 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoden: Efficient Temporal Graph Neural Networks for Continuous Prediction
Feb 13, 2026Temporal Graph Neural Networks (TGNNs) are pivotal in processing dynamic graphs. However, existing TGNNs primarily target one-time predictions for a given temporal span, whereas many practical applications require continuous predictions, that predictions are issued frequently over time. Directly adapting existing TGNNs to continuous-prediction scenarios introduces either significant computational overhead or prediction quality issues especially for large graphs. This paper revisits the challenge of { continuous predictions} in TGNNs, and introduces {\sc Coden}, a TGNN model designed for efficient and effective learning on dynamic graphs. {\sc Coden} innovatively overcomes the key complexity bottleneck in existing TGNNs while preserving comparable predictive accuracy. Moreover, we further provide theoretical analyses that substantiate the effectiveness and efficiency of {\sc Coden}, and clarify its duality relationship with both RNN-based and attention-based models. Our evaluations across five dynamic datasets show that {\sc Coden} surpasses existing performance benchmarks in both efficiency and effectiveness, establishing it as a superior solution for continuous prediction in evolving graph environments.
Revisiting and Benchmarking Graph Autoencoders: A Contrastive Learning Perspective
Oct 14, 2024



Graph autoencoders (GAEs) are self-supervised learning models that can learn meaningful representations of graph-structured data by reconstructing the input graph from a low-dimensional latent space. Over the past few years, GAEs have gained significant attention in academia and industry. In particular, the recent advent of GAEs with masked autoencoding schemes marks a significant advancement in graph self-supervised learning research. While numerous GAEs have been proposed, the underlying mechanisms of GAEs are not well understood, and a comprehensive benchmark for GAEs is still lacking. In this work, we bridge the gap between GAEs and contrastive learning by establishing conceptual and methodological connections. We revisit the GAEs studied in previous works and demonstrate how contrastive learning principles can be applied to GAEs. Motivated by these insights, we introduce lrGAE (left-right GAE), a general and powerful GAE framework that leverages contrastive learning principles to learn meaningful representations. Our proposed lrGAE not only facilitates a deeper understanding of GAEs but also sets a new benchmark for GAEs across diverse graph-based learning tasks. The source code for lrGAE, including the baselines and all the code for reproducing the results, is publicly available at https://github.com/EdisonLeeeee/lrGAE.
Benchmarking Spectral Graph Neural Networks: A Comprehensive Study on Effectiveness and Efficiency
Jun 14, 2024



With the recent advancements in graph neural networks (GNNs), spectral GNNs have received increasing popularity by virtue of their specialty in capturing graph signals in the frequency domain, demonstrating promising capability in specific tasks. However, few systematic studies have been conducted on assessing their spectral characteristics. This emerging family of models also varies in terms of designs and settings, leading to difficulties in comparing their performance and deciding on the suitable model for specific scenarios, especially for large-scale tasks. In this work, we extensively benchmark spectral GNNs with a focus on the frequency perspective. We analyze and categorize over 30 GNNs with 27 corresponding filters. Then, we implement these spectral models under a unified framework with dedicated graph computations and efficient training schemes. Thorough experiments are conducted on the spectral models with inclusive metrics on effectiveness and efficiency, offering practical guidelines on evaluating and selecting spectral GNNs with desirable performance. Our implementation enables application on larger graphs with comparable performance and less overhead, which is available at: https://github.com/gdmnl/Spectral-GNN-Benchmark.
A Graph is Worth 1-bit Spikes: When Graph Contrastive Learning Meets Spiking Neural Networks
May 30, 2023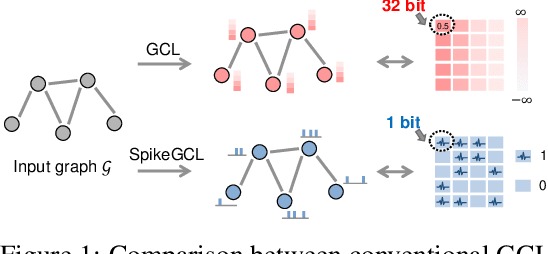

