 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Optimize LSM-trees: Towards A Reinforcement Learning based Key-Value Store for Dynamic Workloads
Aug 14, 2023



LSM-trees are widely adopted as the storage backend of key-value stores. However, optimizing the system performance under dynamic workloads has not been sufficiently studied or evaluated in previous work. To fill the gap, we present RusKey, a key-value store with the following new features: (1) RusKey is a first attempt to orchestrate LSM-tree structures online to enable robust performance under the context of dynamic workloads; (2) RusKey is the first study to use Reinforcement Learning (RL) to guide LSM-tree transformations; (3) RusKey includes a new LSM-tree design, named FLSM-tree, for an efficient transition between different compaction policies -- the bottleneck of dynamic key-value stores. We justify the superiority of the new design with theoretical analysis; (4) RusKey requires no prior workload knowledge for system adjustment, in contrast to state-of-the-art techniques. Experiments show that RusKey exhibits strong performance robustness in diverse workloads, achieving up to 4x better end-to-end performance than the RocksDB system under various settings.
SCARA: Scalable Graph Neural Networks with Feature-Oriented Optimization
Jul 19, 2022
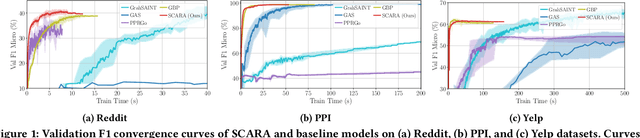


Recent advances in data processing have stimulated the demand for learning graphs of very large scales. Graph Neural Networks (GNNs), being an emerging and powerful approach in solving graph learning tasks, are known to be difficult to scale up. Most scalable models apply node-based techniques in simplifying the expensive graph message-passing propagation procedure of GNN. However, we find such acceleration insufficient when applied to million- or even billion-scale graphs. In this work, we propose SCARA, a scalable GNN with feature-oriented optimization for graph computation. SCARA efficiently computes graph embedding from node features, and further selects and reuses feature computation results to reduce overhead. Theoretical analysis indicates that our model achieves sub-linear time complexity with a guaranteed precision in propagation process as well as GNN training and inference. We conduct extensive experiments on various datasets to evaluate the efficacy and efficiency of SCARA. Performance comparison with baselines shows that SCARA can reach up to 100x graph propagation acceleration than current state-of-the-art methods with fast convergence and comparable accuracy. Most notably, it is efficient to process precomputation on the largest available billion-scale GNN dataset Papers100M (111M nodes, 1.6B edges) in 100 seconds.