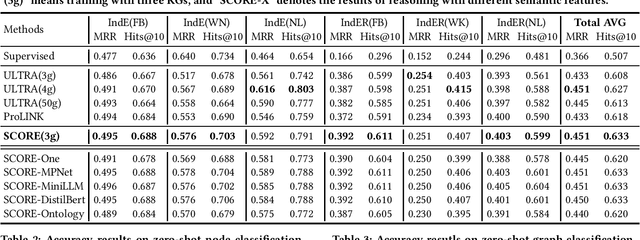
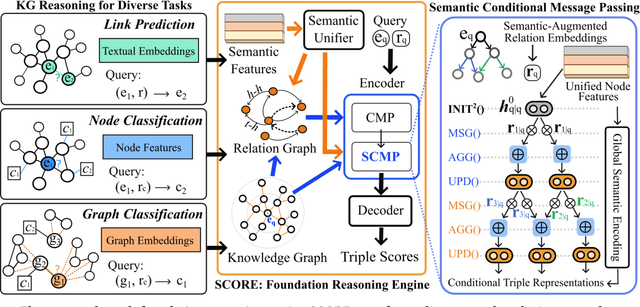
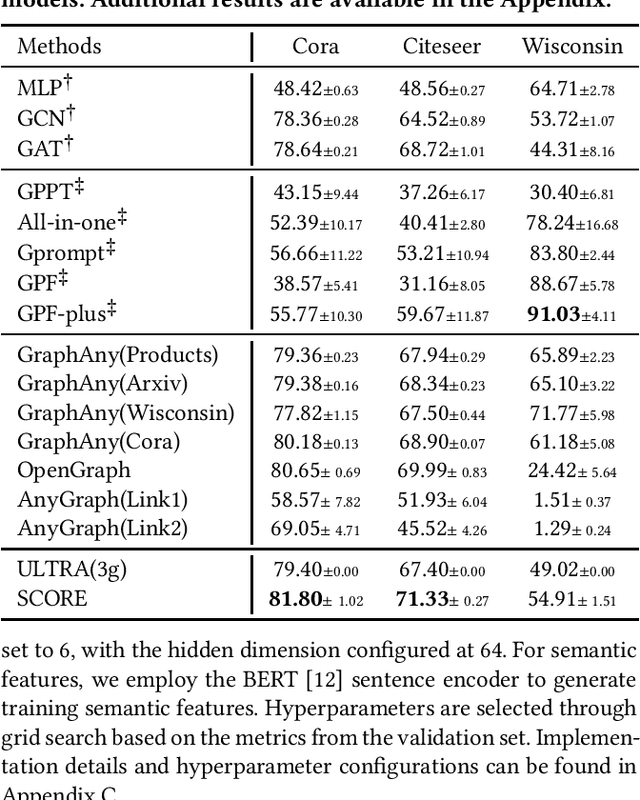
Inspired by the success of artificial general intelligence, there is a trend towards developing Graph Foundation Models that excel in generalization across various graph tasks and domains. However, current models often require extensive training or fine-tuning to capture structural and semantic insights on new graphs, which limits their versatility. In this work, we explore graph foundation models from the perspective of zero-shot reasoning on Knowledge Graphs (KGs). Our focus is on utilizing KGs as a unified topological structure to tackle diverse tasks, while addressing semantic isolation challenges in KG reasoning to effectively integrate diverse semantic and structural features. This brings us new methodological insights into KG reasoning, as well as high generalizability towards foundation models in practice. Methodologically, we introduce SCORE, a unified graph reasoning framework that effectively generalizes diverse graph tasks using zero-shot learning. At the core of SCORE is semantic conditional message passing, a technique designed to capture both structural and semantic invariances in graphs, with theoretical backing for its expressive power. Practically, we evaluate the zero-shot reasoning capability of SCORE using 38 diverse graph datasets, covering node-level, link-level, and graph-level tasks across multiple domains. Our experiments reveal a substantial performance improvement over prior foundation models and supervised baselines, highlighting the efficacy and adaptability of our approach.
Benchmarking Spectral Graph Neural Networks: A Comprehensive Study on Effectiveness and Efficiency
Jun 14, 2024



With the recent advancements in graph neural networks (GNNs), spectral GNNs have received increasing popularity by virtue of their specialty in capturing graph signals in the frequency domain, demonstrating promising capability in specific tasks. However, few systematic studies have been conducted on assessing their spectral characteristics. This emerging family of models also varies in terms of designs and settings, leading to difficulties in comparing their performance and deciding on the suitable model for specific scenarios, especially for large-scale tasks. In this work, we extensively benchmark spectral GNNs with a focus on the frequency perspective. We analyze and categorize over 30 GNNs with 27 corresponding filters. Then, we implement these spectral models under a unified framework with dedicated graph computations and efficient training schemes. Thorough experiments are conducted on the spectral models with inclusive metrics on effectiveness and efficiency, offering practical guidelines on evaluating and selecting spectral GNNs with desirable performance. Our implementation enables application on larger graphs with comparable performance and less overhead, which is available at: https://github.com/gdmnl/Spectral-GNN-Benchmark.