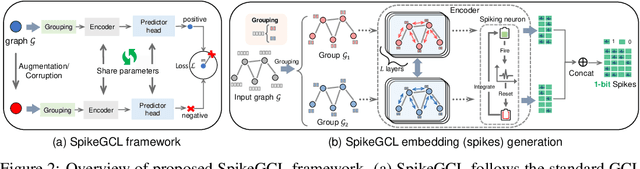
While contrastive self-supervised learning has become the de-facto learning paradigm for graph neural networks, the pursuit of high task accuracy requires a large hidden dimensionality to learn informative and discriminative full-precision representations, raising concerns about computation, memory footprint, and energy consumption burden (largely overlooked) for real-world applications. This paper explores a promising direction for graph contrastive learning (GCL) with spiking neural networks (SNNs), which leverage sparse and binary characteristics to learn more biologically plausible and compact representations. We propose SpikeGCL, a novel GCL framework to learn binarized 1-bit representations for graphs, making balanced trade-offs between efficiency and performance. We provide theoretical guarantees to demonstrate that SpikeGCL has comparable expressiveness with its full-precision counterparts. Experimental results demonstrate that, with nearly 32x representation storage compression, SpikeGCL is either comparable to or outperforms many fancy state-of-the-art supervised and self-supervised methods across several graph benchmarks.
Scaling Up Dynamic Graph Representation Learning via Spiking Neural Networks
Aug 15, 2022
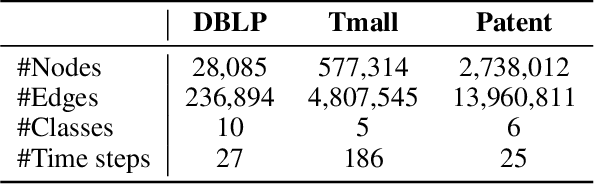
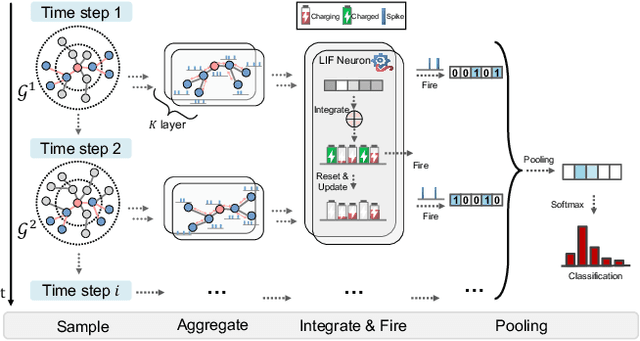
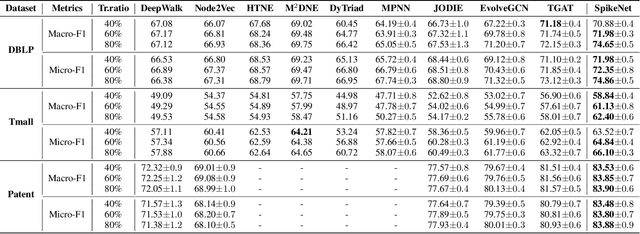
Recent years have seen a surge in research on dynamic graph representation learning, which aims to model temporal graphs that are dynamic and evolving constantly over time. However, current work typically models graph dynamics with recurrent neural networks (RNNs), making them suffer seriously from computation and memory overheads on large temporal graphs. So far, scalability of dynamic graph representation learning on large temporal graphs remains one of the major challenges. In this paper, we present a scalable framework, namely SpikeNet, to efficiently capture the temporal and structural patterns of temporal graphs. We explore a new direction in that we can capture the evolving dynamics of temporal graphs with spiking neural networks (SNNs) instead of RNNs. As a low-power alternative to RNNs, SNNs explicitly model graph dynamics as spike trains of neuron populations and enable spike-based propagation in an efficient way. Experiments on three large real-world temporal graph datasets demonstrate that SpikeNet outperforms strong baselines on the temporal node classification task with lower computational costs. Particularly, SpikeNet generalizes to a large temporal graph (2M nodes and 13M edges) with significantly fewer parameters and computation overheads. Our code is publicly available at https://github.com/EdisonLeeeee/SpikeNet
Spiking Graph Convolutional Networks
May 05, 2022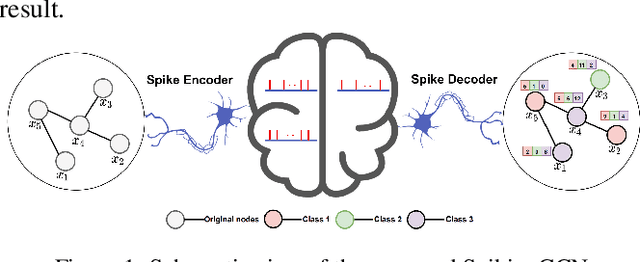