Unifews: Unified Entry-Wise Sparsification for Efficient Graph Neural Network
Mar 20, 2024Graph Neural Networks (GNNs) have shown promising performance in various graph learning tasks, but at the cost of resource-intensive computations. The primary overhead of GNN update stems from graph propagation and weight transformation, both involving operations on graph-scale matrices. Previous studies attempt to reduce the computational budget by leveraging graph-level or network-level sparsification techniques, resulting in downsized graph or weights. In this work, we propose Unifews, which unifies the two operations in an entry-wise manner considering individual matrix elements, and conducts joint edge-weight sparsification to enhance learning efficiency. The entry-wise design of Unifews enables adaptive compression across GNN layers with progressively increased sparsity, and is applicable to a variety of architectural designs with on-the-fly operation simplification. Theoretically, we establish a novel framework to characterize sparsified GNN learning in view of a graph optimization process, and prove that Unifews effectively approximates the learning objective with bounded error and reduced computational load. We conduct extensive experiments to evaluate the performance of our method in diverse settings. Unifews is advantageous in jointly removing more than 90% of edges and weight entries with comparable or better accuracy than baseline models. The sparsification offers remarkable efficiency improvements including 10-20x matrix operation reduction and up to 100x acceleration in graph propagation time for the largest graph at the billion-edge scale.
LLM as Prompter: Low-resource Inductive Reasoning on Arbitrary Knowledge Graphs
Feb 19, 2024
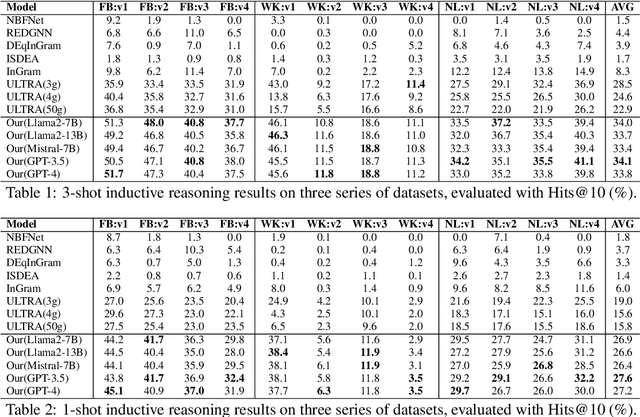


Knowledge Graph (KG) inductive reasoning, which aims to infer missing facts from new KGs that are not seen during training, has been widely adopted in various applications. One critical challenge of KG inductive reasoning is handling low-resource scenarios with scarcity in both textual and structural aspects. In this paper, we attempt to address this challenge with Large Language Models (LLMs). Particularly, we utilize the state-of-the-art LLMs to generate a graph-structural prompt to enhance the pre-trained Graph Neural Networks (GNNs), which brings us new methodological insights into the KG inductive reasoning methods, as well as high generalizability in practice. On the methodological side, we introduce a novel pretraining and prompting framework ProLINK, designed for low-resource inductive reasoning across arbitrary KGs without requiring additional training. On the practical side, we experimentally evaluate our approach on 36 low-resource KG datasets and find that ProLINK outperforms previous methods in three-shot, one-shot, and zero-shot reasoning tasks, exhibiting average performance improvements by 20%, 45%, and 147%, respectively. Furthermore, ProLINK demonstrates strong robustness for various LLM promptings as well as full-shot scenarios.
Learning from Graphs with Heterophily: Progress and Future
Feb 01, 2024Graphs are structured data that models complex relations between real-world entities. Heterophilous graphs, where linked nodes are prone to be with different labels or dissimilar features, have recently attracted significant attention and found many applications. Meanwhile, increasing efforts have been made to advance learning from heterophilous graphs. Although there exist surveys on the relevant topic, they focus on heterophilous GNNs, which are only sub-topics of heterophilous graph learning. In this survey, we comprehensively overview existing works on learning from graphs with heterophily.First, we collect over 180 publications and introduce the development of this field. Then, we systematically categorize existing methods based on a hierarchical taxonomy including learning strategies, model architectures and practical applications. Finally, we discuss the primary challenges of existing studies and highlight promising avenues for future research.More publication details and corresponding open-source codes can be accessed and will be continuously updated at our repositories:https://github.com/gongchenghua/Awesome-Survey-Graphs-with-Heterophily.