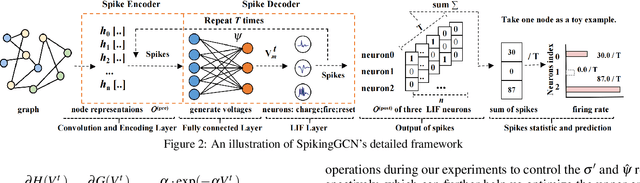
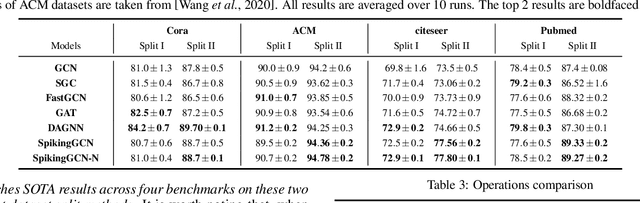
Graph Convolutional Networks (GCNs) achieve an impressive performance due to the remarkable representation ability in learning the graph information. However, GCNs, when implemented on a deep network, require expensive computation power, making them difficult to be deployed on battery-powered devices. In contrast, Spiking Neural Networks (SNNs), which perform a bio-fidelity inference process, offer an energy-efficient neural architecture. In this work, we propose SpikingGCN, an end-to-end framework that aims to integrate the embedding of GCNs with the biofidelity characteristics of SNNs. The original graph data are encoded into spike trains based on the incorporation of graph convolution. We further model biological information processing by utilizing a fully connected layer combined with neuron nodes. In a wide range of scenarios (e.g. citation networks, image graph classification, and recommender systems), our experimental results show that the proposed method could gain competitive performance against state-of-the-art approaches. Furthermore, we show that SpikingGCN on a neuromorphic chip can bring a clear advantage of energy efficiency into graph data analysis, which demonstrates its great potential to construct environment-friendly machine learning models.
FastGCL: Fast Self-Supervised Learning on Graphs via Contrastive Neighborhood Aggregation
May 02, 2022

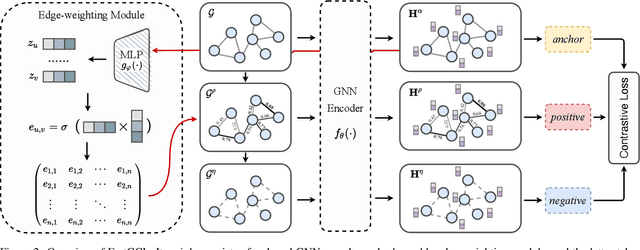
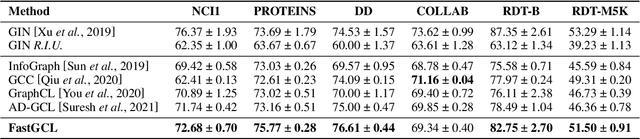
Graph contrastive learning (GCL), as a popular approach to graph self-supervised learning, has recently achieved a non-negligible effect. To achieve superior performance, the majority of existing GCL methods elaborate on graph data augmentation to construct appropriate contrastive pairs. However, existing methods place more emphasis on the complex graph data augmentation which requires extra time overhead, and pay less attention to developing contrastive schemes specific to encoder characteristics. We argue that a better contrastive scheme should be tailored to the characteristics of graph neural networks (e.g., neighborhood aggregation) and propose a simple yet effective method named FastGCL. Specifically, by constructing weighted-aggregated and non-aggregated neighborhood information as positive and negative samples respectively, FastGCL identifies the potential semantic information of data without disturbing the graph topology and node attributes, resulting in faster training and convergence speeds. Extensive experiments have been conducted on node classification and graph classification tasks, showing that FastGCL has competitive classification performance and significant training speedup compared to existing state-of-the-art methods.